[JAVA] Apache Spark Document Japanese Translation --Cluster Mode Overview
A Japanese translation of the following deployment overview of the Apache Spark project. http://spark.apache.org/docs/latest/cluster-overview.html
If you find something wrong with the translation, please let us know in the comments.
The Japanese translations of Quick Start and EC2 introduction are also posted below, so please have a look.
- Quick Start
http://qiita.com/mychaelstyle/items/46440cd27ef641892a58 - Spark on AWS EC2
http://qiita.com/mychaelstyle/items/b752087a0bee6e41c182
Cluster Mode Overview
This document gives a short overview of how Spark runs on clusters, to make it easier to understand the components involved. Read through the application submission guide to submit applications to a cluster.
This document is a quick overview of how Spark works on a cluster to easily understand the complex components. Read the Application Submission Guide to learn how to deploy your application to a cluster.
http://spark.apache.org/docs/latest/submitting-applications.html
Components
Spark applications run as independent sets of processes on a cluster, coordinated by the SparkContext object in your main program (called the driver program).
Spark applications work together as a set of independent processes on a cluster with the SparkContext object of your application's main program (called the driver program).
Specifically, to run on a cluster, the SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager or Mesos/YARN), which allocate resources across applications.
In particular, to work in a single cluster, SparkContext connects to several types of cluster managers (Spark's own standalone cluster manager or Mesos / YARN) and allocates resources across applications.
Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks for the executors to run.
Once connected, Spark gets executeros on the nodes of the cluster, they perform calculations for your application and store the data. Then your application code (JAR or Python files passed to SparkContext) will be sent to the executors. Finally, SparkContext sends an executors execution task.
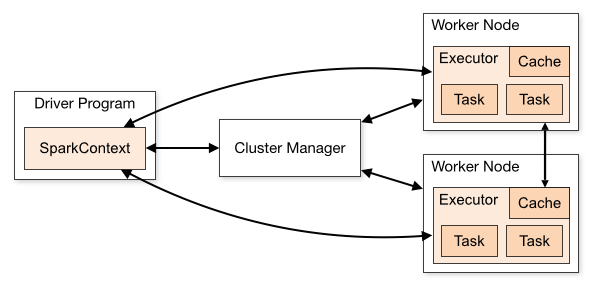
There are several useful things to note about this architecture:
There are some useful things about the architecture.
- Each application gets its own executor processes, which stay up for the duration of the whole application and run tasks in multiple threads. This has the benefit of isolating applications from each other, on both the scheduling side (each driver schedules its own tasks) and executor side (tasks from different applications run in different JVMs). However, it also means that data cannot be shared across different Spark applications (instances of SparkContext) without writing it to an external storage system.
Each application gets its own set of executor processes while every thread that executes the task is executed. This is very useful in terms of scheduling (each driver schedules its own tasks) and executor (tasks from different applications run on different JVMs) in separating each application individually. However, this means that data cannot be shared by different Spark applications (SparkContext instances) without the use of an external storage system.
- Spark is agnostic to the underlying cluster manager. As long as it can acquire executor processes, and these communicate with each other, it is relatively easy to run it even on a cluster manager that also supports other applications (e.g. Mesos/YARN).
Spark has nothing to do with the cluster manager. While requesting executor processes and communicating with each other, Spark runs on a cluster manager that supports real other applications relatively easily.
- Because the driver schedules tasks on the cluster, it should be run close to the worker nodes, preferably on the same local area network. If you’d like to send requests to the cluster remotely, it’s better to open an RPC to the driver and have it submit operations from nearby than to run a driver far away from the worker nodes.
The driver schedules tasks on the cluster and should be run near a set of worker nodes, rather within the same local area network. If you want to send requests remotely, it's better to use RPC to submit your application and run it nearby than to run it from a distance in the worker nodes.