[JAVA] Eine Aufzeichnung einer einfachen Berührung des GCP-Datenflusses
Intro Da ich Google Cloud Dataflow berührt habe, werde ich als Erinnerung aufzeichnen, wie es sich anfühlte.
Was ist Google Cloud Dataflow?
Einfach ausgedrückt handelt es sich um einen GCP-Dienst, der den Betrieb und die Verwaltung von Streaming-Daten und anderen Informationen übernimmt. Dieses Mal werde ich die von PubSub empfangenen Daten über DataFlow in CloudStrage platzieren. Es wird davon ausgegangen, dass eine Vielzahl von Dingen wie Protokolle und Verfolgungsdaten veröffentlicht werden und diese aufbewahrt oder für spätere Analysen verwendet werden.
1.Pub/Subにトピックを作成
Pub / Sub ist ein anderer direkter Name, aber dies ist auch ein GCP-Dienst. Sogenanntes Messaging oder Warteschlange. Es wird der Ausgangspunkt dieser Daten sein, gewissermaßen ein Auslöser. Benennen Sie es vorerst einfach über die GUI-Konsole.
2. Bereiten Sie einen Bucket im Cloud-Speicher vor
Bereiten Sie einen Ort vor, der der Endpunkt dieser Zeit sein soll. Erstellen Sie einen neuen Bucket oder bereiten Sie einen Ordner vor, falls dieser bereits vorhanden ist. Bereiten Sie auch einen Ordner zum Platzieren der temporären Dateien vor (später beschrieben).
3. Erstellen Sie DataFlow aus der Vorlage
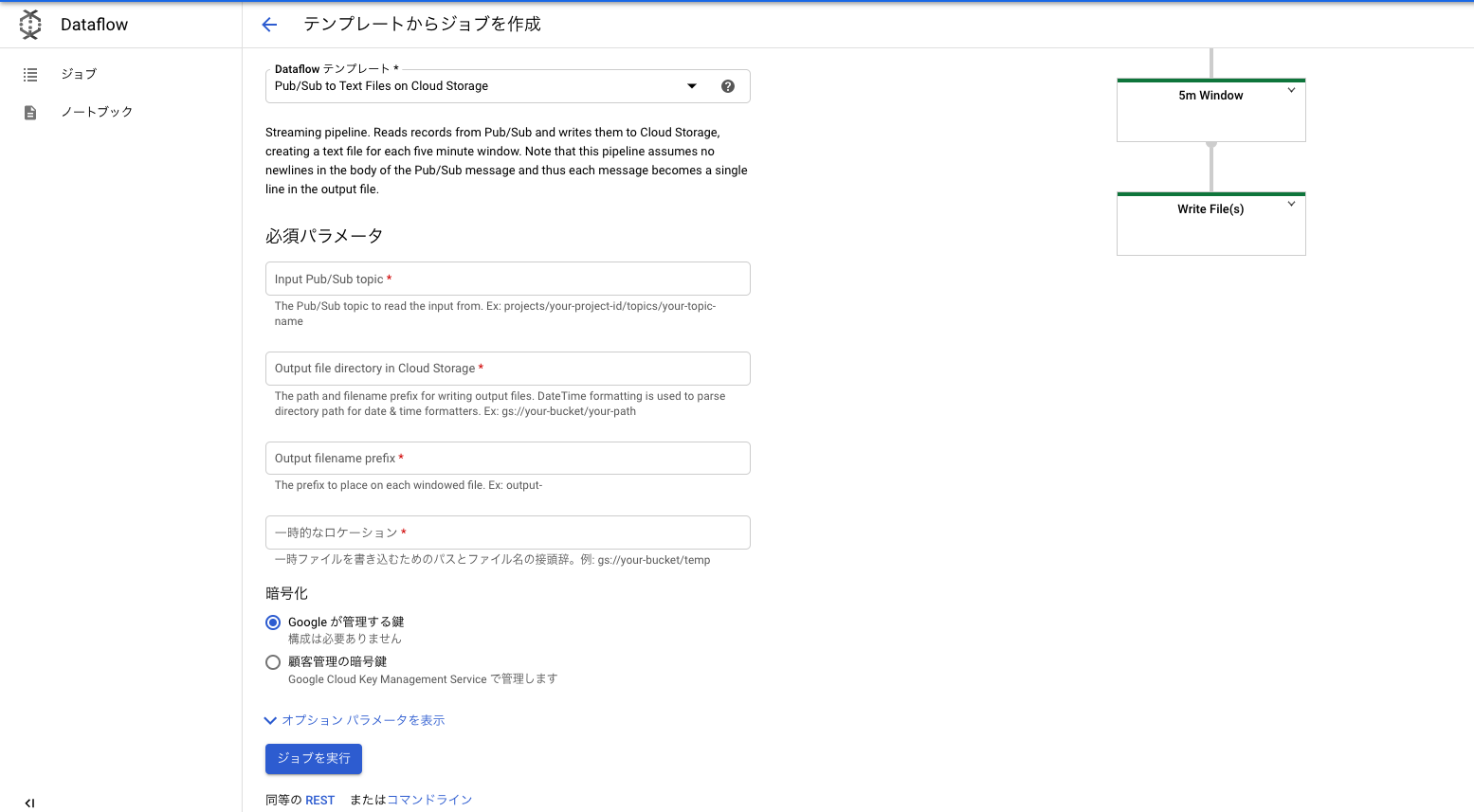
Sobald Sie sich vorbereitet haben, müssen Sie nur noch auf den Bildschirm klicken. Da DataFlow Vorlagen für häufig verwendete Anwendungsfälle enthält, Sie können etwas erstellen, das bis zu einem gewissen Grad funktioniert, indem Sie es entsprechend auswählen und die erforderlichen Einstellungen vornehmen.
Wenn Sie den Erstellungsbildschirm über den Link "Job aus Vorlage erstellen" erreichen, wählen Sie den Jobnamen und die Region aus. Wählen Sie dann eine Vorlage aus. Wählen Sie dieses Mal "Pub / Sub to Text Files on Cloud Strage" (wie es ist!). Um andere wesentliche Parameter einzustellen,
- Pub- / Unterthemennamen sollten mit "projects ~" beginnen (das auf der Themendetailseite kopiert werden kann).
- Das Ausgabeverzeichnis kann das Datumsformat verwenden. Wenn Sie "gs: // foo-Bucket / Balkenordner / JJJJ / MM / TT" schreiben, weist YMD den Ordnern automatisch das Datum zu.
- "Temporärer Standort" muss angegeben werden. (Nun, wenn Sie / tmp in einem Eimer machen, ist es vorerst in Ordnung)
4. Versuchen Sie, in Topic zu veröffentlichen
Damit sind alle Einstellungen abgeschlossen. Nach dem Ausführen des Jobs und dem Veröffentlichen der Nachricht von PubSub wird die Datei nach einer Weile im Cloud-Speicher erstellt. Es gibt eine veröffentlichte Nachricht im Inneren! Übrigens scheinen die in 5 Minuten akkumulierten Nachrichten standardmäßig nach jedem Zeilenumbruch als eine Datei an Cloud Storage gesendet zu werden.
Bemerkungen / Eindrücke
- Ich habe übrigens kein Abonnement abgeschlossen. Normalerweise gibt es ein Abonnement für Topic und PubSub ist konfiguriert, aber dieses Mal scheint es, dass das Abonnement automatisch erstellt wurde, als der Job erstellt wurde.
- Für andere Konfigurationen als vorhandene Vorlagen müssen die entsprechenden Vorlagen implementiert werden. Es gibt jedoch ein Vorlagen-Repository auf Github, sodass Sie es basierend darauf anpassen können (Quelle ist Java oder Python).
- Am Ende würde ich gerne auch BigQuery ausprobieren, aber es scheint, dass es mit diesem Gefühl nicht schwierig sein wird.
Recommended Posts