Java zum Extrahieren von PDF-Textinhalten
Bei Ihrer täglichen Arbeit müssen Sie möglicherweise den in einem großen PDF-Dokument enthaltenen Textinhalt extrahieren. Und Free Spire.PDF für Java bietet eine bequeme und schnelle Möglichkeit, Text zu extrahieren, gefolgt von dem dabei verwendeten Java-Code.
** Grundlagen: ** ** 1. ** Free Spire.PDF für Java Laden Sie das Paket herunter und entpacken Sie es. ** 2. ** Importieren Sie das Spire.Pdf.jar-Paket aus dem lib-Ordner als Abhängigkeit in Ihre Java-Anwendung oder installieren Sie das JAR-Paket aus dem Maven-Repository (siehe unten für den Code, aus dem die Datei pom.xml besteht). Bitte). ** 3. ** Erstellen Sie in Ihrer Java-Anwendung eine neue Java-Klasse (hier ExtractText genannt) und geben Sie den entsprechenden Java-Code ein und führen Sie ihn aus.
** Konfigurieren Sie die Datei pom.xml: **
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
<version>2.6.3</version>
</dependency>
</dependencies>
** Das PDF-Quelldokument lautet: **
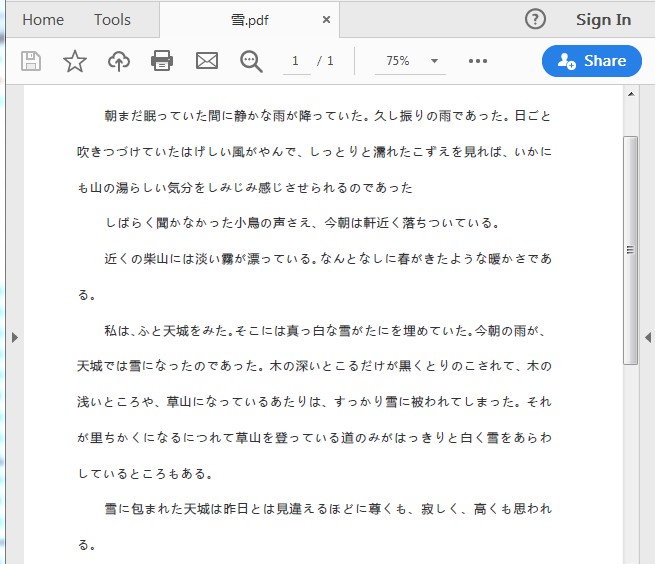
** Java-Code: **
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import java.io.*;
public class ExtractText {
public static void main(String[] args) {
//Erstellen Sie eine PdfDocument-Instanz
PdfDocument doc = new PdfDocument();
//Laden Sie die PDF-Datei
doc.loadFromFile("Schnee.pdf");
//Erstellen Sie eine StringBuilder-Instanz
StringBuilder sb = new StringBuilder();
PdfPageBase page;
//Durchlaufen Sie die PDF-Seiten, rufen Sie den Text für jede Seite ab und fügen Sie ihn dem StringBuilder-Objekt hinzu
for(int i= 0;i<doc.getPages().getCount();i++){
page = doc.getPages().get(i);
sb.append(page.extractText(true));
}
FileWriter writer;
try {
//Schreibt den Text eines StringBuilder-Objekts in eine Textdatei
writer = new FileWriter("ExtractText.txt");
writer.write(sb.toString());
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
doc.close();
}
}
** Ergebnisse extrahieren: **
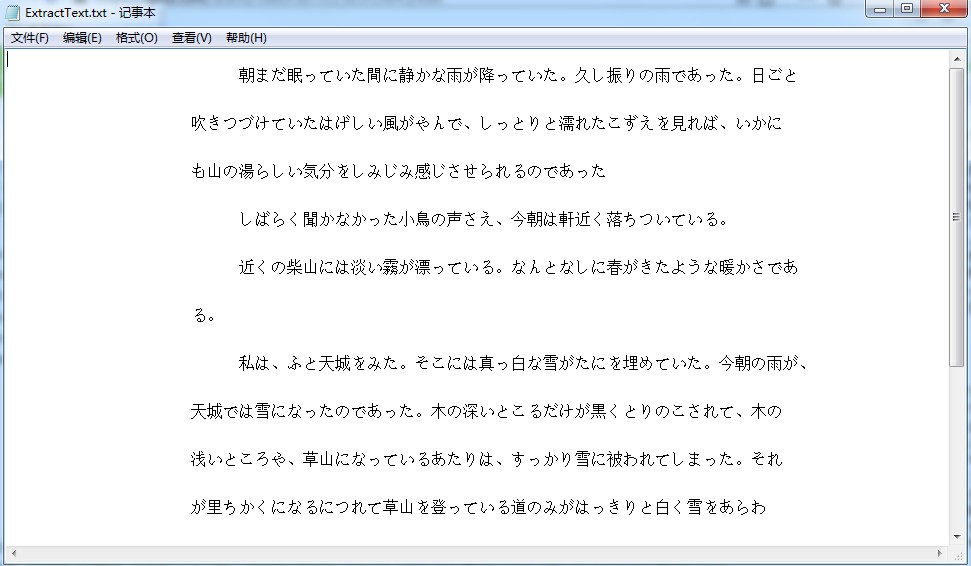
Recommended Posts