A site to see when you want to read a machine learning paper but it seems difficult
I think that there are many people who want to learn the basics of machine learning as it is, read a dissertation as the next step, and challenge implementation.
However, we have created a portal site for those who find it difficult to look at the English Abstract even if they find a paper that they are interested in, where to read machine learning papers. It was.
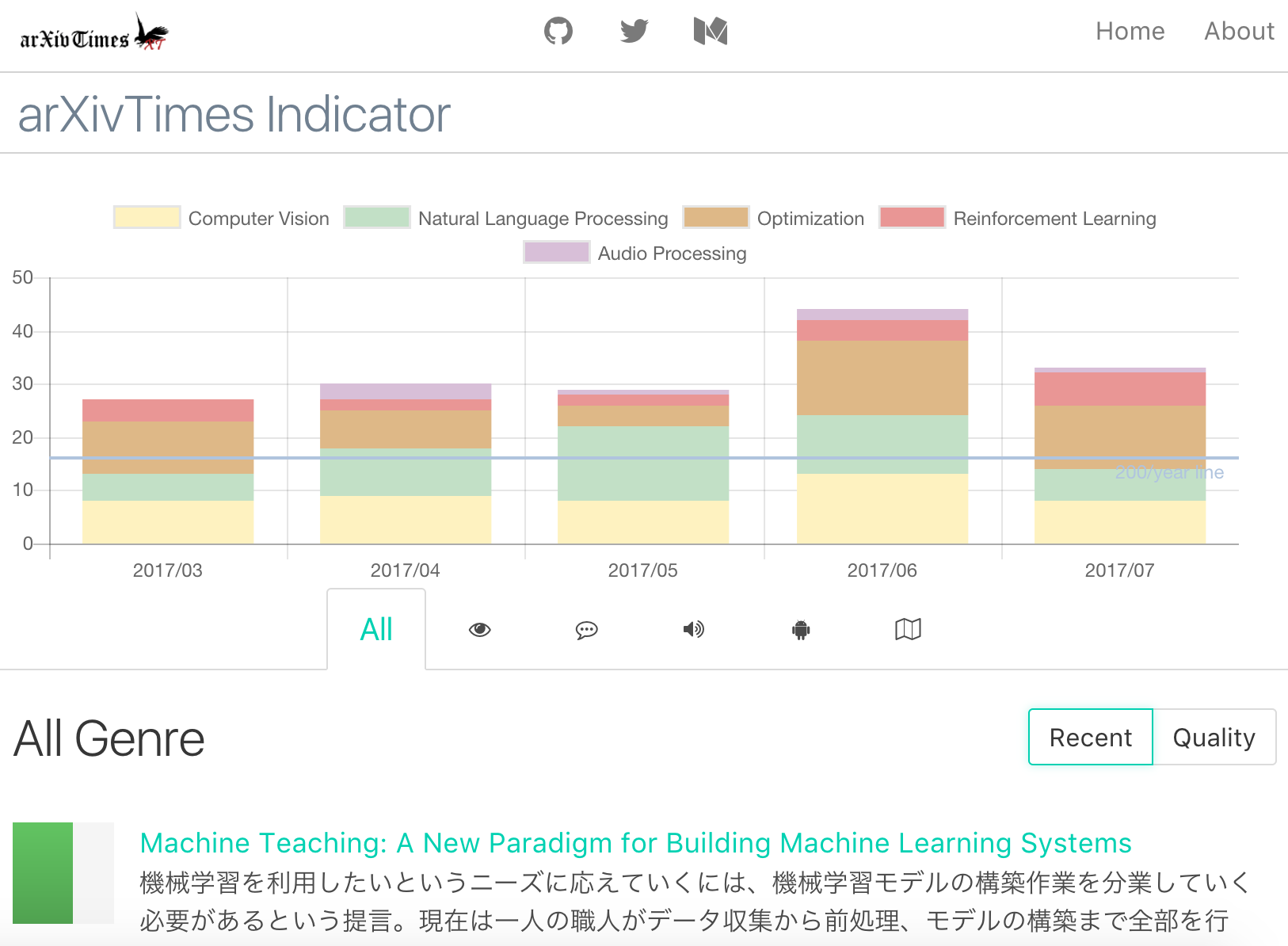
Earlier, I created GitHub Repository and Bot to share abstracts of papers related to machine learning. However, you can see all the posted content there.
In addition to being able to refer to each genre,
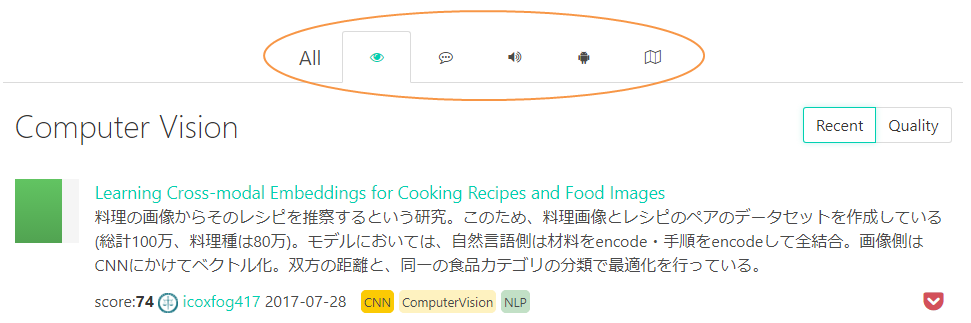
If you are using Pocket, you can also register with Pocket.

arXivTimes aims to form collective intelligence on machine learning research trends (available in Japanese). Therefore, we asked them to post more posts when we created this portal, and we also considered what we should do to improve the quality of the summary. We will also introduce the device.
To solicit posts
If you post at least one summary to arXivTimes GitHub repository, you will be able to refer to your personal page from this portal site.

On this personal page, you can see the number of posts so far and the total score (the score will be described later). In the pie chart on the left, you can see the percentage of the papers you are submitting by field, and you can see what fields the person is interested in and familiar with. The graph on the right shows the number of posts by month, and if you exceed the "200 / year line" drawn by the horizontal line every month, you will read 200 books a year. I hope you can use it to manage the progress of reading papers.
By the way, if you haven't posted yet, it will look like the following. Aiming to acquire a personal page, please post one first! I think.

Posting is possible from the button in the header.

Since we are sharing the summary as an issue on GitHub, we will post the summary in the form of posting an issue. Since there is an Issue Template, I will write a summary along with it (The format is a simplified version based on here) .. However, at least "in a word", "paper link", and "author / affiliated institution" are all that is required.
To improve the quality of posts
However, I also want to ensure the accuracy of the post. Therefore, I would like to evaluate whether it is a good summary ... but it is very difficult to evaluate the accuracy and comprehensibility of the content (since the amount of text is not so large, [previous method](http: http: It was difficult to use //qiita.com/icoxfog417/items/64ed466afee6682936c3) as it is).
Therefore, we are currently displaying the evaluation of people who can take it mechanically, specifically ** the deviation value calculated by using the number of likes + 2 * retweets attached to the tweet of the post as a score **. The purpose of doubling retweets is to place more emphasis on the fact that it is judged that there is no problem in spreading it to people (although the value of doubling is appropriate ...). This is the value displayed as "score".

Although it is displayed in a fairly prominent position in the post, this is a manifestation of the stance of wanting to ensure the accuracy of the content. By the way, there are quite a lot of posts by me, but as you can see, some of them have bad scores. I try to make sure there are no mistakes when posting, but I think that mistakes often occur.
Currently posted issues have few comments, but if you can point out the post and discuss the content, you can use it to evaluate the summary. Therefore, ** I would appreciate it if you could actively comment on the post **.
Welcome Contribution
The source code of the portal site created this time, arXivTimes Indicator, is available on GitHub.
(It will be encouraging if you give me a Star m (_ _) m)
If you have any requests, please feel free to contact us via Issue. Of course, we also welcome correction pull requests. We haven't supported it yet, but if you want to manage the papers you read in the same way in the laboratory or company, you can fork the GitHub repository of arXivTimes and rewrite the url of the contents to operate it as your own portal site. I think (although the calculation part of score tends to be a problem).
We hope this will help you take the "next to the tutorial" step in machine learning. Also, if you have already taken the next step, we are looking forward to your contribution!
Recommended Posts