Trial and error to speed up heat map generation
I was making a program to calculate a heat map (RGB) from a value that takes 0 to 255. The source I wrote first (GPU + Cupy) was too slow, so I will leave the result of trial and error.
** * cv2.applyColorMap (grayscale_image, cv2.COLORMAP_JET) solved everything, but I made it myself (shame). ** **
The following is the processing for the image size 320x180.
The code is only the main part.
In addition, the heat map is a simplified version (trigonometric function not used) to obtain the approximate value.
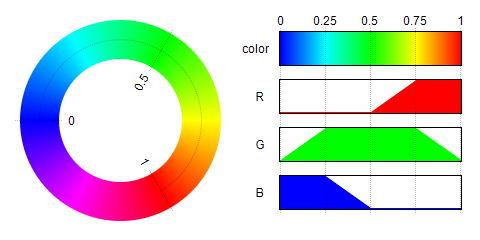
(Linear diagram of Convert value magnitude to thermography-like color).
GPU+Cupy(for) This is the code I originally wrote. It is a losing group code that is processed by turning it with for honestly.
def conv_v_to_heat(v):
image = cuda.cupy.zeros((v.shape[0], array.v[1], 4))
for i, w in enumerate(image):
for j, h in enumerate(w):
image[i,j,0] = get_heat_r(array[i][j])
image[i,j,1] = get_heat_g(array[i][j])
image[i,j,2] = get_heat_b(array[i][j])
image[i,j,3] = array[i][j] #Alpha is suitable
def get_heat_r(v):
if v <= 127:
return 0
elif v <= 190:
return (v-127)*4
else:
return 255
sec: 20.43495798110962
CPU+Numpy(for) Isn't it better to stop using the GPU than to use for? I changed it to CPU (source omitted).
sec: 0.6369609832763672
The CPU was faster at all.
CPU+Numba+Numpy(for) I put Numba.
@jit
def conv_v_to_heat(v):
@jit
def get_heat_r(v):
sec: 0.20061397552490234
It's even faster.
CPU+Numba+Numpy(filter) In the first place, it is a loser when using for for Numpy, so I tried to deal with it by filtering.
def conv_v_to_heat(v):
image = np.zeros((v.shape[0], v.shape[1], 4))
image[:, :, 0] = get_r(array)
image[:, :, 1] = get_g(array)
image[:, :, 2] = get_b(array)
image[:, :, 3] = v
def get_heat_r(v):
out = np.zeros((v.shape))
out[...] = 255
out[(v<=190)] = (v[(v<=190)]-127)*4
out[(v<=127)] = 0
return out
sec: 0.0013210773468017578
It's overwhelmingly faster.
CPU+Numpy(filter) As a test, I will remove Numba.
sec: 0.001230478286743164
That's faster. Rather, it is an error level.
GPU+Cupy(filter) Then what about GPU?
sec: 0.008527278900146484
I am late.
Summary
| Implementation | time(sec) |
|---|---|
| GPU+Cupy(for) | 20.43495798110962 |
| CPU+Numpy(for) | 0.63696098327637 |
| CPU+Numba+Numpy(for) | 0.20061397552490 |
| CPU+Numba+Numpy(filter) | 0.00132107734680 |
| CPU+Numpy(filter) | 0.00123047828674 |
| GPU+Cupy(filter) | 0.00852727890015 |
CPU + Numpy (filter) was the best. I think there is a faster implementation, but personally it's a satisfying speed. After all, if you use for, you will lose.
Recommended Posts