word2vec
Motivation ・ Word2vec can give a vector that can express the meaning of a word in a good way just by giving a large amount of text. ・ If you use that good vector as a feature, you can expect an improvement in accuracy in various tasks. ・ ・ I want to improve the accuracy of information recommendation ・ ・ Use as a feature for FX prediction tasks to improve accuracy, etc. ··Visualization
・ (Touch one end of deep learning)
stance
・ Aside from understanding word2vec, I want to use it to do interesting things and improve the accuracy of tasks.
Agenda | Plan ・ Experience how good the vector obtained by word2vec is (this is today) ・ Apply the vector obtained by word2vec to the information recommendation task and compare it with the result of a normal vector. ・ Apply the vector obtained by word2vec to the currency forecasting task and compare it with the result of ordinary vector. ・ Apply the vector obtained by word2vec to visualization such as character analysis to visualize the taste without borrowing human subjectivity. ・ ・ Example of visualization of onomatopoeia
 http://techlife.cookpad.com/entry/2015/02/27/093000
http://techlife.cookpad.com/entry/2015/02/27/093000
What is word2vec
・ If you give a large amount of text as input, something like a black box that creates a vector that can express the meaning of each word in a nice way
Try various things
First, try creating a vector with word2vec
Input: 100MB of English ↓ word2vec ↓ Output: Vector representation (200 dimensions) for every word
The source code can be written very simply
genModel.py
import gensim
sentences = gensim.models.word2vec.Text8Corpus("/tmp/text8")
model = gensim.models.word2vec.Word2Vec(sentences, size=200, window=5, workers=4, min_count=5)
model.save("/tmp/text8.model")
print model["japan"]
(Example) Vector of the word "japan"
aaa.txt
[-0.17399372 0.138354 0.18780831 -0.09954771 -0.05048304 0.140431
-0.08839419 0.0392667 0.267914 -0.05268065 -0.04712765 0.09693304
-0.03826345 -0.11237499 -0.12375604 0.15184014 0.09791548 -0.0411933
-0.26620147 -0.14839527 -0.07404629 0.14330374 -0.15179957 0.00764518
0.01670248 0.15400286 0.03410995 -0.32461527 0.50180262 0.29173616
0.17549005 -0.13509558 -0.20063001 0.50294453 0.11713456 -0.1423867
-0.17336504 0.09798998 -0.22718145 -0.18548743 -0.08841871 -0.10192692
0.15840843 -0.12143259 0.14727007 0.2040498 0.30346033 -0.05397578
0.17116804 0.09481478 -0.19946894 -0.10160322 0.0196885 0.11808696
-0.04913231 0.17468756 -0.14707023 0.02459025 0.11828485 -0.01075778
-0.13718656 0.05486668 0.25277957 -0.16104579 0.0396373 0.14481564
0.22176275 -0.17076172 -0.038408 0.29362577 -0.13069664 0.04339954
0.00451817 0.16272108 0.02541053 -0.14659256 0.16529948 0.13884881
-0.1113431 -0.09699004 0.07190027 -0.04339439 0.17680296 -0.21379708
0.1572576 0.03031984 -0.21495718 0.03347488 0.22941446 -0.13862187
0.21907888 -0.13375367 -0.13810037 0.09477621 0.13297808 0.25428322
-0.03635533 -0.1352797 -0.13009973 -0.01995344 0.05807789 0.34588996
0.10643663 -0.02748342 0.00877294 0.10331466 -0.02298069 0.26759195
-0.24946833 0.0619933 0.06216418 -0.20149906 0.0586744 0.16416067
0.34322274 0.25680053 -0.03443218 -0.07131385 -0.08819276 -0.02436011
0.01131095 -0.11262415 0.08383768 -0.17228018 -0.04570909 0.00717434
-0.04942331 0.01721579 0.19824736 -0.14876001 0.10319072 0.10815206
-0.24551305 0.02878521 0.17684355 0.13430905 0.03504089 0.14440946
-0.12238772 -0.09751064 0.22464643 -0.00364726 0.30931923 0.04332043
-0.00956943 0.40026045 -0.11306871 0.07663886 -0.21093726 -0.24558903
-0.11918587 -0.11373471 -0.04725014 0.16204022 0.06828773 -0.09220605
-0.04137927 0.06957231 0.29234451 -0.20949519 0.24574679 -0.14875519
0.24135616 0.13015954 0.03091074 -0.45729914 0.14642039 0.1330456
0.09597694 0.19738108 -0.08785061 0.15975344 0.11823107 0.10955801
0.43996817 0.22706555 -0.01743319 0.06030531 -0.08983251 0.43928599
0.07300217 -0.31112081 0.25329435 -0.02628026 -0.0781511 -0.03673798
0.01265055 -0.08048201 -0.0556048 0.25650752 0.02342006 -0.17268351
0.06641581 -0.04409864 0.02202901 -0.12416532 0.08068784 0.12611917
0.00144407 -0.24265616]
I'm not sure if it's okay or bad to just look at this vector, so I'll apply this vector to something
Try application 1: Search for similar words
Try to display the top 5 words similar to "japan". (Obtained using word2vec vector and cos similarity)
china 0.657877087593 india 0.605986833572 korea 0.598236978054 thailand 0.584705531597 singapore 0.552470624447
Countries with close ties are at the top. As a comparison, if you find the top 5 words in the same way with an ordinary vector (the vector formed by the frequency of appearance of words that co-occur with the word of interest) without using word2vec,
in 0.617413123609 pensinula 0.604392809245 electification 0.602260135469 kii 0.5864838915 betrayers 0.575804870177
And a subtle result. I think it will be better if you chew tf-idf etc.
Try application 2: Visualization of meaning
Visualize the vector obtained from word2vec and confirm that the positional relationship expresses the meaning. For example, the example below plots two words for some country-capital pairs. The positional relationship between the country and the capital is established in all cases → The concept of the relationship between the country and the capital can be grasped.
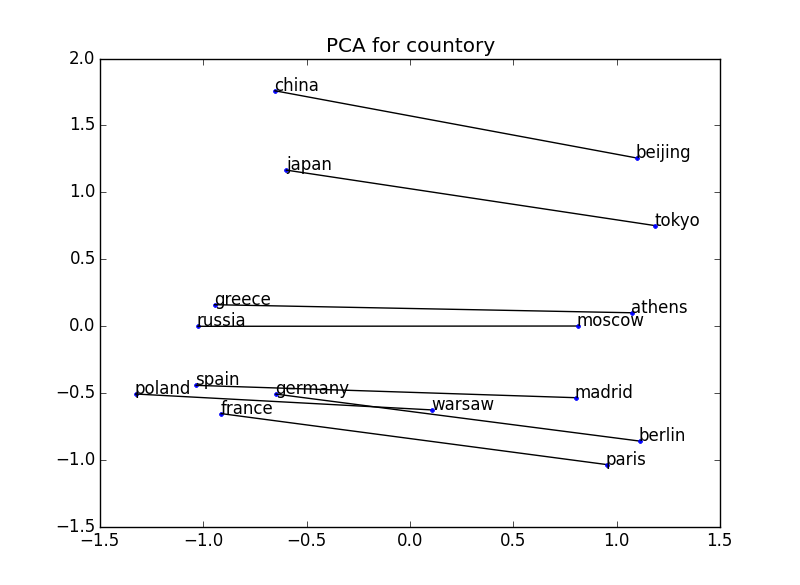 200 dimensions → 2 dimensions
200 dimensions → 2 dimensions
For comparison, we plotted in the same way with an ordinary vector (a vector formed by the frequency of appearance of words co-occurring with the word of interest) without using word2vec. I think it will be a little better if this is also normalized.
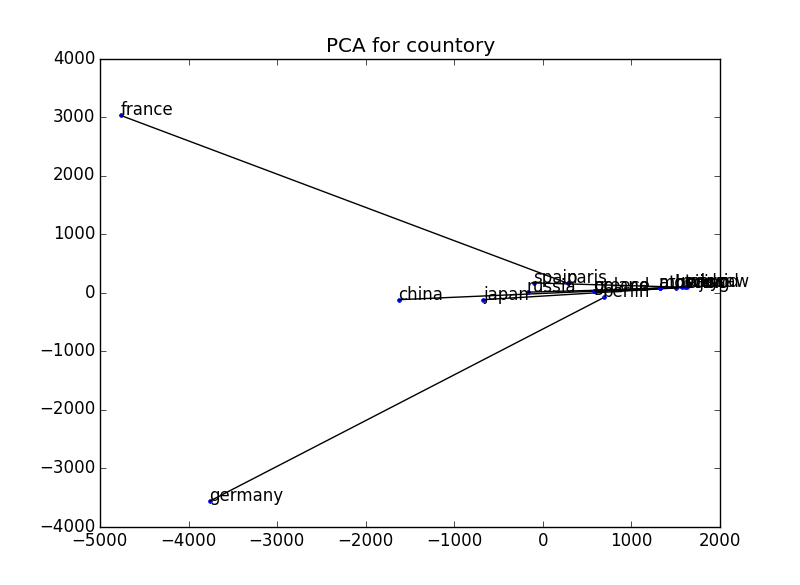 2297 3D → 2D
2297 3D → 2D
- At the time of visualization, the dimension of the vector is reduced to two dimensions by using principal component analysis. Reference: http://breakbee.hatenablog.jp/entry/2014/07/13/191803
Example in a book:


Try application 3: Calculation of meaning
If the meaning is properly expressed as a vector, you should be able to calculate the meaning.
・ King --man + woman = queen (Q: What is a king for men for women? A: Queen) ・ Paris --France + Italy = Roma (Q: What is Paris for France for Italy? A: Rome)
If you add or subtract the vector as above, you can actually get the result of this operation.
Other conventional methods vs word2vec proper information
According to a study by Mikolov et al., In order to measure the ability of this addition and subtraction, tests such as "Athene --Greece + Oslo is correct if it becomes Norway" showed that the correct answer rate was 9% or 23% with the conventional method. However, the Skip-gram model implemented in word2vec seems to have greatly improved the accuracy rate to 55%. ”
Excerpt :: Yasukazu Nishio. “Natural language processing with word2vec”
How word2vec works
Abbreviation
Image of how word2vec works
This image and description helped me a lot.
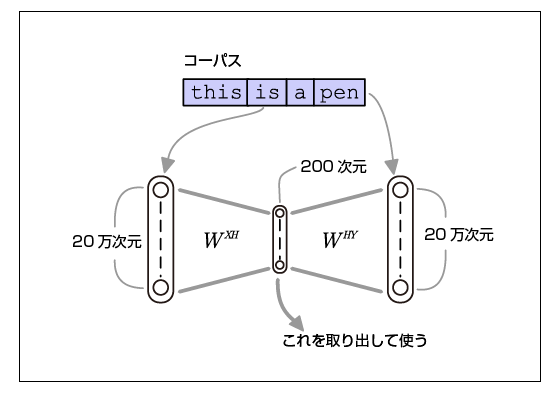
"The feature is to put the same data in both input and output. If you do that kind of learning, you might think that a boring neural network (identity map) that just outputs the same thing as the input will grow. The key to this method is that the size of the hidden layer is set so small that it cannot learn the conformal map. Therefore, the Autoencoder learns to pack as much information as possible into a limited hidden layer, and as a result, the weight of the input layer → hidden layer is a low-dimensional vector representation of the characteristics of the input data. The problem that the neural network is learning is not the problem that you want to solve, but the distributed expression that the neural network creates by letting the neural network solve the difficult problem is valuable. Omission If the number of vocabulary is 200,000 dimensions, the middle layer of 200 dimensions has only 1/1000 dimension. Under this harsh situation, learning is done to increase the accuracy rate of the prediction problem "guess the surrounding words". In this way, conversion is performed so that words with similar "degrees of appearance frequency of surrounding words" become vectors with close distances. ”
Excerpt :: Yasukazu Nishio. “Natural language processing with word2vec”
Implementation
・ Around word2vec: gensim -When visualizing, the dimension of the vector is reduced to two dimensions by using principal component analysis. Reference: http://breakbee.hatenablog.jp/entry/2014/07/13/191803