Comprendre la méthode k-means
introduction
J'ai résumé ce que j'ai appris sur la méthode des k-means. Il s'agit de l'algorithme de clustering le plus basique.
référence
Pour comprendre la méthode des k-moyennes, je me suis référé à ce qui suit.
- Introduction à l'apprentissage automatique pour le traitement du langage (série Traitement du langage naturel) Daiya Takamura (Auteur), Manabu Okumura (supervisé) Éditeur; Corona
- Essence of Machine Learning Koichi Kato (Auteur) Editeur; SB Creative Co., Ltd.
Présentation de la méthode k-means
Quelle est la méthode k-means
La méthode k-means est un algorithme qui divise d'abord les données en grappes appropriées, puis ajuste les données pour qu'elles soient bien divisées en utilisant la moyenne des grappes. La méthode k-means (appelée méthode de calcul de la moyenne des k points) car c'est un algorithme qui crée k clusters de n'importe quelle désignation.
algorithme de méthode k-means
Plus précisément, la méthode k-moyenne suit les étapes suivantes.
- Allouez au hasard des clusters pour chaque point $ x_ {i} $
- Calculez le centre de gravité des points attribués à chaque cluster
- Pour chaque point, calculez la distance par rapport au centre de gravité calculée ci-dessus et réaffectez-la au cluster avec la distance la plus proche.
- Répétez les étapes 2 et 3 jusqu'à ce que le cluster attribué ne change pas.
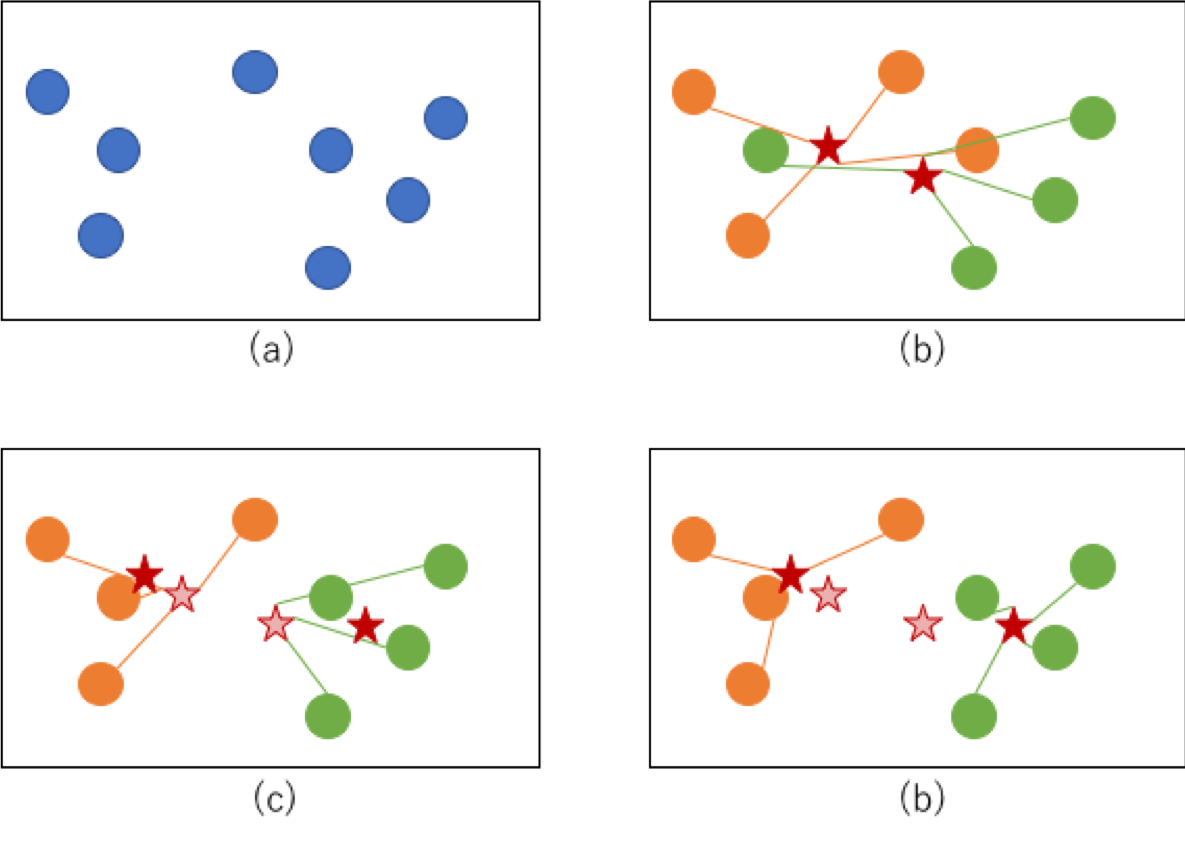
Exprimé sur la figure, c'est une image que le cluster converge dans l'ordre de (a) → (b) → (c) → (d) comme indiqué ci-dessous. À l'étape (b), les groupes sont d'abord affectés à chaque point et le centre de gravité est calculé (le centre de gravité est indiqué par l'étoile rouge). En (c), le cluster est réaffecté en fonction de la distance de son centre de gravité. (Le nouveau centre de gravité est indiqué par l'étoile rouge et l'ancien centre de gravité est représenté par l'étoile rouge fine). Si ce processus est répété et que le cluster converge d'une manière qui ne change pas comme en (d), le processus est terminé.
Implémenter la méthode k-means
Implémentation de la méthode k-means sans utiliser la bibliothèque
Ce qui suit est une implémentation de la méthode k-means sans utiliser de bibliothèque. Essence de l'apprentissage automatique Un mémo est écrit dans le code.
import numpy as np
import itertools
class KMeans:
def __init__(self, n_clusters, max_iter = 1000, random_seed = 0):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.random_state = np.random.RandomState(random_seed)
def fit(self, X):
#Générer un générateur qui crée à plusieurs reprises des étiquettes pour le nombre spécifié de clusters (0),1,2,0,1,2,0,1,2...(Comme)
cycle = itertools.cycle(range(self.n_clusters))
#Attribuer au hasard des étiquettes de cluster à chaque point de données
self.labels_ = np.fromiter(itertools.islice(cycle, X.shape[0]), dtype = np.int)
self.random_state.shuffle(self.labels_)
labels_prev = np.zeros(X.shape[0])
count = 0
self.cluster_centers_ = np.zeros((self.n_clusters, X.shape[1]))
#Se termine lorsque le cluster auquel appartient chaque point de données ne change pas ou dépasse un certain nombre de répétitions
while (not (self.labels_ == labels_prev).all() and count < self.max_iter):
#Calculez le centre de gravité de chaque cluster à ce moment
for i in range(self.n_clusters):
XX = X[self.labels_ == i, :]
self.cluster_centers_[i, :] = XX.mean(axis = 0)
#Arrondissez la distance entre chaque point de données et le centre de gravité de chaque cluster
dist = ((X[:, :, np.newaxis] - self.cluster_centers_.T[np.newaxis, :, :]) ** 2).sum(axis = 1)
#Souvenez-vous de l'étiquette de cluster précédente. Si l'étiquette précédente et l'étiquette ne changent pas, le programme se termine.
labels_prev = self.labels_
#À la suite du recalcul, attribuez le libellé du cluster le plus proche de la distance
self.labels_ = dist.argmin(axis = 1)
count += 1
def predict(self, X):
dist = ((X[:, :, np.newaxis] - self.cluster_centers_.T[np.newaxis, :, :]) ** 2).sum(axis = 1)
labels = dist.argmin(axis = 1)
return labels
Vérification
Vous trouverez ci-dessous une vérification de la possibilité de clustering avec cet algorithme.
import matplotlib.pyplot as plt
#Créez un jeu de données adapté
np.random.seed(0)
points1 = np.random.randn(80, 2)
points2 = np.random.randn(80, 2) + np.array([4,0])
points3 = np.random.randn(80, 2) + np.array([5,8])
points = np.r_[points1, points2, points3]
np.random.shuffle(points)
#Créer un modèle à diviser en 3 clusters
model = KMeans(3)
model.fit(points)
print(model.labels_)
Ensuite, la sortie ressemblera à ceci. Vous pouvez voir que les étiquettes sont brillamment attribuées aux trois.
[1 0 2 1 0 0 2 0 1 2 0 0 2 0 2 2 0 0 2 1 2 0 1 2 0 1 2 1 0 1 0 0 0 2 0 2 0
1 1 0 0 0 0 1 2 0 0 0 2 1 0 2 1 0 2 0 2 1 1 1 1 1 0 2 0 2 2 0 0 0 0 0 2 0
2 2 2 1 0 2 1 2 0 0 2 0 1 2 1 1 1 2 2 2 1 2 2 2 1 2 1 0 0 0 0 0 2 0 1 0 1
2 0 1 1 0 1 2 1 1 1 2 2 1 2 1 0 1 1 2 0 1 0 1 1 1 0 2 1 0 0 1 2 2 2 1 0 0
0 2 2 2 0 0 1 2 0 2 2 2 1 2 2 2 2 2 1 1 0 1 2 1 1 2 0 1 1 1 1 0 2 1 0 1 1
2 1 2 2 2 1 2 0 1 2 2 2 0 0 0 0 1 1 2 1 1 1 2 2 0 0 1 1 2 0 0 1 0 1 1 2 1
0 1 2 1 0 1 2 2 1 1 2 1 2 1 0 1 1 2]
Illustrons cela avec matplotlib.
markers = ["+", "*", "o"]
color = ['r', 'b', 'g']
for i in range(3):
p = points[model.labels_ == i, :]
plt.scatter(p[:, 0], p[:, 1], marker = markers[i], color = color[i])
plt.show()
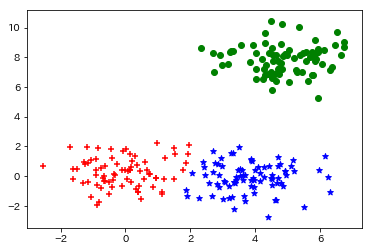
Voici la sortie. Vous pouvez voir que le clustering est terminé sans aucun problème.
 Next
Cette méthode k-means pose le problème que la précision change en fonction de l'allocation du premier cluster aléatoire. Je voudrais contester la mise en œuvre de k-means ++, qui tente de surmonter ce problème.
Next
Cette méthode k-means pose le problème que la précision change en fonction de l'allocation du premier cluster aléatoire. Je voudrais contester la mise en œuvre de k-means ++, qui tente de surmonter ce problème.