Traitement asynchrone en Python: référence inverse asyncio
Il n'y avait pas beaucoup d'exemples pratiques d'asyncio et async / await de Python, j'ai donc créé une référence inverse basée sur des exemples basée sur les informations que j'ai recueillies. Cependant, il y a un mystère sur ce qui est vrai car il n'y a vraiment aucune information dans ce domaine, donc si vous avez des informations, n'hésitez pas à nous contacter.
Les exemples présentés cette fois sont résumés dans l'essentiel suivant. J'espère que vous pourrez vous y référer lors de sa mise en œuvre.
icoxfog417/asyncio_examples.py
introduction
Python a trois packages qui peuvent être utilisés pour le traitement parallèle: threading, multiprocessing et ʻasyncio`. Tout d'abord, examinons ces différences.
La différence entre ces packages est directement équivalente à la différence entre "multi-thread", "multi-process" et "non-bloquant". Tout d'abord, à propos de la différence entre le multi-thread et le multi-processus.
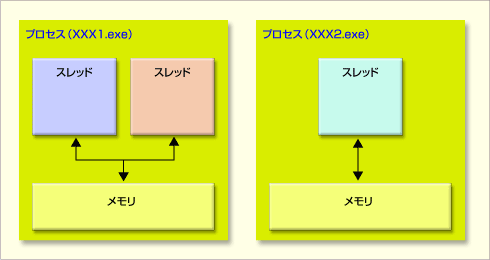 Le premier multi-thread est utilisé dans de tels cas (1/2)
Le premier multi-thread est utilisé dans de tels cas (1/2)
Un processus est une unité de traitement avec sa propre mémoire, et dans le cas d'un processeur dit multicœur, ce processus peut être affecté à chaque cœur et peut être traité efficacement (bien qu'il ne soit pas impossible de créer plus de processus que le nombre de cœurs). Cela devient inefficace). Un thread est une unité de traitement dans un processus et les threads entre les mêmes processus partagent la mémoire.
Le non-blocage est né comme moyen de surmonter les faiblesses du multithreading. Il existe une différence dans la méthode de traitement d'un grand nombre de requêtes (Référence: Introduction to Node.js).
- Multi-thread: Créez des threads pour chaque requête-> S'il y a beaucoup de requêtes, ce sera difficile (problème C10K)
- Non bloquant: gérer plusieurs demandes dans un seul thread
- Si vous gérez une certaine demande jusqu'à présent, passez au traitement d'autres demandes, et lorsque cela est terminé, traitez-la comme s'il s'agissait de l'original ...
Par conséquent, le multi-thread et le non-bloquant ne peuvent pas cohabiter car ils gèrent les threads différemment, mais les deux peuvent être combinés avec le multi-processus (en théorie).
Asyncio et async / await gérés cette fois sont des fonctions pour implémenter un traitement non bloquant. Veuillez d'abord garder ce point à l'esprit.
Basique: Comment écrire un processus non bloquant
Tout d'abord, je vais vous présenter comment écrire un traitement non bloquant en utilisant asyncio comme base. De plus, ce traitement non bloquant est efficace et applicable dans les cas suivants.
- Il y a un traitement lourd qui peut être un goulot d'étranglement
- Le processus se produit en grand nombre
- L'ordre dans lequel les processus sont terminés n'a pas d'importance
Plus précisément, je pense que l'acquisition de pages à partir d'url et l'acquisition de données à partir de DB sont applicables, mais veuillez noter que "l'ordre d'achèvement du traitement n'a pas d'importance".
Voici un exemple simple (extrait du premier exemple).
import asyncio
Seconds = [
("first", 5),
("second", 0),
("third", 3)
]
async def sleeping(order, seconds, hook=None):
await asyncio.sleep(seconds)
if hook:
hook(order)
return order
async def basic_async():
# the order of result is nonsequential (not depends on order, even sleeping time)
for s in Seconds:
r = await sleeping(*s)
print("{0} is finished.".format(r))
return True
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(basic_async())
Le cœur du processus est basic_async. Ici, le processus appelé "endormi" (dans l'image, cela correspond au processus "lourd mais l'ordre de traitement n'a pas d'importance") est répété.
La boucle d'événements générée par loop = asyncio.get_event_loop () est responsable de l'exécution du processus, et c'est le "thread non bloquant". En gros, passez une fonction (asyncio.coroutine) qui est ʻasync ici et traitez-la (loop.run_until_complete (basic_async ())`).
En regardant r = await sleeping (* s), il attend que le processus se termine par ʻawait`. En regardant cela seul, je pense que c'est la même chose qu'une instruction for normale car elle attend que le traitement se termine à chaque fois, et en fait c'est le cas dans cet exemple. Comme vous pouvez le voir en l'exécutant, les résultats sont toujours dans l'ordre suivant:
first is finished.
second is finished.
third is finished.
N'est-ce pas asynchrone! Cependant, cette «attente» fonctionne réellement lors du traitement en parallèle comme présenté ci-dessous. Quand ʻawait` est fait, quelque chose de lourd commence, donc quand vous atteignez ce point, le thread démarre "d'autres choses dans la boucle d'événements". Ensuite, lorsque le traitement effectué par «attend» est terminé, il retourne à la tâche et continue le traitement.
Par conséquent, si vous les traitez en parallèle comme indiqué ci-dessous, vous pouvez voir que chaque tâche est en cours d'exécution (soyez prudent lors de l'exécution du script suivant car il ne se termine pas comme indiqué par run_forever).
async def basic_async(num):
# the order of result is nonsequential (not depends on order, even sleeping time)
for s in Seconds:
r = await sleeping(*s)
print("{0}'s {1} is finished.".format(num, r))
return True
if __name__ == "__main__":
loop = asyncio.get_event_loop()
# make two tasks in event loop
asyncio.ensure_future(basic_async(1))
asyncio.ensure_future(basic_async(2))
loop.run_forever()
Si vous regardez le résultat de l'exécution, vous pouvez voir que lorsque 1 est exécuté et que ʻawait est atteint, 2 est démarré, quand 1 revient de ʻawait, il revient à 1 et continue, et ainsi de suite. ..
1's first is finished.
2's first is finished.
1's second is finished.
2's second is finished.
1's third is finished.
2's third is finished.
Donc, s'il n'y a qu'une seule coroutine dans la boucle d'événements, async / await n'aura aucun effet. Ceci est important et doit être rappelé.
À la fin des bases, nettoyons les objets confus liés à l'asyncio.
coroutine: La valeur de retour de la fonction async seracoroutine.- ʻAsync def hoge (): S'il y a une fonction appelée xxx
,hoge ()sera un objetcoroutine` au lieu de renvoyer un retour immédiatement. Future: objet de type différé dans jQuery- Les résultats de l'exécution peuvent être propagés en utilisant
set_resultetset_exception Task- Une sous-classe de «Future» qui gère l'exécution. Je ne le fais pas directement (ou plutôt, je ne devrais pas le faire), donc je m'en fiche.
Il traite en fait de coroutine ou Future, et la plupart des fonctions prennent en charge les deux. coroutine peut être converti en Task avec ʻasyncio.ensure_future ([ create_task`](http://docs.python.jp/3/library/asyncio-eventloop.html#asyncio.BaseEventLoop. Il existe également une méthode appelée create_task) qui peut être une tâche, mais il n'y a fondamentalement aucune différence entre ces deux méthodes (http://stackoverflow.com/questions/33980086/whats-the-difference-between-loop) -create-task-asyncio-async-ensure-future-et)).
Voyons maintenant comment gérer réellement plusieurs tâches dans la boucle d'événements.
Je souhaite traiter en parallèle (longueur fixe)
Si le nombre de processus que vous souhaitez exécuter en parallèle est décidé à l'avance, vous pouvez tous les traiter simultanément en parallèle. Les fonctionnalités fournies pour cela sont ʻasyncio.gather et ʻasyncio.wait.
Premièrement, le modèle de ʻasyncio.gather`
async def parallel_by_gather():
# execute by parallel
def notify(order):
print(order + " has just finished.")
cors = [sleeping(s[0], s[1], hook=notify) for s in Seconds]
results = await asyncio.gather(*cors)
return results
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = loop.run_until_complete(parallel_by_gather())
for r in results:
print("asyncio.gather result: {0}".format(r))
Ce ʻasyncio.gather` a un ordre d'exécution indéfini comme d'habitude, mais il a la belle propriété de renvoyer les résultats traités dans l'ordre dans lequel ils ont été passés ([here](http: //docs.python.). jp / 3 / library / asyncio-task.html # asyncio.gather) Voir). Ceci est utile lorsque vous souhaitez conserver l'ordre du tableau d'origine dans le résultat de l'exécution tout en effectuant un traitement asynchrone.
- Lorsque vous utilisez le système de dictionnaire, veuillez noter que l'ordre du dictionnaire lui-même est indéfini (je suis resté bloqué). Dans le cas de Dictionary, il n'est pas garanti que les clés apparaîtront dans l'ordre de définition.
L'autre consiste à utiliser ʻasyncio.wait`.
async def parallel_by_wait():
# execute by parallel
def notify(order):
print(order + " has just finished.")
cors = [sleeping(s[0], s[1], hook=notify) for s in Seconds]
done, pending = await asyncio.wait(cors)
return done, pending
if __name__ == "__main__":
loop = asyncio.get_event_loop()
done, pending = loop.run_until_complete(parallel_by_wait())
for d in done:
dr = d.result()
print("asyncio.wait result: {0}".format(dr))
Le résultat de «wait» est renvoyé avec «done» et «pending». Notez que lors de la récupération du résultat, vous devez le récupérer avec result () (si une exception se produit pendant le traitement, l'exception sera ignorée lorsque result () est exécuté).
Je souhaite traiter en parallèle (durée indéfinie)
Je connaissais le nombre de processus parallèles à effectuer plus tôt, mais la longueur peut ne pas être fixée (flux, etc.) lorsque les demandes se succèdent.
Dans un tel cas, le traitement à l'aide de Queue est possible.
async def queue_execution(arg_urls, callback, parallel=2):
loop = asyncio.get_event_loop()
queue = asyncio.Queue()
for u in arg_urls:
queue.put_nowait(u)
async def fetch(q):
while not q.empty():
u = await q.get()
future = loop.run_in_executor(None, requests.get, u)
future.add_done_callback(callback)
await future
tasks = [fetch(queue) for i in range(parallel)]
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = []
def store_result(f):
results.append(f.result())
loop.run_until_complete(queue_execution([
"http://www.google.com",
"http://www.yahoo.com",
"https://github.com/"
], store_result))
for r in results:
print("queue execution: {0}".format(r.url))
C'est une longueur fixe et passe un tableau d'urls, donc je n'utilise pas beaucoup Queue ... Le but est de créer une file avec ʻasyncio.Queue et d'y placer la cible de traitement avec put_nowait (lors de la fixation de la taille de la file d'attente, utilisez put` pour créer une file d'attente. Vous pouvez bloquer jusqu'à ce que ce soit gratuit).
ʻAsync def fetch continuera à être traité à moins que la file d'attentene soit vide. Cette fois, nous exécutonsfetch en parallèle autant que parallel, donc il semble qu'une file est partagée par deux coroutines`.
Notez que l'obtention de l'url Python (ʻurllib.request.urlopen) bloque le processus, donc [ici](http://stackoverflow.com/questions/22190403/how-could-i-use-requests- J'ai essayé de l'implémenter en référence à in-asyncio), mais il ne fonctionnait pas en parallèle (je dois probablement faire ʻawait après avoir terminé tous les run_in_executors?). Si vous voulez obtenir en parallèle, il est plus sûr d'utiliser ʻaiohttp`.
Cependant, comme indiqué dans loop.run_in_executor (None, requests.get, u), vous pouvez [Future] fonctions ordinaires en utilisant run_in_executor [http://docs.python.jp/3/". library / asyncio-eventloop.html # asyncio.BaseEventLoop.run_in_executor) peut également être utilisé comme technique dans d'autres cas.
Je veux contrôler le nombre d'exécutions en parallèle
Surtout lors du scraping, etc., le traitement simultané des urls de 1000 contenus dans un certain site pose beaucoup de problèmes, vous pouvez donc contrôler le nombre de processus exécutés en parallèle. Celui utilisé à ce moment est «Sémaphore».
async def limited_parallel(limit=3):
sem = asyncio.Semaphore(limit)
# function want to limit the number of parallel
async def limited_sleep(num):
with await sem:
return await sleeping(str(num), num)
import random
tasks = [limited_sleep(random.randint(0, 3)) for i in range(9)]
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
done, pending = loop.run_until_complete(limited_parallel())
for d in done:
print("limited parallel: {0}".format(d.result()))
C'est facile à utiliser, attendez simplement que Semaphore soit disponible par avec await sem dans la fonction asynchrone que vous voulez contrôler le nombre d'exécutions simultanées.
Je souhaite effectuer un traitement de rappel une fois le traitement asynchrone terminé
Si vous souhaitez effectuer un processus spécifique une fois le processus terminé, vous pouvez utiliser ʻadd_done_callback dans ʻasyncio.Future. Dans ce qui suit, coroutine est converti en Task par ʻasyncio.ensure_future` et le rappel reçu est ajouté.
async def future_callback(callback):
futures = []
for s in Seconds:
cor = sleeping(*s)
f = asyncio.ensure_future(cor)
f.add_done_callback(callback)
futures.append(f)
await asyncio.wait(futures)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
results = []
def store_result(f):
results.append(f.result())
loop.run_until_complete(future_callback(store_result))
for r in results:
print("future callback: {0}".format(r))
Si je veux le faire, je pense que je peux ajouter plus de Futures que j'ai reçus dans le rappel, mais je pense que c'est un mystère compliqué et je pense qu'il vaut mieux s'arrêter (j'ai perdu quelques heures de précieuses vacances).
Je souhaite créer un itérateur qui traite de manière asynchrone
Si vous souhaitez diffuser le traitement non bloquant tout en étant un itérateur, comme une lecture séquentielle à partir de la base de données, vous pouvez créer votre propre itérateur.
def get_async_iterator(arg_urls):
class AsyncIterator():
def __init__(self, urls):
self.urls = iter(urls)
self.__loop = None
def __aiter__(self):
self.__loop = asyncio.get_event_loop()
return self
async def __anext__(self):
try:
u = next(self.urls)
future = self.__loop.run_in_executor(None, requests.get, u)
resp = await future
except StopIteration:
raise StopAsyncIteration
return resp
return AsyncIterator(arg_urls)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
async def async_fetch(urls):
ai = get_async_iterator(urls)
async for resp in ai:
print(resp.url)
loop.run_until_complete(async_fetch([
"http://www.google.com",
"http://www.yahoo.com",
"https://github.com/"
]))
Les points sont «aiter» et «anext», qui est la version asynchrone de l'itérateur standard. Vous pouvez utiliser ʻawait dans ʻanext. Lorsque vous l'utilisez, veuillez noter qu'il est itéré avec ʻasync for resp in ai et ʻasync for.
Je souhaite effectuer un traitement non bloquant dans plusieurs processus (non confirmé)
Au tout début, j'ai dit que le multi-processus et le non-blocage peuvent cohabiter (en théorie), mais voici comment faire cela? Je ne connais pas le point exact car c'est un mystère comment vérifier si c'est multi-processus + non bloquant, mais je le posterai pour le moment.
import asyncio
import concurrent.futures
loop = asyncio.get_event_loop()
executor = concurrent.futures.ProcessPoolExecutor()
loop.set_default_executor(executor)
La source
- Cleanly shutdown the IO loop when using an executor
- How to properly create and run concurrent tasks using python's asyncio module?
L'exécuteur par défaut utilise ThreadPoolExecutor, donc je vais changer cela en ProcessPoolExecutor. Cela entraînera probablement un traitement non bloquant processus par processus et, comme pour le multitraitement, vous pouvez bénéficier du traitement parallèle en ne distribuant que les cœurs du processeur.
Cependant, à l'inverse, il n'est pas efficace pour un processus de dupliquer plus que le nombre de cœurs de processeur, et cela ne convient pas lorsque vous souhaitez acquérir de nombreuses URL en parallèle (cela convient mieux aux threads). Je pense que vous devriez l'utiliser correctement selon la situation. Si vous avez peur de le définir par défaut, vous ne pouvez l'utiliser que lors de l'exécution d'une fonction spécifique avec run_in_executor. Je pense.
Vous trouverez ci-dessous une version Process de l'exemple de file d'attente (je pense que cela fonctionne le mieux). Le print_num est sorti car une erreur s'est produite s'il ne s'agissait pas d'une fonction globale (utilisez-vous pickle pour dupliquer le processus?).
def print_num(num):
print(num)
async def async_by_process():
executor = concurrent.futures.ProcessPoolExecutor()
queue = asyncio.Queue()
for i in range(10):
queue.put_nowait(i)
async def proc(q):
while not q.empty():
i = await q.get()
future = loop.run_in_executor(executor, print_num, i)
await future
tasks = [proc(queue) for i in range(4)] # 4 = number of cpu core
return await asyncio.wait(tasks)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
loop.run_until_complete(async_by_process())
Ce qui précède est un résumé de l'asyncio de Python.
Recommended Posts