[JAVA] Pokemon icon image discrimination using HOG features
Purpose
- There are various Pokemon battle log tools, but it's too tedious to have to enter the contents of the opponent party by myself, so I wanted to create something that would automatically determine it.
- I wanted to use HOG features.
The implemented ones are at the bottom of the article.
- This version is intended for screens displayed on monitors using fake Toro Capture.
About HOG features
HOG (Histgram Of Gradient) is like the distribution of brightness gradients in an image. Since you can detect where the brightness changes significantly, you can roughly get the edge distribution of the image. The explanation of here was easy to understand.
 Expressed as an image
Expressed as an image
 I feel like this.
(The source of the image is Kotoba sisters standing picture material (30 types each))
I feel like this.
(The source of the image is Kotoba sisters standing picture material (30 types each))
- The background color of the available data and the background color on the game screen to be discriminated are different.
- On the game screen, the background color differs depending on the position.
It is especially important this time that it is hard to be influenced by these two points.
The HOG extraction method is implemented in various libraries. In the range I tried
--scikit-image hog --HOGDescriptor for OpenCV (for Python) --HOGDescriptor for OpenCV (for java)
I tried three types. Terrifyingly ** The methods implemented in these will return different results (only the number of dimensions is equal) **. The outline of the algorithm is the same, but the detailed implementation such as the calculation procedure seems to be different.
algorithm
Outline of procedure
- Extracting party frames from images
- Cut out the Pokemon icon part from the party frame part
- Name estimation for each icon part
Extraction of party slots
Just grab the edge with the Canny filter and hollow out the inside. It is almost this.
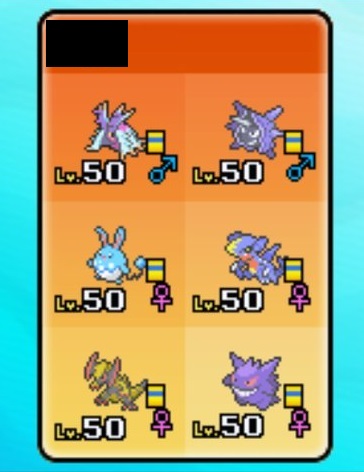 The original image
The original image
 Edge extraction image
Edge extraction image
 Crop image
Crop image
- The trainer name has been turned down for the time being
Cut out the icon part
Since the location of the icon image part in the frame is fixed, all you have to do is determine the position and cut it out. I adjusted it appropriately while experimenting.

 You can get an image like this.
You can get an image like this.
Name estimation using HOG features
- Divide the 30x30 image into 3 color channels of BGR
- Noise removal with Gaussian filter for each image
- Calculate HOG with cell size 5 pixels and block size 30 pixels (6 cells) (324 dimensions)
- Combine HOGs for 3 colors into a 972 dimensional vector
- Calculate the Manhattan distance from the similarly extracted vector for each teacher image
- The image with the closest distance is the correct answer
I tried several types of cell size and block size, but this combination was good. In order to use this combination well, the size of the judgment image is set to 30x30. I will paste the Python code (estimated part). Since the version pasted first was old, I replaced only the hyperparameters used for HOG calculation (2017/3/4)
estimate.py
#A method for estimating Pokemon names. The argument data is a pair of Pokemon name and its HOG.
def estimate_poke_index(image, data):
hog = calculateHOG(image)
distance_list = calculate_manhattan_distance(hog, data)
return np.argmin(np.array(distance_list))
#A method that reads an image, calculates and returns HOG features
def calculateHOG(image, orient=9, cell_size=5, block_size=6):
#Load image
number_color_channels = np.shape(image)[2]
if number_color_channels > 3:
mask = image[:, :, 3]
image = image[:, :, :3]
for i in range(len(mask)):
for j in range(len(mask[0])):
if mask[i][j] == 0:
image[i, j, :] = 255
#Resize the image to 30x30
resized_image = cv2.resize(image, (30, 30))
images = cv2.split(resized_image)
fd = []
for monocolor_image in images:
blur_image = cv2.GaussianBlur(monocolor_image, (3,3),0)
fd.extend(hog(blur_image, orientations=orient,
pixels_per_cell=(cell_size, cell_size), cells_per_block=(block_size, block_size)))
return fd
#Distance calculation method between HOG features
def calculate_distance_HOG(target, data):
distance_list = []
rows, columns = np.shape(data)
for i in range(rows):
distance_list.append(np.linalg.norm(data[i, :] - target))
return distance_list
#Manhattan distance calculation method
def calculate_manhattan_distance(target, data):
distance_list = []
rows, columns = np.shape(data)
for i in range(rows):
distance_list.append(np.sum(np.abs(data[i, :] - target)))
return distance_list
Impressions
Although it is a rough algorithm, 70 to 80% of the experience is hit. It would be nice if I could write about the test results, but I'm afraid I haven't done a consistent test. (2017/3/4 postscript) When I got the data for 19 games and checked the false recognition rate, I made a mistake with 20/114. It seems that about 80% can be guessed, but I want to manage the misrecognition of Pokemon with high KP such as "Greninja → Fukuslow" and "Garula → Swablu".
- Similar in color scheme and shape (such as Gabite and Garchomp)
- Pokemon with small icons (Garula, Lucario, Metamon, Lucky, etc.) are placed closer to the lower right than expected.
Two are probably the main misperceptions. The second may be correct if the algorithm is slightly improved.
Although it is for tool developers, I will put Implemented and solidified in Java. It's okay to use it freely, but I'd be happy if you could let me know. (Because I want to go see the finished product)