[JAVA] This and that of exclusive control
This article is the 23rd day article of System Engineer Advent Calendar 2016 --Qiita. Yesterday was @yy_yank's Let's test normally without hesitation .. Tomorrow is @koduki.
Introduction
When creating an application that can be touched by multiple users, control when data is updated at the same time is inevitable.
I have to think about this control from various points of view such as thread safety and simultaneous update, but I couldn't organize it neatly in myself.
So, I tried to organize the exclusive control when it is updated at the same time at this opportunity.
Before
--The language used for the explanation is Java. --I'm using something like a sequence diagram for explanation, but it doesn't follow the strict definition of UML. I'm just using sequence diagrams because it's easy to draw, so don't worry if you follow strict notation rules and look at the atmosphere. ――It's just a summary of my experience and knowledge, so it's not a best practice. I would appreciate it if you could tell me if you say "I am doing this" or "This is dangerous for XX reasons, so XX is better".
Classify "updated at the same time" cases
| Number of requests | |||
|---|---|---|---|
| single | Multiple | ||
| Update target data Number of processes | single | 1 | 3 |
| Multiple | 2 | 4 | |
Even if you say "updated at the same time" in one word, I think there are multiple cases.
This time, as a result of thinking about what kind of cases can be "updated at the same time", I came to the conclusion that it can be classified as above (completely selfish. Maybe there is already such a thing? ).
I will explain each word.
** Axis 1: Number of processes updating the target data ** The number of programs that update the data. A process is an image of an OS process. For Java programs, for example, the number of JVM processes running.
A single process is a case where only one middleware process such as Tomcat or GlassFish is started and the application is running on it. On the other hand, multiple processes is a case where multiple server processes are started and clustered.
It may be accessed from a batch or other web application, but for the time being, we will proceed with the case of a cluster environment for the sake of simplicity.
** Axis 2: Number of requests ** The number of requests executed in a series of update processes.
A single is a case where data reference → update is completed with one request. On the other hand, multiple cases are cases where there is a reference request first, and then an update request.
When these two axes are multiplied and classified, they are as follows.
** Category 1: Single process request **
This is a case where multiple users send update requests to a web application running in a single process at the same time.
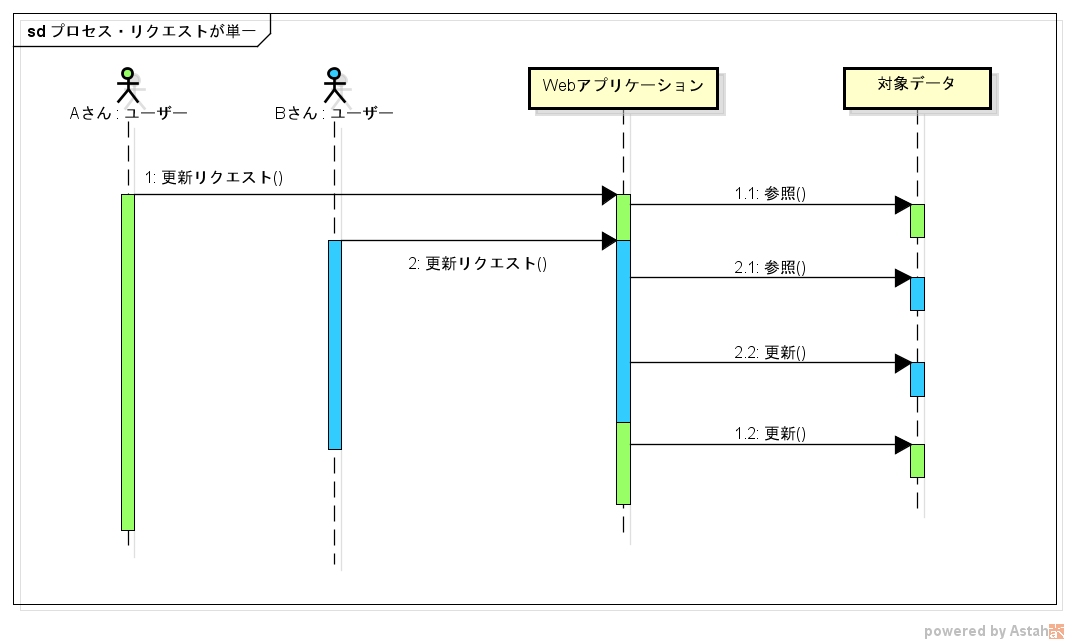
In this case, especially when the target data is the value of the instance field, the focus is on ** thread safe **.
** Category 2: Multiple processes / single request **
This is a case where multiple users send update requests to a clustered Web application at the same time.

In this case, in addition to the correspondence of classification 1, ** exclusive control that can be executed across multiple processes ** is required.
- If the target data is closed in each process, it will be classified as Category 1 even in the cluster configuration.
** Category 3: Single process / Multiple requests **
This is a case where multiple users update data at the same time in a web application running in a single process.

If the request spans multiple times, a control often referred to as ** optimistic concurrency control ** is involved. Also, since each update request has the same conditions as Category 1, it is necessary to take measures for that (I feel that it is easy to forget this).
** Category 4: Multiple process requests **
This is a case where Category 3 Web applications are clustered.

Perhaps this is usually the case.
Until now, I have been ambiguous about the boundaries of this classification. For example, "Oh, now I'm implementing optimistic exclusive control (Category 3 and 4), but there's a story about thread safety (Category 1)?"
By classifying as above this time, the moyamoya around here was a little refreshed personally.
Next, I will organize more detailed stories about each classification and specific countermeasures.
Single process x Single request </ span>
This is the simplest case, and it involves the basic problem of writing a multithreaded program. Therefore, the method of dealing with this case is also required for other categories 2, 3 and 4.
For simplicity, the sample implementation is written in a standalone Java program rather than in a web app. But in the end, it's the same story because web apps also run multithreaded.
Classes that cannot be used as they are under multithreading
Java can be processed in multiple threads. However, there are some classes in the standard API that cannot be used as they are under multithreading.
The most famous ones are SimpleDateFormat and Collection classes such as HashMap. .com / javase / jp / 8 / docs / api / java / util / HashMap.html)?
For example, if you look at the implementation of SimpleDateFormat, it looks like this (JDK8).
DateFormat.java
public abstract class DateFormat extends Format {
...
protected Calendar calendar;
...
SimpleDateFormat.java
public class SimpleDateFormat extends DateFormat {
...
private StringBuffer format(Date date, StringBuffer toAppendTo,
FieldDelegate delegate) {
// Convert input date to time field list
calendar.setTime(date);
...
}
...
The format (Date, StringBuffer, FieldDelegate) method is the final method executed when you call the format (Date) method.
At the beginning, the value of the instance variable calendar of the parent class DateFormat is rewritten with setTime ().
The format () method then generates a date string based on the time information set in calendar and returns.
So it feels dangerous if multiple threads use the format (Date) method at the same time.
Let's try creating the following code and running it.
Main.java
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
private static void printDate(int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual = sdf.format(cal.getTime());
System.out.println(expected + " = " + actual);
}
}
I have created two threads and used a single SimpleDateFormat instance to output a date string.
When you do this, you get:
Execution result
* 1st time
Date(2015/10/11) = 2016-12-31
Date(2016/12/31) = 2016-12-31
* Second time
Date(2015/10/11) = 2015-10-31
Date(2016/12/31) = 2016-12-31
* Third time
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2015-10-11
I'm outputting completely wrong values and I get different results each time (it may behave differently depending on the environment in which it is run).
This issue occurs because multiple threads are referencing or modifying a single instance field called calendar.
It looks like the figure below.

First, Thread1 executesformat ()to rewrite the value of calendar. However, immediately after that, Thread2 executesformat (), so the value of calendar is rewritten again. As a result, format () called by Thread1 will generate a string with the date information that Thread2 passed when callingformat ().
Anything that may not work properly when used under multithreading like this is described as ** not threadsafe **. Conversely, anything that works correctly under multithreading is described as ** threadsafe **.
Which classes are thread-safe and which are not thread-safe are usually described in the Javadoc. (As far as I know, the standard API is always described, but the OSS library etc. may not be written at all depending on the thing)
In the SimpleDateFormat Javadoc that I used earlier as a non-thread-safe class, I wrote: It has been.
Date formats are not synchronized. Oracle recommends that you create a separate format instance for each thread. If multiple threads access the format in parallel, it must be synchronized externally.
Also, as an example of a thread-safe class, Javadoc of Pattern class has the following: It is described as.
Instances of this class are immutable and can be used in parallel by multiple threads.
How to prevent
As far as I know, there are three ways to deal with it.
- Exclusive control of processing with
synchronized[^ 1] - Create an instance of a class that is not thread-safe for each thread
- Use thread-safe classes
[^ 1]: There seems to be a way to use Lock. However, I am ashamed to say that I have never used it, so I will omit it. I'm sorry! (I want to study properly someday)
Exclusive control of processing with synchronized </ span>
Exclusive control means that when multiple threads try to execute the same process, only one thread can execute the process.

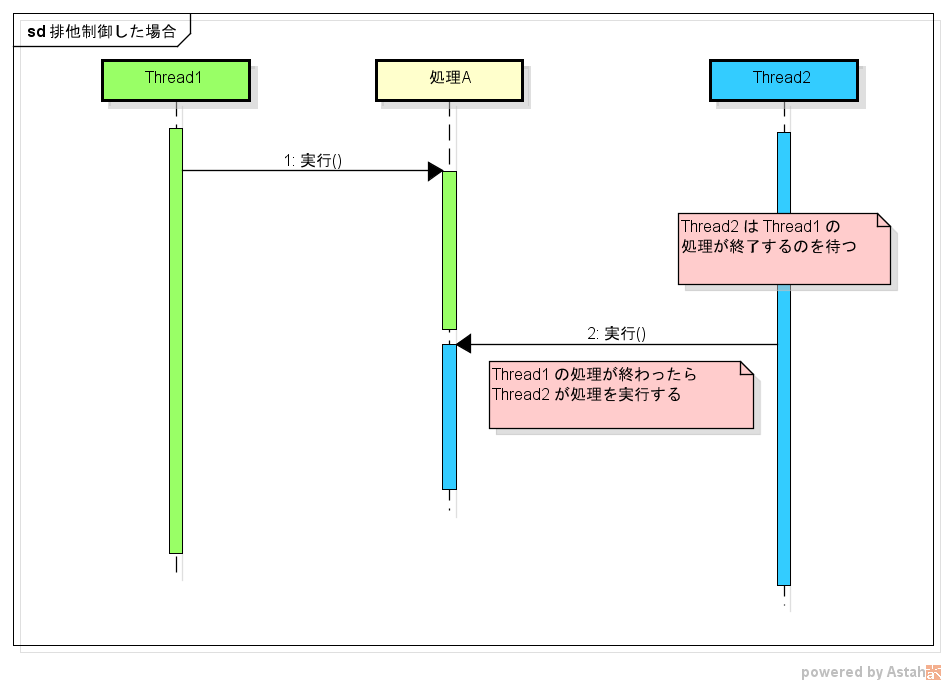
If exclusive control is not performed, one process can be executed by multiple threads at the same time. With exclusive control, while one thread is processing, the other thread will wait.
In Java, exclusive control can be achieved by using synchronized.
Main.java
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
//★ Added synchronized to method declaration
synchronized private static void printDate(int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual = sdf.format(cal.getTime());
System.out.println(expected + " = " + actual);
}
}
I prefixed the printDate () method in the previous implementation with synchronized. This method is now in exclusive control.
When you do this, you get:
Execution result
* 1st time
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
* Second time
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
* Second time
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
It looks like it's working.
However, exclusive control using synchronized will stop the execution of other threads, which may reduce performance. The longer the thread wait time, the less the benefits of multithreading.
In order not to stop the processing of other threads as much as possible, it is better to enclose only the parts that really need exclusive control with synchronized.
In this case, the only problem is calling format () on SimpleDateFormat. So you can also do the following:
Main.java
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
private static SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
private static void printDate(int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual;
//★ Specify an instance of SimpleDateFormat and format()Exclusive control only
synchronized (sdf) {
actual = sdf.format(cal.getTime());
}
System.out.println(expected + " = " + actual);
}
}
In addition to being a method modifier, synchronized can also be used as a block as shown above.
In that case, write it as synchronized (lock object) {process}.
A lock object is an object that controls the threads that can perform the processing inside the synchronized block. If a thread comes in that has the same object as the thread that is already executing the synchronized block, it will be put to wait.
For those who are not sure, it may be easier to imagine the thread as a person and the lock object as a flag as follows.
Only the person (thread) who has the flag (lock object) can work. Some people are competing for the flag, and only the first person to get the flag will do the work. In the meantime, others who couldn't get the flag are put on standby. When the first person to pick up the flag finishes the work, the flag is put back in place. Then, the other people who had been waiting until then resumed the flag battle all at once. Then the person who gets the flag will start working. Those who couldn't get the flag will be put on standby again.
Instantiate non-thread safe classes on a per-thread basis
The problem in the first place is that multiple threads share an instance of a class that is not thread-safe. So if you instantiate each thread, this problem will disappear.
Main.java
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
private static void printDate(int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
//★ Set SimpleDateFormat to new in the method
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String actual = sdf.format(cal.getTime());
System.out.println(expected + " = " + actual);
}
}
Changed to do new of SimpleDateFormat in printDate () method.
This will cause SimpleDateFormat to be new for each thread running printDate (). As a result, the problems that were in the first implementation do not occur.
The figure looks like the following.

This eliminates thread waits compared to synchronized.
So why not always create an instance without using synchronized? That's not the case.
If the constructor is very slow, creating multiple instances may be slower than exclusive control with syonchronized.
Well, the constructors for many classes aren't that slow, so I think it's often simpler and easier to create an instance each time. If you want to know exactly which is faster, you will need to measure by class.
By the way, at first I thought I would write "If you make it a local variable, it will be thread-safe", but when I think about it, I realized that even a local variable would not work if I implemented it as follows, so I stopped it (<span). class = "small"> Maybe this is not a local variable? </ Span>).
Main.java
package sample;
import java.text.SimpleDateFormat;
import java.util.Calendar;
public class Main {
public static void main(String[] args) {
//★ Although the variable itself is declared locally
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
new Thread(() ->
//★ After all, it is referenced by multiple threads
printDate(sdf, 2015, 10, 11)
).start();
new Thread(() ->
//★ After all, it is referenced by multiple threads
printDate(sdf, 2016, 12, 31)
).start();
}
private static void printDate(SimpleDateFormat sdf, int year, int month, int day) {
Calendar cal = Calendar.getInstance();
cal.set(Calendar.YEAR, year);
cal.set(Calendar.MONTH, month - 1);
cal.set(Calendar.DAY_OF_MONTH,day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual = sdf.format(cal.getTime());
System.out.println(expected + " = " + actual);
}
}
So in the end, you have to worry about "Is this instance created for each thread?"
Use thread-safe classes
Some standard APIs have thread-safe classes that have similar functionality to non-thread-safe classes.
Regarding date processing, Date and Time API has been added from Java 8. ..
There is a class called DateTimeFormatter. This class provides the same ability to format the date and time as SimpleDateFormat (and also the ability to instantiate a date string such as LocalDate).
This class is thread-safe, so you can share and use a single instance even under multithreading.
The Javadoc says:
This class is immutable and thread safe.
Using the Date and Time API, the implementation using SimpleDateFormat so far can be rewritten as follows.
Main.java
package sample;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
public class Main {
private static DateTimeFormatter formatter = DateTimeFormatter.ISO_DATE;
public static void main(String[] args) {
new Thread(() ->
printDate(2015, 10, 11)
).start();
new Thread(() ->
printDate(2016, 12, 31)
).start();
}
private static void printDate(int year, int month, int day) {
LocalDate date = LocalDate.of(year, month, day);
String expected = "Date(" + year + "/" + month + "/" + day + ")";
String actual = formatter.format(date);
System.out.println(expected + " = " + actual);
}
}
Of course, the execution result is
Execution result
* 1st time
Date(2016/12/31) = 2016-12-31
Date(2015/10/11) = 2015-10-11
* Second time
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
* Third time
Date(2015/10/11) = 2015-10-11
Date(2016/12/31) = 2016-12-31
It's working fine.
In this case, you only need to create one instance, and there is no thread waiting, so it seems to be good for performance.
(It may be useless if foramt () of DateTimeFormatter is actually deadly slow, but it seems unlikely) </ span>
Perfect with thread-safe classes? </ span>
If thread-safe classes can solve all multithreading problems, that's not the case.
Depending on how you use it, you will still need synchronized.
For example, consider a class called HashMap. This class is not thread safe. Infinite loops can occur when updated from multiple threads. [^ 2]
On the other hand, ConcurrentHashMap added in Java 1.5 is thread-safe. This class can be safely used even under multithreading.
However, writing the following implementation causes problems under multithreading even with the thread-safe ConcurrentHashMap.
Main.java
package sample;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class Main {
private static Map<String, Integer> map = new ConcurrentHashMap<>();
public static void main(String[] args) throws Exception {
new Thread(() ->
add(1)
).start();
new Thread(() ->
add(2)
).start();
Thread.sleep(100);
System.out.println(map.get("foo"));
}
private static void add(int n) {
Integer total = map.getOrDefault("foo", 0);
System.out.println("total = " + total + ", n = " + n);
map.put("foo", total + n);
}
}
The value is obtained from Map with the key"foo", and the result of adding the specified number is reset.
The feeling is that ʻadd (1) and ʻadd (2) are executed, so I want 3 to be output as a result.
But when I run this, the result is:
Execution result
* 1st time
total = 0, n = 1
total = 0, n = 2
2
* Second time
total = 0, n = 1
total = 0, n = 2
2
* Third time
total = 0, n = 1
total = 1, n = 2
3
The result may not be 3, but may be 2 (maybe even 1?).
This happens because ʻadd (1) executes ʻadd (2) before Map is set to 1.
The thread safety guaranteed by ConcurrentHashMap is only in the class. It doesn't guarantee thread safety for implementations outside of that class (which is obvious).
So using a thread-safe class doesn't mean it's all OK. After all, programmers must be aware that it's okay for the implementation to run from multiple threads at the same time.
In the above example, the problem is that other threads can do the same thing between getting the current value from Map and reflecting the result.
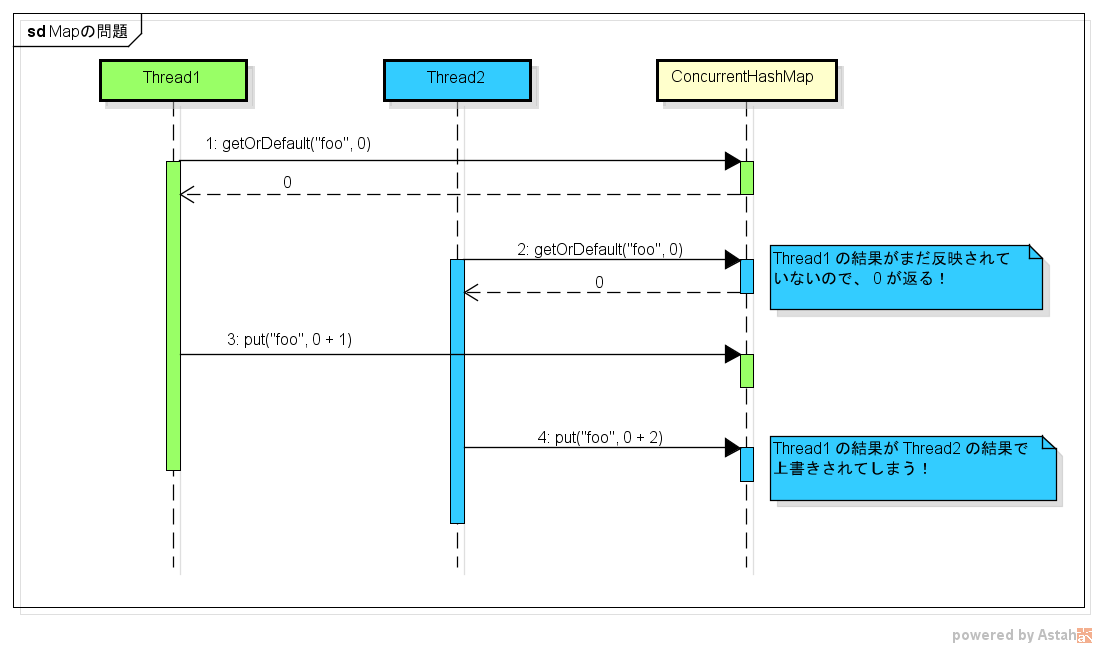
Therefore, while one thread is performing a series of processing, exclusive control must be performed so that other threads cannot process.
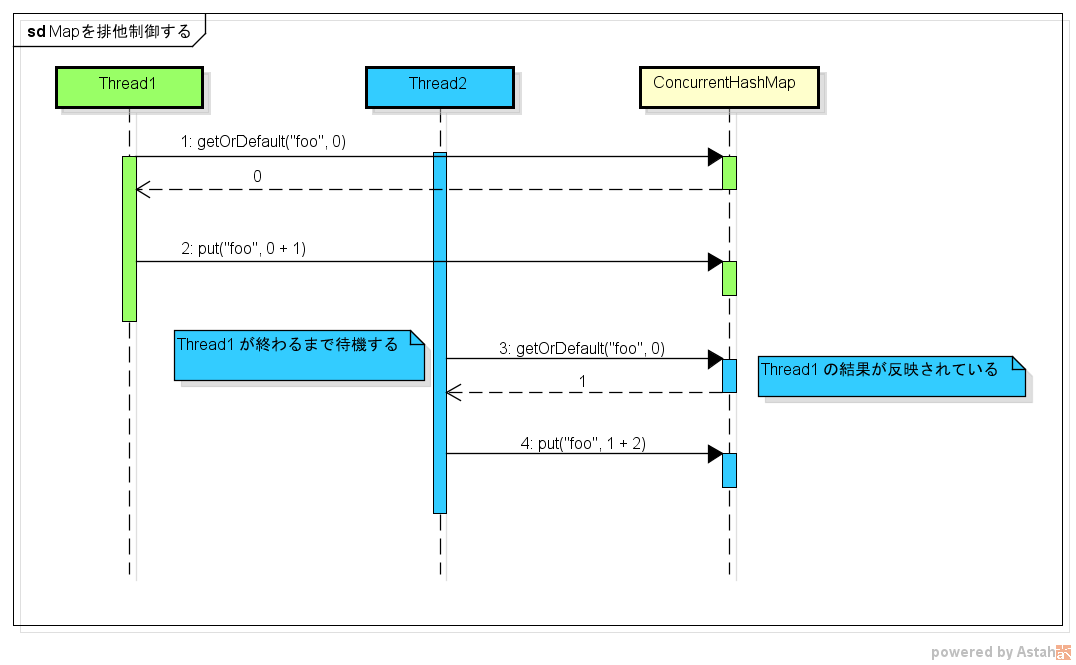
The implementation can be modified as follows so that it works as intended.
Main.java
package sample;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class Main {
private static Map<String, Integer> map = new ConcurrentHashMap<>();
public static void main(String[] args) throws Exception {
new Thread(() ->
add(1)
).start();
new Thread(() ->
add(2)
).start();
Thread.sleep(100);
System.out.println(map.get("foo"));
}
// ★ add()Add synchronized to method
synchronized private static void add(int n) {
Integer total = map.getOrDefault("foo", 0);
System.out.println("total = " + total + ", n = " + n);
map.put("foo", total + n);
}
}
We've added synchronized to the ʻadd ()method, which gives it exclusive control. As a result, you can be assured that3` will be output as intended.
It's been a long time, but thread safety is an unavoidable part of creating multithreaded programs, including web apps.
Moreover, this is just the basics. If you want to actually make a web application, you will need to support the following categories 2, 3, and 4.
Multiple processes x single request </ span>
When it comes to business apps, I think that clustering is often adopted for reasons such as improving performance.
In that case, the above-mentioned classification 1 (single process / single request) correspondence is not enough.
This is because synchronized locks the processing of threads on a single JVM, so you cannot have exclusive control over threads running on other JVMs.
Therefore, a mechanism to realize exclusive control across processes is required.
As far as I know, there are the following methods.
--Lock using a file --Use the DB locking mechanism
Since it is exclusive control across the JVM processes, it is inevitably a method that uses something outside the JVM.
Lock using a file
This is a method to realize the lock by outputting the file locally on the machine where the application is running.
You can control it by yourself by checking whether the file exists, or you can control it by using the file locking mechanism of the OS.

For Java, go to FileCannel class and [lock ()](http: //: // docs.oracle.com/javase/jp/8/docs/api/java/nio/channels/FileChannel.html#lock--) and [tryLock ()](http://docs.oracle.com/javase/jp / 8 / docs / api / java / nio / channels / FileChannel.html # tryLock--) There is a method for file locking. With this, you can use the file locking mechanism of the OS to achieve exclusive control across multiple JVM processes.
However, this file lock is for exclusive control between different JVM processes.
It cannot be used for exclusive control of multiple threads in the same process. Exclusive control between threads still requires synchronized.
(When multiple threads try to acquire the same file lock, ʻOverlappingFileLockException` is thrown)
The file locking method requires all application processes to be running in an environment where they can access the same file. It may not be impossible to mount it via the network, but I feel that the environment construction will be complicated.
reference
Use the DB locking mechanism
If your system uses DB, there is a way to take advantage of the DB locking mechanism. In my experience of development, this method was basically adopted.
For example, if you are using Oracle, you can get a row lock by adding FOR UPDATE to the SELECT statement (I think this is usually the case for non-Oracle).
If multiple transactions [^ 3] try to lock the same row, the later one will be made to wait.
The waited transaction is resumed when the transaction that acquired the lock first ends (commit or rollback).
It's just like synchronized gives exclusive control of threads (in this case, the locked row corresponds to a locked object with synchronized).

This method can also be used for exclusive control of multiple threads in the same process.
If the update target is DB data, I think that this method is often adopted instead of synchronized even in the case of classification 1.
[^ 3]: Please think of it as a thread here.
Supplement: Decide what to lock
When there are multiple update targets
When performing exclusive control, if synchronized, select the lock object, and if it is a DB row lock, select the target record.
If there is only one data to be updated, you can simply specify the target data. However, if the target data spans more than one, [Deadlock](http://e-words.jp/w/%E3%83%87%E3%83%83%E3%83%89%E3% It is necessary to pay attention to 83% AD% E3% 83% 83% E3% 82% AF.html).
As far as I know, this issue can be addressed in one of the following ways:
- Make sure that the data lock order is always the same
- Set the lock target to one
For example, if you want to lock both the "Order" table and the "Order Details" table, be sure to lock them in the order of "Order" → "Order Details". If you mistakenly take the lock in the order of "order details" → "order", a deadlock may occur. As the number of tables and update functions to be updated increases, it becomes difficult to keep the order accurately.
2 does not lock the "order details", but always locks only the parent "order". It's simpler than 1 because you don't have to think about the order. However, even if the update target is only the "order details", you must remember to acquire the lock of the parent "order". Also, as the number of tables to be updated increases, it may become difficult to understand "Which parent data must be locked when updating this data?". In that case, if you have defined something like DDD Aggregation , It may be easy to understand because you only have to lock the root entity.
In case of duplicate check
If there is a value in the input field that must be unique in the system (login ID, master data code value, etc.), you must check that the value is not already registered.
In this case, there is no specific object or record to update, so a wider range of locks, such as table locks, is needed.
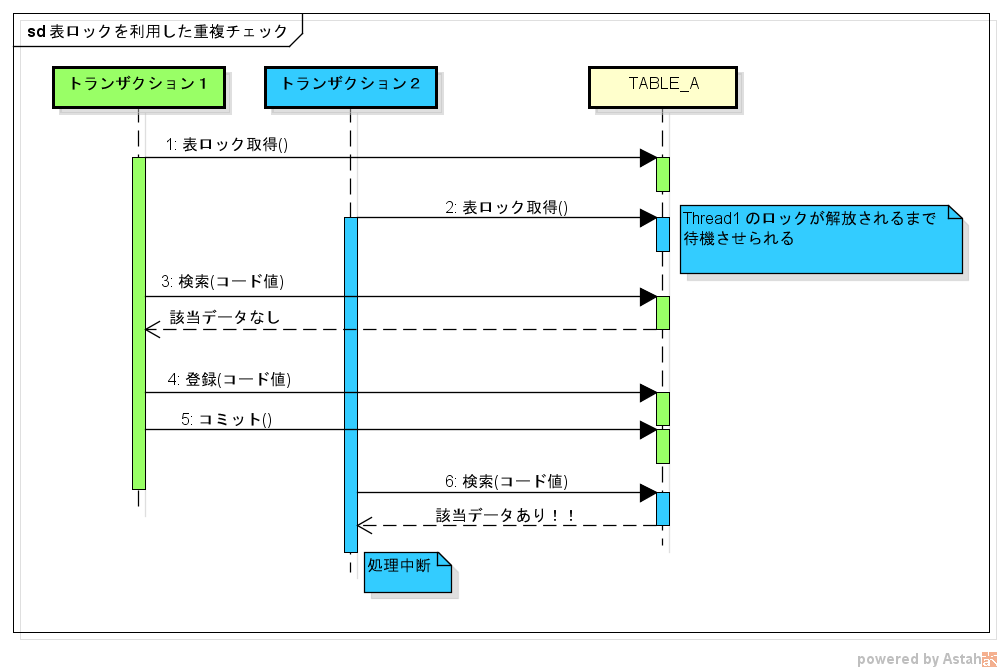
Duplicate check is a process that is mainly required for "registration". If you get caught up in the words "simultaneous update" and think "should I be careful only when updating?", I think I just forget about it (only me?)
Check for duplicates using the UK
If you have specified a unique key constraint (UK) for your DB, it seems easier to let the DB do the duplication.
However, the projects I've been involved with haven't been duplicate checked in the UK.
When I think about the method using the UK again, I feel that it is not good. Can you think of the following reasons?
- Since handling by error code is required, exception analysis is required and it depends strongly on the DB product.
- Performance is not good as it will be handled with exceptions
But for 1,
--In the first place, switching DBs does not usually occur, and if it does occur, it will affect a wider range, so it is strange to worry only about error code handling. --Anyway, SQL tends to depend on the DB product.
I don't think it's a strong reason to think about it.
Also, if you use Spring Framework, Abstract exception representing key duplication error Since it seems to be thrown, it seems that exception handling that does not depend on the DB product will be possible.
Regarding 2, I don't think it will be a problem unless it is executed many times in a loop.
What is the general public doing?
- By the way, I think that it may not be possible to set a unique key due to adult circumstances ^ 4.
[^ 4]: UK cannot be set because logical deletion by flag is used. .. ..
Multiple requests
The difference between categories 3 and 4 is the difference in the number of processes, but I think that the necessary measures will be the same as in [Category 2](# case2). Therefore, here we will focus on the problems that occur when requests are divided into multiple requests and how to deal with them.
The ConcurrentHashMap story above (#concurrent_hash_map) can be thought of by replacing threads with ** application users ** and Map with ** database tables **.
Suppose you have two users, A and B. When Mr. A and Mr. B display the screen at almost the same time, the value in the table was 0, so they are displayed as 0 respectively. Mr. A entered a value of + 1 in 0 and saved it, and Mr. B entered a value of + 2 in 0 and saved it.
If you have no control, the value that will eventually be written to the table will be the one that was updated later.

When a series of update processing spans multiple requests in this way, exclusive control cannot be performed only by synchronized or DB row lock.
Therefore, another measure is required.
How to respond
The disappearance of either change is not a favorable behavior, especially for business applications that handle important corporate information. As far as I know, there are three workarounds for this issue:
- Allow simultaneous updates
- Update work can be done by only one user
- Check if it is updated at the same time when saving
Allow simultaneous updates
--In operation, there is only one user who uses the update function. --The data is updated very infrequently, and there is no problem even if you win afterwards.
Even if it is a business application that handles important information, not all of them are important. Some of this may be relatively loose data ( may not be available on all systems ... </ span>). For such data update function, if you try hard and put in control for simultaneous update, cost performance may deteriorate. In this case, I think that allowing simultaneous updates is an option.
Of course, it is necessary to consult with the customer to decide whether it is okay to win later.
Update work should be done by only one user
It is a method to implement a mechanism that exclusive control of threads by synchronized as an application mechanism.
I feel that it is called pessimistic exclusive control.
Only the user who first started using the update feature can continue working, and no one else can start working. It's just like a VSS checkout or an SVN needs lock.

There is no extra overhead such as "another update is being done without the knowledge of one user and this edit was wasted". Therefore, in the case of a function that is updated frequently at the same time, pessimistic exclusive control may improve the overall performance when viewed as a business.
However, pessimistic concurrency control is considerably more complicated to implement than optimistic concurrency control described later. Perhaps because of that, I haven't seen many cases that have actually been adopted. The only thing I remember is the Weblogic Administration Console (https://docs.oracle.com/cd/E28613_01/web.1211/b65923/adminconsole.htm#CACHEJDB) (maybe I just didn't realize it). There may be various).
I have never implemented pessimistic concurrency control because all the projects I have been involved in have been optimistic concurrency control. If you want to realize pessimistic exclusive control, I feel that the control is roughly as follows.

Record information about whether or not you are editing in the DB, and search that information when you start editing to determine whether or not to start editing.
Sounds complicated.
further,
――What if Mr. A goes on a long vacation while editing? --Are there any expiration dates for locks? --You have to make sure to unlock when you log out or out of session ――I don't log out, but what if I can switch pages? --To be able to cancel editing
- etc...
It seems that you often have to consider various things just by thinking a little. (* I actually created it, it was very difficult ...)
Check if it is updated at the same time when saving
This is a method of not acquiring a lock at the beginning of editing and checking if it has been updated by another user when sending an update request.
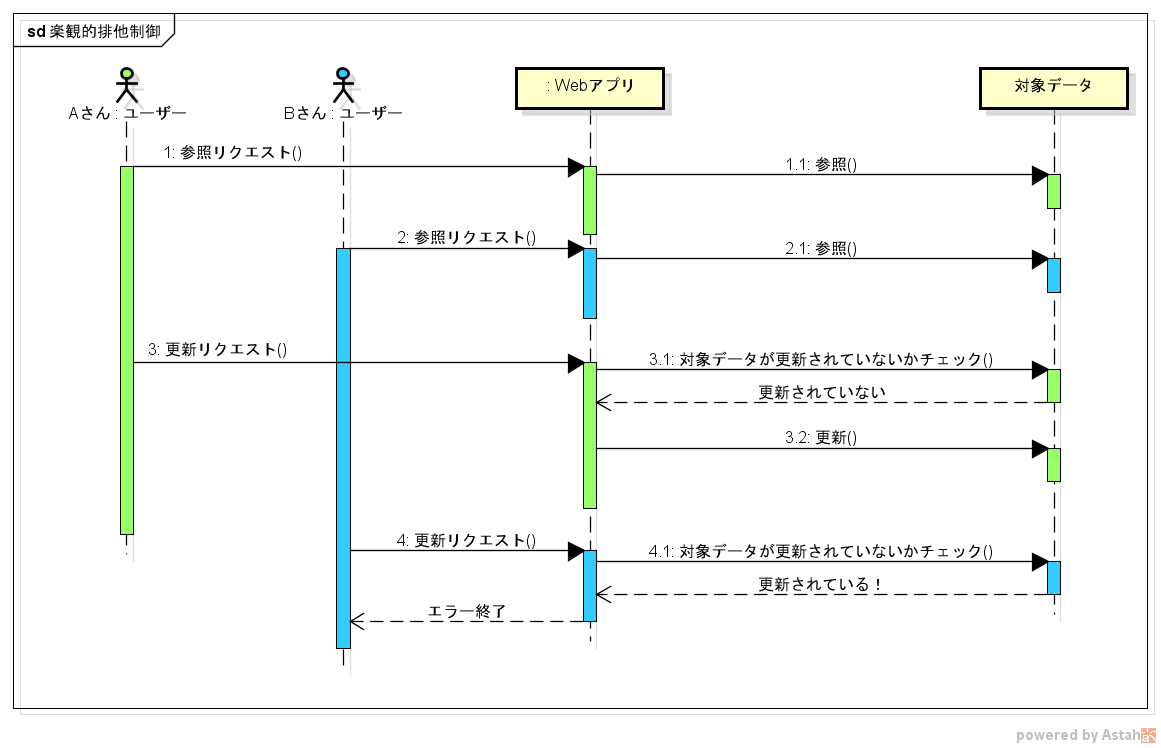
Whether or not the target data has been updated is often realized by having the update date and time in the target data.
When you first receive a reference request, be sure to return the modification date and time to the user as well. And when you send an update request, you also pass the update date and time you received at the time of the reference request. If the update date and time received from the user <the update date and time of the latest target data, it means that the target data has been updated by someone else. In that case, the application should return an error to the user.
It should be noted here that the "update request" itself is the same as [Category 1](# case1) (2 in a cluster environment). Therefore, it is necessary to tightly control the update request exclusively. If you are relieved to just check the date, the data will not be updated correctly when update requests come at the same time.
Implementation example </ span>
Of the stories so far, I actually made a sample application for pessimistic concurrency control and optimistic concurrency control of categories 3 and 4.
Download sample.jar from here.
The server will start with java -jar sample.jar, so accesshttp: // localhost: 8080 /in your browser.



Is it a summary or an impression?
There are many things to consider when the data is updated at the same time. If you look around this area, you will often find information on various levels such as thread safety, DB row lock, and optimistic concurrency control. For this information, I was in a state of being uncomfortable with the boundaries or relationships between them.
As a result of rearranging it in my own way this time, it became as above. Personally, it's pretty neat.
I wondered if the basics would start from a state like Category 1 and be applied step by step and in a complex manner depending on the characteristics of the application (cluster, etc.).
reference
-Exclusive control to prevent simultaneous data update (1/3): CodeZine -[Pessimistic exclusive control and optimistic exclusive control-How to deal with simultaneous updates | Ivystar](http://ivystar.jp/programming/pessimistic-exclusive-control-and-optimistic-exclusive-control-of-simultaneous- update-solution /) -[Exclusive control-Wikipedia](https://ja.wikipedia.org/wiki/%E6%8E%92%E4%BB%96%E5%88%B6%E5%BE%A1#.E7.95.99. E6.84.8F.E3.81.99.E3.81.B9.E3.81.8D.E7.8F.BE.E8.B1.A1.E3.81.A8.E6.80.A7.E8.B3.AA) -Table Lock Types and Interrelationships--Basics and Mechanisms for Mastering Oracle Oracle
Recommended Posts