Java to extract PDF text content
In your daily work, you may need to extract the textual content contained in a huge PDF document. And Free Spire.PDF for Java provides a convenient and fast way to extract text, then introduce the Java code used in the process.
** Basic steps: ** ** 1. ** Free Spire.PDF for Java Download and unzip the package. ** 2. ** Import the Spire.Pdf.jar package in the lib folder as a dependency into your Java application or install the JAR package from the Maven repository (see below for the code that makes up the pom.xml file) please). ** 3. ** In your Java application, create a new Java Class (named ExtractText here) and enter and execute the corresponding Java code.
** Configure the pom.xml file: **
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
<version>2.6.3</version>
</dependency>
</dependencies>
** The PDF source document is: **
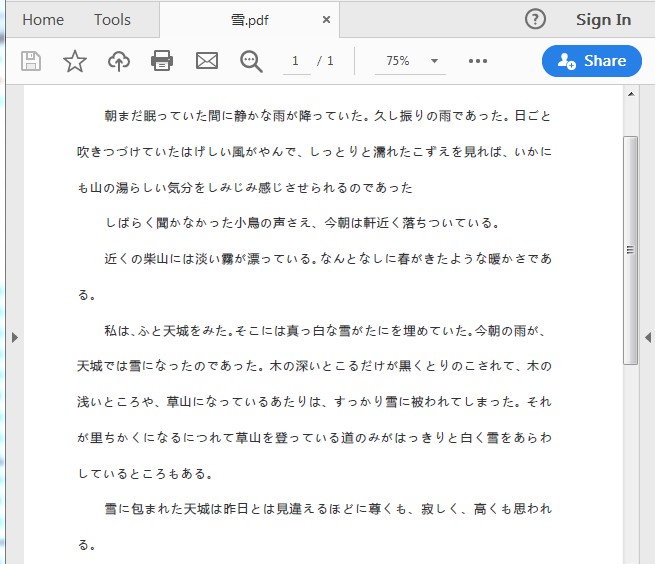
** Java code: **
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import java.io.*;
public class ExtractText {
public static void main(String[] args) {
//Create a PdfDocument instance
PdfDocument doc = new PdfDocument();
//Load PDF file
doc.loadFromFile("snow.pdf");
//Create a StringBuilder instance
StringBuilder sb = new StringBuilder();
PdfPageBase page;
//Traverse the PDF pages, get the text for each page and add it to the StringBuilder object
for(int i= 0;i<doc.getPages().getCount();i++){
page = doc.getPages().get(i);
sb.append(page.extractText(true));
}
FileWriter writer;
try {
//Writes the text of a StringBuilder object to a text file
writer = new FileWriter("ExtractText.txt");
writer.write(sb.toString());
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
doc.close();
}
}
** Extract results: **
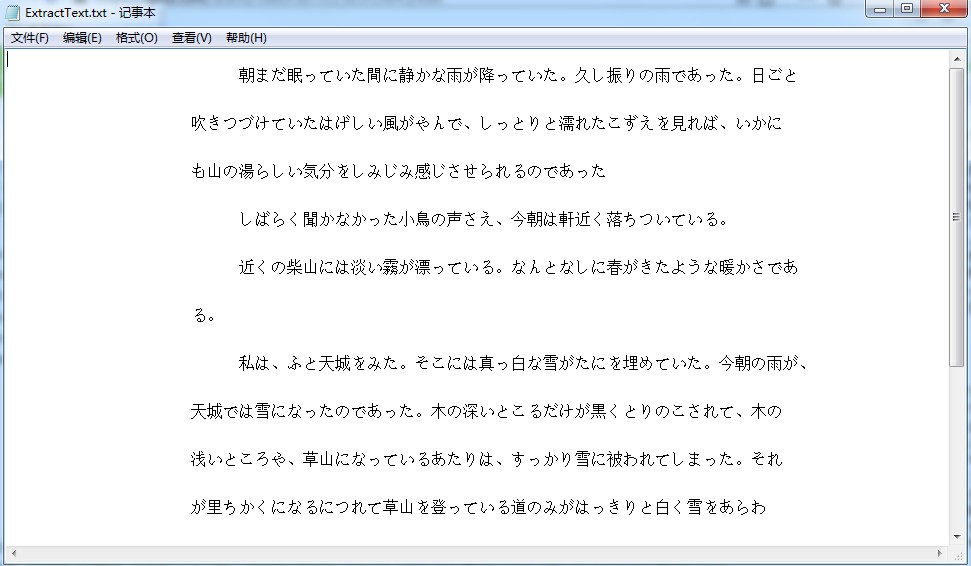
Recommended Posts