Count the number of characters in a UTF-8 string
Decompose UTF-8 into code points
First of all, create a program that displays the character string entered as a command line argument for each code point. How to find the code point from UTF-8 is as described in Wikipedia.
** Note: ** The following instructions will not work on Windows. Try it on Linux, FreeBSD, MacOSX (or Cygwin).
#include <stdio.h>
/**
* next_codepoint(&ptr);
*Move ptr to the position of the next code point
*/
static int next_codepoint(const char **pp)
{
const char *p = *pp;
int c = -1;
if (*p == 0) {
} else if ((*p & 0x80) == 0) {
c = *p++ & 0xFF;
} else if ((*p & 0xE0) == 0xC0) {
c = *p++ & 0x1F;
c = (c << 6) | (*p++ & 0x3F);
} else if ((*p & 0xF0) == 0xE0) {
c = *p++ & 0x0F;
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
} else if ((*p & 0xF8) == 0xF0) {
c = *p++ & 0x07;
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
}
*pp = p;
return c;
}
int main(int argc, char **argv)
{
if (argc >= 2) {
const char *p = argv[1];
int ch;
int count = 0;
while ((ch = next_codepoint(&p)) != -1) {
printf("U+%04X ", ch);
count++;
}
printf("\nCount = %d\n", count);
}
return 0;
}
The execution result is as follows. "Aiueo" consists of 5 code points.
$ ./a.out Aiueo
U+3042 U+3044 U+3046 U+3048 U+304A
Count = 5
About Grapheme Graham
For example, let's count the number of characters in the following string.
Point
If you copy and paste it as it is and execute it, it will be judged as 4 characters.
$ ./a.out point
U+30DD U+30A4 U+30F3 U+30C8
Count = 4
So what about the following string?
Point
If you copy and paste it as it is and execute it, it will be judged as 5 characters.
$ ./a.out point
U+30DB U+309A U+30A4 U+30F3 U+30C8
Count = 5
In the latter case, the number of code points is 2, but the number of characters is 1, because "po" has been properly decomposed. In the following explanation, characters that are given a single code in Unicode are referred to as "code points", and the unit that is generally recognized as one character (strictly speaking, Grapheme) is referred to as "grapheme". ..
Use Unicode.org data
The only way to count graphemes is to look up the table to find the grapheme breaks. Currently, the latest version of Unicode 7.0.0 Grapheme Break Property is available, so we will use it.
ftp://ftp.unicode.org/Public/7.0.0/ucd/auxiliary/GraphemeBreakProperty.txt
This text file is written as follows. (Comments after #)
000A ; LF # Cc <control-000A>
U + 000A means that it is classified as LF.
3099..309A ; Extend # Mn [2] COMBINING KATAKANA-HIRAGANA VOICED SOUND MARK..COMBINING KATAKANA-HIRAGANA SEMI-VOICED SOUND MARK
U + 3099 to U + 309A means that they are classified as Extend. Code points that do not fall within these ranges are classified as Other.
In order to run the sample code below, you need to create a binary file called grapheme.dat from GraphemeBreakProperty.txt, so please do your best. For grapheme.dat, for example, if U + 309A is Extend, the 0x309A byte from the beginning will be 4.
#include <stdio.h>
#include <stdlib.h>
enum {
CR = 1,
LF = 2,
Control = 3,
Extend = 4,
SpacingMark = 5,
L = 6,
V = 7,
T = 8,
LV = 9,
LVT = 10,
Regional_Indicator = 11,
};
enum {
MAX_CODEPOINT = 0x10000,
};
/**
* next_codepoint(&ptr);
*Move ptr to the position of the next code point
*/
static int next_codepoint(const char **pp)
{
const char *p = *pp;
int c = -1;
if (*p == 0) {
} else if ((*p & 0x80) == 0) {
c = *p++ & 0xFF;
} else if ((*p & 0xE0) == 0xC0) {
c = *p++ & 0x1F;
c = (c << 6) | (*p++ & 0x3F);
} else if ((*p & 0xF0) == 0xE0) {
c = *p++ & 0x0F;
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
} else if ((*p & 0xF8) == 0xF0) {
c = *p++ & 0x07;
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
c = (c << 6) | (*p++ & 0x3F);
}
*pp = p;
return c;
}
char *load_grapheme_data(void)
{
FILE *fp = fopen("grapheme.dat", "rb");
char *dat = malloc(MAX_CODEPOINT);
fread(dat, 1, MAX_CODEPOINT, fp);
fclose(fp);
return dat;
}
int main(int argc, char **argv)
{
if (argc >= 2) {
const char *p = argv[1];
int ch;
char *dat = load_grapheme_data();
while ((ch = next_codepoint(&p)) != -1) {
if (ch < MAX_CODEPOINT) {
switch (dat[ch]) {
case CR:
printf("CR ");
break;
case LF:
printf("LF ");
break;
case Control:
printf("Control ");
break;
case Extend:
printf("Extend ");
break;
case SpacingMark:
printf("SpacingMark ");
break;
case L:
printf("L ");
break;
case V:
printf("V ");
break;
case T:
printf("T ");
break;
case LV:
printf("LV ");
break;
case LVT:
printf("LVT ");
break;
default:
printf("Other ");
break;
}
}
}
printf("\n");
}
return 0;
}
The execution result is as follows.
$ ./a.out point
Other Extend Other Other Other
Find the break position from GraphemeBreakProperty
It's another breath when you come here. You can see where the break position is by looking at the Grapheme Break Chart table. The table below is an excerpt.
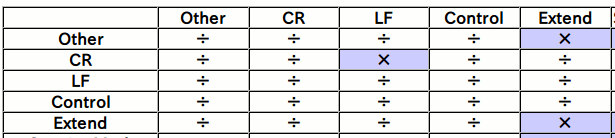
The vertical columns of the table represent the front code points and the horizontal columns represent the back code points. "÷" indicates that the grapheme is delimited, and "x" is not the grapheme delimiter. For example, if the front code point is Extend and the back code point is Other, the grapheme will be separated because it will be "÷", but if the front code point is Other and the back code point is Extend, it will be "x". Therefore, the grapheme is not separated. (Make one grapheme with the previous code point)
/*
*Other than the main function, it has not been changed, so it is omitted.
*/
int main(int argc, char **argv)
{
/**
* http://unicode.org/Public/UNIDATA/auxiliary/GraphemeBreakTest.html
*/
static const unsigned short grapheme_break[] = {
0x0030,
0x0004,
0x0000,
0x0000,
0x0030,
0x0030,
0x06f0,
0x01b0,
0x0130,
0x01b0,
0x0130,
0x0830,
};
if (argc >= 2) {
const char *p = argv[1];
int ch, type, prev_type = -1;
char *dat = load_grapheme_data();
int count = 0;
while ((ch = next_codepoint(&p)) != -1) {
if (ch < MAX_CODEPOINT) {
type = dat[ch];
if (prev_type >= 0) {
if ((grapheme_break[prev_type] & (1 << type)) == 0) {
printf("| ");
count++;
}
}
prev_type = type;
switch (type) {
case CR:
printf("CR ");
break;
case LF:
printf("LF ");
break;
case Control:
printf("Control ");
break;
case Extend:
printf("Extend ");
break;
case SpacingMark:
printf("SpacingMark ");
break;
case L:
printf("L ");
break;
case V:
printf("V ");
break;
case T:
printf("T ");
break;
case LV:
printf("LV ");
break;
case LVT:
printf("LVT ");
break;
default:
printf("Other ");
break;
}
}
}
if (prev_type >= 0) {
count++;
}
printf("\nCount = %d\n", count);
}
return 0;
}
The execution result is as follows. Each grapheme is separated by |.
$ ./a.out point
Other Extend | Other | Other | Other
Count = 4
Finally
Use ICU rather than making it yourself.
Recommended Posts