[JAVA] Einführung in Apache Beam (2) ~ ParDo ~
Gesamtzweck
Erstellen Sie ein einfaches Apache Beam-Programm, um zu verstehen, wie es funktioniert
Vorheriger Inhalt
Ich habe den gelesenen Text so geschrieben, wie er ist, um den Start zu bestätigen. Einführung in Apache Beam (1) ~ Lesen und Schreiben von Text ~
Zweck dieser Zeit
Ändern Sie den Datentyp, indem Sie für jede gelesene Textzeile eine ParDo-Verarbeitung durchführen Insbesondere wird der Prozess "Lesen von Bitcoin-Tickerinformationen aus Textdaten und Extrahieren eines beliebigen Werts daraus" durchgeführt.
Was ist ParDo überhaupt?
Core Beam Transforms Beam bietet die folgenden 6 als Basisdatenvarianten (wie die Gliederung der Verarbeitung)
- ParDo (ich mache diesmal)
- GroupByKey
- CoGroupByKey
- Combine
- Flatten
- Partition
Eines davon ist ParDo
Welche Art der Verarbeitung?
- Verantwortlich für den Map-Teil des MapReduce-Algorithmus
- Verarbeiten Sie die als Eingabe empfangene PC-Sammlung
- 0 oder 1 oder mehr PC-Sammlungen ausgeben
Kurz gesagt, der Prozess der Verarbeitung der Eingabedaten (1 Stück) und der Ausgabe (unabhängig von der Anzahl)
Hauptgeschichte
Umgebung
Genauso wie letztes Mal
IntelliJ
IntelliJ IDEA 2017.3.3 (Ultimate Edition)
Build #IU-173.4301.25, built on January 16, 2018
Licensed to kaito iwatsuki
Subscription is active until January 24, 2019
For educational use only.
JRE: 1.8.0_152-release-1024-b11 x86_64
JVM: OpenJDK 64-Bit Server VM by JetBrains s.r.o
Mac OS X 10.12.6
Maven : 3.5.2
Verfahren
Zu verwendende Textdaten
Die verwendeten Daten sind wie folgt BTC / JPY-Rateninformationen im Bitflyer werden 10 Mal alle 10 Sekunden erfasst.
Die Bestellung lautet "
Sample.txt
BTC/JPY,bitflyer,1519845731987,1127174.0,1126166.0
BTC/JPY,bitflyer,1519845742363,1127470.0,1126176.0
BTC/JPY,bitflyer,1519845752427,1127601.0,1126227.0
BTC/JPY,bitflyer,1519845762038,1127591.0,1126316.0
BTC/JPY,bitflyer,1519845772637,1127801.0,1126368.0
BTC/JPY,bitflyer,1519845782073,1126990.0,1126411.0
BTC/JPY,bitflyer,1519845792827,1127990.0,1126457.0
BTC/JPY,bitflyer,1519845802008,1127980.0,1126500.0
BTC/JPY,bitflyer,1519845812088,1127980.0,1126566.0
BTC/JPY,bitflyer,1519845822743,1127970.0,1126601.0
Lesen Sie diesen Text und extrahieren Sie mit ParDo beliebige Informationen (diesmal "BID") aus jeder Zeile.
Codeänderung
Der Code lautet diesmal wie folgt.
SimpleBeam.java
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.values.PCollection;
public class SimpleBeam {
//hinzufügen
public static class ExtractBid extends DoFn<String, String> {
@ProcessElement
public void process(ProcessContext c){
//Holen Sie sich Reihe
String row = c.element();
//Mit Komma teilen
String[] cells = row.split(",");
//Gibt BID zurück
c.output(cells[4]);
}
}
public static void main(String[] args){
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
//Text lesen
PCollection<String> textData = p.apply(TextIO.read().from("Sample.txt"));
//Von hier hinzugefügt
PCollection<String> BidData = textData.apply(ParDo.of(new ExtractBid()));
//Addiere hier
//Text schreiben
BidData.apply(TextIO.write().to("output/bid"));
//Pipeline-Lauf
p.run().waitUntilFinish();
}
}
Die Ausgabe des vorherigen Codes war "Wortanzahl" und ich wusste, dass ich das Beispiel kopiert und eingefügt habe, also habe ich das Ausgabeziel geändert. .. ..
Die Ausführungsmethode ist dieselbe wie beim letzten Mal. Weitere Informationen finden Sie unter hier.
Ausführungsergebnis
Das Ausführungsergebnis ist wie folgt und Sie können sehen, dass die BID-Daten (ganz rechts von Sample.txt) extrahiert wurden.
Dieses Mal wird der Einfachheit halber nur ein String extrahiert. Auf diese Weise können Sie jedoch den Datentyp ändern und die Daten formatieren.
Mit dieser Art der Verarbeitung können Sie einen beliebigen Schlüssel für die Eingabedaten festlegen und zur Verarbeitung "Reduzieren" wechseln.
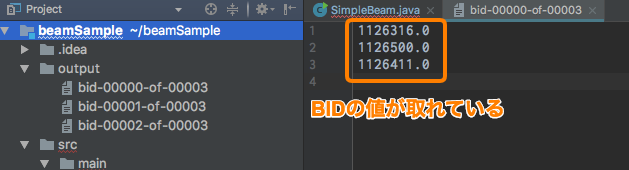
Ist die Ausgabe wie das Bild in drei Dateien unterteilt, weil der Kartenprozess abgeschlossen ist und dann Reduzieren verteilt und ausgeführt wird?
Über SimpleFunction
Eine Klasse namens "SimpleFinction" ist bereit, die gleiche Verarbeitung zu realisieren, und ich war neugierig, was anders ist, also werde ich es als Bonus zusammenfassen.
Laut dem offiziellen Dokument
If your ParDo performs a one-to-one mapping of input elements to output elements–that is, for each input element, it applies a function that produces exactly one output element, you can use the higher-level MapElements transform. MapElements can accept an anonymous Java 8 lambda function for additional brevity.
Es scheint eine Geschichte zu sein, die Sie mit einer anonymen Funktion abstrakter und einfacher beschreiben können als DoFn von ParDo.
Versuchen Sie, mit der einfachen Funktion neu zu schreiben
Code
beamSample.java
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.values.PCollection;
import org.apache.beam.sdk.values.TypeDescriptors;
public class SimpleBeam {
public static void main(String[] args){
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
//Text lesen
PCollection<String> textData = p.apply(TextIO.read().from("Sample.txt"));
//Implementieren Sie denselben Prozess mit anonymen Funktionen
PCollection<String> BidData = textData.apply(
MapElements.into(TypeDescriptors.strings())
.via((String row) -> row.split(",")[4])
);
//Text schreiben
BidData.apply(TextIO.write().to("output/bid"));
//Pipeline-Lauf
p.run().waitUntilFinish();
}
}
Es ist viel einfacher! Was den Eindruck betrifft, dass ich Beam eine Weile berührt habe, ist es ziemlich mühsam, jedes Mal "DoFn" zu erstellen, da der Vorgang des einfachen Änderns des Datentyps übereinstimmt und ich ihn daher gerne aktiv nutzen möchte.
Mit anderen Worten
Java 8 kann nicht aktiviert werden
Normale Änderungsmethode File => Project Structure...
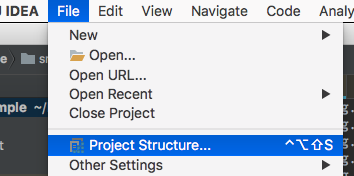
ProjectSettings => Project => Setzen Sie Project language level auf 8
** Besteht immer noch nicht ... Befolgen Sie in einem solchen Fall die folgenden Schritte **
Lösung
Die folgende Beschreibung wurde zu "pom.xml" hinzugefügt
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>beamSample</groupId>
<artifactId>beamSample</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 1.Hinzugefügt, um 8 erkannt zu machen-->
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<!--Addiere hier-->
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>2.4.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
</project>
vom nächsten mal
Dieses Mal habe ich ParDo implementiert, was der Kartenverarbeitung von MapReduce entspricht. Beim nächsten Mal möchte ich die Reduce-Verarbeitung einfach implementieren und den Durchschnitt der Ticker-Informationen ermitteln.
Recommended Posts