Creating an interactive application using a topic model
I want to heal my eyes with the blue ocean rather than burning my eyes with the blue light.
2015 is nearing the end, but how are you all doing? Since I want to return to nature around the end of the year, this time I will introduce how to create an application that makes travel proposals interactively using a topic model.
This article is a sister article of the previously published Creating an application using the topic model. At that time, application creation was not catching up, and although we said "application creation", we did not reach application creation, so it will be a complement to that. I will not touch on the topic model itself this time, so if you are interested, please refer to the above article.
What is a topic model?
I will leave the detailed explanation to here, but the topic model is to classify documents by topic as the name suggests. It is a method of. Specifically, the "topic" here has the following image.
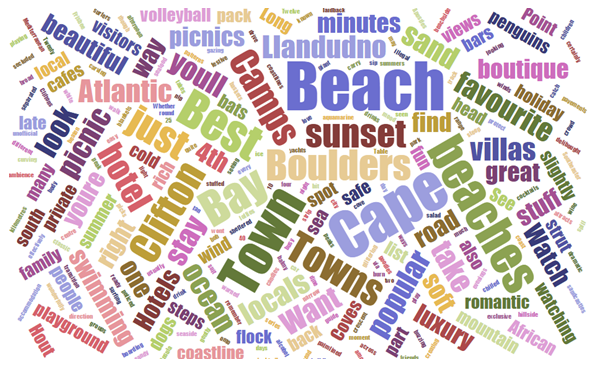
This is a word cloud created from a travel blog. A "topic" is thus composed of words, and some of the words are frequent and some are not. Estimating the probability distribution that defines the "appearance word" and "appearance probability" is the main focus of the topic model. If this probability distribution is clarified, it will be possible to classify documents with similar distributions, and it will also be possible to estimate the degree of relevance between documents from the distance between distributions.
Application to interactive applications
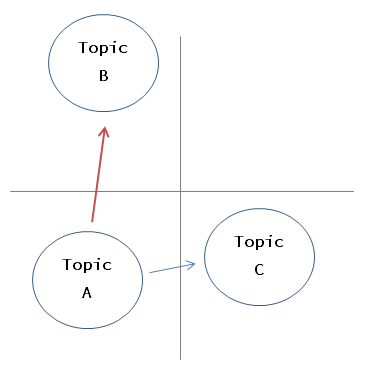
Topics can be represented by probability distributions as described above, so that the distance between distributions can be calculated (this time I used KL-divergence). Using this distance, try to propose a spot for topic A, and if the answer is No, propose a distant topic (topic B, which is the farthest in the figure), and implement it with a simple policy. I will try.
Implementation of interactive application
The application implemented this time is here.
I suggest about 3 candidates from the same topic, which can be switched with the arrow below. If there is something you like / image is different, you can evaluate it with the Good / Bad button below. Receive ratings and make suggestions for similar / distant topics.

Since it has a Heroku Button, you can deploy it to your Heroku environment. Try it with the topic model I made! That's quite possible. As data, the API of AB-ROAD is used, and this usage registration is required.
Application implementation
The application configuration is as follows.

- ʻApplication`: Web application implementation
data: Stores the trained model file. Since it was troublesome to use the database, the spot data is also included this time, but originally it will be repelled by ignore.pola: Contains the topic model and the implementation of dialogue using it.polais the name of the engine that conducts this" dialogue using the topic model "(I chose a foreigner-like name because it is an overseas trip).scripts: Various scripts for extracting, formatting, and training datatests: test code
In the composition, I paid attention to the following points.
- ** Separate application implementation and machine learning implementation ** (separation of ʻapplication
andpola`) When developing with multiple teams, it is highly likely that these responsibilities will be separated, and I think it is better to separate them in terms of increasing the portability of the machine learning part. - ** Separate data extraction / formatting processing from machine learning model implementation ** (separation of
polaandscripts) The implementation of the machine learning part is mainly divided into the code related to "data extraction and shaping" and the "machine learning model" part. And the former is often really dependent on the data to be handled, and if this is incorporated into the "implementation of a machine learning model", the model itself becomes a data source and a lot of people, so this is separated. I think it is desirable to abstract the machine learning model part to some extent, such as "applicable if data is entered in this format". - ** Separation of trained model files and machine learning implementation ** (
polaanddata) Since the modification of the machine learning model itself (algorithm modification etc.) and the update of the trained model that is the learning result should be different, this time we explicitly separate the two. Of course, I think there is also the idea of managing with a trained model included.
After that, like the application, write the test code exactly for the machine learning model, and attach the document with iPython notebook for the machine learning model.
The construction assumptions and verification of the topic model constructed this time can be referred from the following iPython notebook.
enigma_abroad/pola/machine/topic_model_evaluation.ipynb
Building a topic model
Of course, when making a proposal, it is essential to build a topic model, which is the brain of the application.
This time, like the sister article Creating an application using a pick model, [gensim]( I built it using https://radimrehurek.com/gensim/) (I tried using pymc as well, but it was sealed because the memory was lost due to learning). And sadly, the accuracy wasn't as good as it was ... but I'm going to continue here.
In addition, when it comes to actually using machine learning in an application, it is unlikely that "accuracy 99% or!" Like the tutorial, and even if there is, it is either a hallucination due to overfitting or a bug created by oneself. It is often the case.
To overcome this, steady data collection and steady data preprocessing are required. Ah ... when I talked about what happened, I was trying to do something cool with machine learning, but before I knew it, I was meticulously setting words to exclude from the corpus ... ・. Content-based recommendation such as the topic model has the advantage that it can be recommended even when the user's evaluation data is irresistible compared to collaborative filtering that is often used for recommendation, but after all the amount of content and its shaping must be done properly. It doesn't work well (there are a number of documents, but the volume of the document itself is also quite good).
Consideration
Although it was made into an application, the essential topic model has not been built well. Last time I dealt with data different from hair salon and this time travel plan, but all of them ended up with sad results that topics could not be classified well.
I think the cause of this is the data problem.
- Number of words per document: If it is not long enough, only a few keywords will appear, which is not so different from other words. As a result, it becomes difficult to determine which topic it is, and it also affects the total number of words.
- Clear topic difference: All of them are documents in the existing categories such as "hair salon" and "travel plan", so there is not much difference in the words that appear.
In short, I think it is desirable to apply it in a situation where there are various variations of documents and each is reasonably long. If you want to make more detailed classifications within the same category, I think you need to build some prior knowledge.
- Build a topic model with prior knowledge: Build a cluster of words in advance from Wikipedia etc. (“sea” and “beach” are the same cluster, etc.), and build a topic model based on the cluster of words instead of the words themselves. To do. By doing this, it is possible to put together notational fluctuations and consensus words, and it becomes easier to find topics even if the amount of documents is small.
- Learning word semantics: Humans can recognize the words "sea" and "beach" as talking about the sea, even if they occur only once. It can be said that the topic is considered by its meaning and related words, not by the frequency of occurrence of the word. Since these features can be vectorized just by using word2vec etc., the vector amount of each document is calculated based on the model trained in advance, and the classification is performed based on it.
I think there are many other ideas, so please try to create your own model and build an application that will take you to Blue Ocean.
