Abus de réflexion
La réflexion et l'abus des techniques qui utilisent la réflexion (par exemple, DI) rendent difficile l'analyse du code source.
DI a pour effet d'affaiblir le degré de couplage entre les classes et de rationaliser le développement et les tests.
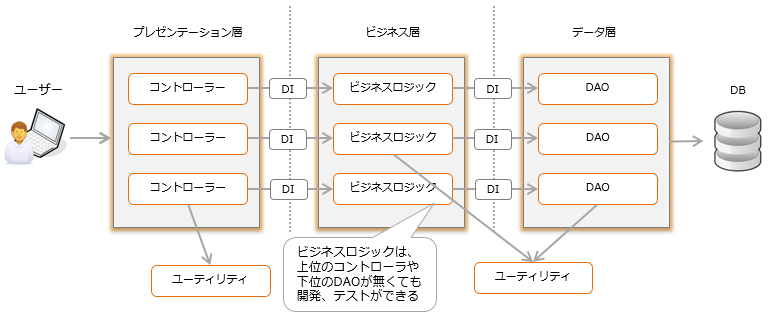
Cependant, il est donc difficile d'examiner les dépendances. Même si vous vérifiez la hiérarchie des appels avec un IDE tel qu'Eclipse, vous ne pouvez pas détecter les appels par DI (réflexion). Pour corriger un bogue et voir si le correctif affecte d'autres fonctionnalités, vous devez vérifier tous les appelants. Il n'y a pas de problème si la mise en œuvre montre clairement où le DI est utilisé, mais si ce n'est pas le cas, il sera difficile d'identifier la plage d'influence.
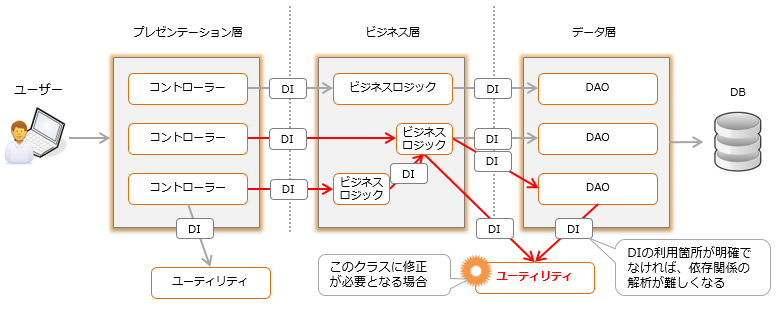
Vous pouvez également accéder aux méthodes privées en utilisant la réflexion. Je pense qu'aucun programmeur n'envisage même d'appeler par réflexion pour voir l'ampleur de l'impact de la modification de la logique d'une méthode privée. Vous ne feriez pas beaucoup de recherches chronophages, pensant qu'il ne pourrait pas y avoir de code aussi délicat. L'écriture de code délicat crée des risques.
Abus d'annotations
Les annotations sont un peu comme l'introduction d'une nouvelle grammaire, avec des coûts d'apprentissage. Cela peut être efficace pour améliorer la productivité, mais du point de vue de la maintenabilité, tout n'est pas bon.
Le code suivant utilise une bibliothèque appelée Lombok pour annoter et
public class Person {
private String firstName;
private String familyName;
public Person(String firstName, String lastName){
this.firstName = firstName;
this.lastName = lastName;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getFamilyName() {
return familyName;
}
public void setFamilyName(String familyName) {
this.familyName = familyName;
}
@Override
public String toString() {
return "Person(firstName=" + firstName + ", familyName=" + familyName + ")";
}
}
Cela peut être simplifié comme ça.
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.ToString;
@ToString
@AllArgsConstructor
@Data
public class Person
{
private String lastName;
private String firstName;
}
Il n'y a pas de méthodes getter, setter ou toString dans le code source, mais elles existent. C'est certainement plus facile à voir, et je pense qu'il est plus difficile de créer des bogues en raison d'erreurs ennuyeuses de copier-coller. Si vous avez besoin de beaucoup de ces objets pour un développement à grande échelle, Lombok sera une solution pour améliorer votre productivité de développement.
Cependant, ce dernier n'est pas immédiatement compréhensible pour les programmeurs sans connaissance de Lombok. D'un autre côté, aucun programmeur Java ne peut lire l'ancien code.
De plus, le traitement des annotations est souvent difficile à déboguer. Si vous voulez définir un point d'arrêt sur getFirstName (), beaucoup de gens ne savent pas quoi faire avec ce dernier. Selon l'EDI, vous ne pouvez pas simplement arrêter toString () en mode débogage ou voir l'implémentation detoString ()sans utiliser delombok.
Les frameworks et bibliothèques modernes ajoutent souvent leurs propres annotations, et leur utilisation en combinaison souffre de "l'enfer des annotations".
@PreAuthorize("#user.id == #u?.id")
public UserDTO access(@P("user") @Current UserEntity requestUser,
@P("u") @PathVariable("user-id") UserEntity user)
@PreAuthorize("#user.id == #uid && (#order == null || #order?.user?.id == #uid)")
public Message access(@Current @P("user") UserEntity user,
@PathVariable("user-id") @P("uid") Long uid,
@PathVariable("order-id") @P("order") OrderEntity order)
Je ne pense pas qu'il soit bon de créer facilement vos propres annotations.
Abus d'autres «magie noire»
Il existe de nombreuses techniques délicates en plus des réflexions et des annotations. Parmi eux, il vaut mieux éviter autant que possible d'utiliser une technique appelée «magie noire».
Par exemple, vous pouvez utiliser sun.misc.Unsafe pour réécrire un champ de classe statique final. Avec Javassist, vous pouvez réécrire directement le bytecode d'une classe compilée pour changer son comportement lors de l'exécution. La magie noire peut être une méthode efficace lorsqu'il n'y a pas d'autre moyen de la réaliser, ou lorsqu'il existe une certaine échelle, mais elle ne doit pas être utilisée inutilement.
Abus de cache
Les caches sont utilisés dans diverses parties du logiciel pour aider à réduire le temps de traitement. Cependant, cela peut également être une gêne lors de l'analyse. Étant donné que le comportement peut différer selon l'état du cache, il peut sembler que le comportement n'est pas régulier au moment de l'analyse. Par exemple, les mises à jour de données peuvent ne pas être immédiatement reflétées à l'écran, ou si une erreur d'accès à la base de données s'est produite ou non peut changer.
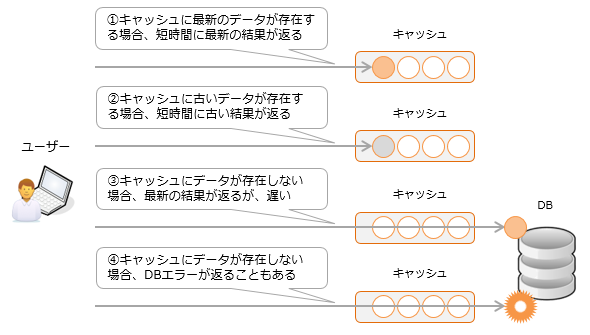
Cela peut également être un facteur de création de bogues complexes tels que des fuites de mémoire, vous pouvez donc envisager des options telles que la désactivation du cache lors du déploiement.
Abus de technologie
Si le programmeur maîtrise Java, il peut implémenter des applications Java. De plus, si vous maîtrisez Servlet / JSP, vous pouvez créer une application Web. Si vous maîtrisez Spring Boot, vous pouvez augmenter votre productivité de développement. Si vous maîtrisez Thymeleaf et Bootstrap, vous pouvez séparer la conception et la logique et améliorer la qualité et la lisibilité de votre conception. Si vous maîtrisez SAML 2.0 et Sprig Security, vous pouvez déléguer l'authentification à un système externe. Si vous connaissez JUnit et Gradle, vous pouvez automatiser les tests et la création. Il y a beaucoup d'autres choses qui peuvent être réalisées par l'apprentissage.
Cependant, le nombre de programmeurs qui peuvent tout faire est limité. Différentes personnes ont des normes de lisibilité différentes, mais plus vous travaillez avec de compétences, moins les programmeurs peuvent lire tout ce code. Si vous augmentez le nombre de techniques que vous manipulez dans les nuages sombres, la lisibilité globale diminuera. Même si vous réécrivez partiellement l'implémentation dans un autre langage ou une autre technologie, car elle peut être écrite de manière plus concise, si moins de programmeurs peuvent la gérer, la lisibilité diminuera et le temps d'analyse augmentera.
Commentaires de menteur, Javadoc, journaux
Je pense que beaucoup de gens ne pensent pas autant aux commentaires et à Javadoc qu'au code source (comme moi ...).
Malgré la description suivante, le fait qu'il existe une classe introduite à partir de la version 3.0.0 casse les prérequis pour l'investigation et crée de la confusion.
/**
* ...
* @since 2.0.1
*/
Il vaut mieux ne rien écrire que d'écrire des commentaires incorrects, Javadoc. Puisque vous pouvez le voir en regardant l'historique dans le système de gestion des versions, il peut être plus sûr de ne pas utiliser quelque chose qui a la possibilité d'une double gestion incorrecte comme «@ depuis».
Il y a d'autres choses qui risquent fort de créer des mensonges. En copiant et collant la variable de champ Logger, il est facile d'implémenter le code suivant dont le nom de classe et la classe réelle sont différents.
public class DeleteController {
private static final Logger log = LoggerFactory.getLogger(ImportController.class);
Les journaux produits par cet enregistreur peuvent prêter à confusion. Vous voudrez peut-être grep et vérifier l'intégralité du code source avant de le publier en production.
Fractionnement des valeurs clés
Le problème lors de l'enquête est l'implémentation qui divise une partie de la clé de propriété définie dans le fichier de propriétés en constantes. Par exemple, supposons que les propriétés suivantes soient définies.
account.lockout.count=10
account.lockout.interval=60000
Si vous écrivez le code suivant pour l'obtenir,
private static final String ACCOUNT_LOCK_PREFIX = "account.lockout.";
...
private void doSomething() {
ResourceBundle rb = ResourceBundle.getBundle("application");
String count = rb.getString(ACCOUNT_LOCK_PREFIX + "count");
String interval = rb.getString(ACCOUNT_LOCK_PREFIX + "interval");
Même si je grep tout le code source avec la clé de propriété "ʻaccount.lockout.count", il ne sera pas touché. En fonction du résultat, si vous décidez que cette propriété n'est pas utilisée et supprimez cette clé du fichier de propriétés, vous obtiendrez une exception MissingResourceException` au moment de l'exécution. Nous vous recommandons de ne pas fractionner les chaînes de clés.
Journal inutile
Il est nécessaire de prendre en compte les messages du journal des erreurs ainsi que les clés de propriété. Le message doit être tel que vous pouvez grep le code source pour identifier où il est utilisé. S'il existe plusieurs messages de journal identiques, l'emplacement où ils ont été émis ne peut pas être identifié. Ce serait bien si le paramètre de format de sortie de la bibliothèque de journaux devait afficher le nom du fichier et le nombre de lignes du code source dans le journal, mais en tenant compte des performances (ou parce que la valeur par défaut n'a pas été revue), ce n'est pas le cas. Il y en a aussi beaucoup.
Par exemple, le traitement de sortie de journal suivant
log.warn("{} not found", data.getId());
Si possible, il est préférable de le diviser en deux afin que l'emplacement de sortie puisse être facilement identifié.
log.warn("User does not exist in user table: {}", user.getId());
Quand
log.warn("Group does not exist in group table: {}", group.getId());
Il y a beaucoup d'autres choses à considérer concernant la sortie du journal. Une implémentation qui intercepte une exception et ne profite pas de cette exception masquera le problème.
} catch (Exception e) {
}
Il sera plus facile d'analyser le code source si les journaux utiles pour l'investigation sont générés au niveau de journal approprié et au moment approprié.
De plus, pour les applications Web, il serait très utile d'avoir la possibilité de modifier le niveau de journalisation sans redémarrer. Le logiciel avec lequel je travaille, OpenAM, possède cette fonctionnalité qui vous permet de modifier le niveau de journalisation dans une application Web pour les administrateurs. Même si un problème se produit dans l'environnement de production, vous pouvez temporairement augmenter le niveau du journal, puis reproduire l'événement pour acquérir le journal. Une fois que vous l'avez obtenu, vous pouvez restaurer le niveau de journalisation.
OpenAM dispose également d'une API REST pour le dépannage. Lorsque vous envoyez une demande à une URL spécifique, le fichier de configuration du système, le journal de débogage pour une certaine période de temps, le vidage de thread, etc. sont collectivement compressés dans un fichier zip et en sortie. Créer une fonction d'analyse de cette manière sera d'une grande aide pendant le fonctionnement.
Comment les paramètres déterminent le comportement
Lors du développement d'un framework, il est souvent difficile de suivre le comportement si un mécanisme est créé dans lequel des paramètres tels que les fichiers XML et Java Config déterminent le comportement.
Récemment (dans un mauvais sens) j'ai été accro à la configuration des contrôles d'accès Spring Security (authentification, autorisation, gestion de session, mesures CSRF, etc.). Si vous écrivez le code suivant, il contrôlera l'accès en fonction du contenu, mais si vous essayez de réaliser une chose un peu compliquée, cela ne se passera pas comme prévu.
@Override
protected void configure(HttpSecurity http) throws Exception {
http.antMatcher("/admins/**").authorizeRequests().antMatchers("/admins/login").permitAll()
.antMatchers("/admins/**").authenticated().and().formLogin().loginProcessingUrl("/admins/login")
.loginPage("/admins/login").failureUrl("/admins/login?error").defaultSuccessUrl("/admins/main")
.usernameParameter("username").passwordParameter("password").and().logout().logoutUrl("/logout")
.logoutSuccessUrl("/").deleteCookies("JSESSIONID").and().sessionManagement().sessionFixation()
.none().and().csrf();
}
Même si c'était "un peu compliqué", c'était un niveau qui pouvait être facilement implémenté en ajoutant une logique au filtre de servlet, mais en essayant d'incorporer cette logique dans les règles de Spring Security, quel type de paramètres serait fait? Je ne peux pas décider quel type de classe ou de méthode doit être implémenté.
Vous pouvez également déboguer votre propre filtre de servlet pour identifier rapidement où se situe le problème, mais il n'est pas facile de déboguer la logique générique de Spring Security. Si vous demandez une implémentation ou un paramètre qui ne peut pas être débogué lors de l'exécution comme la méthode configure () ci-dessus, il sera difficile à analyser.
Si vous créez un nouveau mécanisme qui ne peut réaliser des choses compliquées qu'en définissant, vous devez assumer divers modèles et faire comprendre au développeur pourquoi cela ne fonctionne pas. Il faut également tenir compte du fait que le coût de l'apprentissage pour les développeurs sur la façon de l'utiliser augmentera.
Poursuite d'un essoufflement excessif
Bien qu'il ait été écrit dans le code lisible, le code source n'est pas facile à lire s'il est raccourci. Ce n'est pas surprenant étant donné que le code source de la compétition de golf suivant n'est en aucun cas facile à lire.
class G{static public void main(String[]b){for(int i=0;i<100;System.out.println((++i%3<1?"Fizz":"")+(i%5<1?"Buzz":i%3<1?"":i)));}}
Vous ne pouvez pas non plus définir de points d'arrêt avec cela. Je pense qu'il vaut mieux écrire du code redondant que d'utiliser des techniques pour le raccourcir. J'ai même le sentiment que le stéréotype «code court = code facile à lire» est un facteur de création de code difficile à analyser.
Nouvelle grammaire
Des expressions Lambda ont été ajoutées dans Java 8, mais il existe de nombreux cas où cela est également difficile à déboguer. Par exemple, l'instruction suivante pour
for (String n : notifications) {
System.out.println(n);
}
En Java8, vous pouvez également écrire:
descriptions.forEach(n -> System.out.println(n));
Dans cette instruction for, si vous souhaitez arrêter la boucle uniquement lorsque la longueur de la chaîne «n» dépasse 100, définissez les points d'arrêt conditionnels suivants.
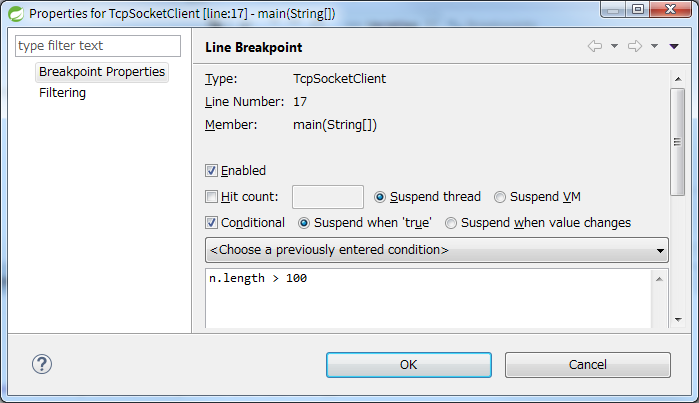
Si vous définissez un point d'arrêt conditionnel sur la première ligne System.out.println (n);, le programme se mettra en pause dans cette condition, mais si vous définissez un point d'arrêt sur cette dernière, alors J'obtiens une erreur comme (* J'utilise STS 3.8.4).
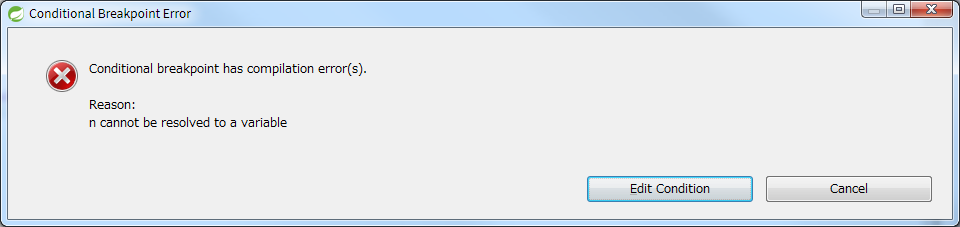
Ce serait bien si l'EDI supportait toutes les dernières grammaires, mais ce n'est pas toujours le cas. Parfois, vous ne pouvez pas déboguer sauf si vous écrivez une expression lambda d'une ligne sur trois lignes. Si vous l'implémentez avec une nouvelle syntaxe, vous devrez peut-être définir un point d'arrêt une fois et vérifier le mouvement.
Chaîne de méthodes
Le chaînage de méthodes, tel que person.setName (" Peter "). SetAge (21) ..., qui est souvent vu dans le code source récent, est également difficile à dire en analyse.
class Person {
private String name;
private int age;
// In addition to having the side-effect of setting the attributes in question,
// the setters return "this" (the current Person object) to allow for further chained method calls.
public Person setName(String name) {
this.name = name;
return this;
}
public Person setAge(int age) {
this.age = age;
return this;
}
public void introduce() {
System.out.println("Hello, my name is " + name + " and I am " + age + " years old.");
}
// Usage:
public static void main(String[] args) {
Person person = new Person();
// Output: Hello, my name is Peter and I am 21 years old.
person.setName("Peter").setAge(21).introduce();
}
}
Il semble peu intuitif d'un point de vue orienté objet que le setter renvoie sa propre instance. La lisibilité des chaînes de méthodes peut varier d'une personne à l'autre, mais étant donné la facilité de débogage, c'est difficile à dire. Dans cette ligne
person.setName("Peter").setAge(21).introduce();
Vous ne pouvez pas suspendre le programme là où vous en avez besoin car vous ne pouvez pas définir le point d'arrêt au bon point. De plus, si l'une de ces méthodes lève une exception, les numéros de ligne seront tous les mêmes, vous ne savez donc pas quelle méthode a causé le problème.
Exception in thread "main" java.lang.NullPointerException
at tdd.Person.main(Person.java:27)
Si cela est divisé comme suit,
person.setName("Peter"); //27e ligne
person.setAge(21); //Ligne 28
person.introduce(); //Ligne 29
Vous pouvez dire quelle méthode est le problème simplement en regardant la trace de la pile.
Exception in thread "main" java.lang.NullPointerException
at tdd.Person.main(Person.java:29)
Mécanisme difficile à déboguer et difficile à refléter les corrections
Dans l'application Web qui a été développée il y a quelques années, le framework a analysé la sortie du fichier XML par l'outil en utilisant les spécifications de l'écran Excel comme entrée, et l'écran a été généré.

Bien qu'il soit possible d'unifier et d'homogénéiser la conception de l'écran de cette manière, il était très difficile d'analyser lorsque la disposition et le fonctionnement n'étaient pas comme prévu.
Bien entendu, ni les spécifications d'écran Excel ni les fichiers XML ne peuvent être débogués. Les points d'arrêt peuvent être définis dans le code source du framework qui analyse le XML. Il faut du temps pour déboguer le code source du framework et pour répéter les essais et erreurs de modification des spécifications. Non seulement cela, mais il faut également du temps pour modifier, générer, déployer et vérifier le XML. Même avec le chargement automatique de Tomcat activé, cela a pris un certain temps ...
Le développement avec Spring Boot et Thymeleaf, qui est populaire ces jours-ci, ne nécessite pas (mais pas du tout) le redémarrage du conteneur après avoir modifié l'écran ou la logique. Thymeleaf ne met pas en cache le fichier HTML du modèle afin que les modifications puissent être reflétées immédiatement. Si vous utilisez JRebel, Spring Loaded, etc., vous pouvez immédiatement réfléchir et vérifier la modification du code source Java.
Si vous créez un mécanisme difficile à déboguer et difficile à refléter des corrections, cela entraînera une perte de temps importante dans le travail ultérieur.
Processus de démarrage chronophage
Je pense que le processus d'initialisation d'une application Web qui s'exécute dans un conteneur tel que Tomcat est souvent effectué au démarrage. Par exemple, le pool de connexions de base de données est créé à ce moment, mais il ne doit pas nécessairement être effectué au démarrage. Ce n'est pas toujours lent, même si vous le faites en arrière-plan lors du premier accès à la base de données ou après le démarrage. Non seulement dans le processus de développement, mais aussi dans le fonctionnement et le dépannage, le conteneur sera redémarré plusieurs fois. Même si un temps de démarrage augmente de quelques secondes, le temps de (nombre accru de secondes) x (nombre de développeurs) x (nombre d'exécutions de redémarrage) est perdu.
Sur un site, il y avait une application Web qui prenait 5 minutes pour lancer Tomcat, et personne n'en doutait et la développait. J'ai pensé que c'était étrange, et lorsque j'ai enquêté sur la cause du retard, un processus représentait environ 90% du temps de traitement d'initialisation, et en améliorant cela, le temps de démarrage a été amélioré à environ 20 secondes. Si l'heure de démarrage du conteneur varie considérablement selon que vous déployez ou non l'application Web, vous souhaiterez peut-être examiner le contenu du processus d'initialisation de l'application Web une fois.
Résumé
J'ai beaucoup écrit en y pensant, donc ce n'est pas très organisé, mais il y a beaucoup d'autres codes qui sont difficiles à analyser et à déboguer. Pour éviter que cela ne se produise, je pense que vous devez être conscient des points suivants.
- En plus d'écrire du code facile à lire, code en considérant s'il est facile à déboguer ou à analyser.
- Essayez d'exécuter l'EDI pour voir s'il peut être débogué et s'il est facile à déboguer.
- Gardez toujours à l'esprit que les messages de journal et de commentaire sont utiles pour l'analyse
- Prise en compte approfondie lors de l'introduction de technologies délicates et de nouvelles règles
- Ne vous heurtez pas à la technique
―― Je me fiche d'écrire court
- Ne créez pas de mécanisme difficile ou long à déboguer et à analyser
Au final, j'ai dit quelque chose de bien, mais je n'écris pas un tel code ...: bow: