Optimisation de la Bbox pour les ensembles de données personnalisés [format COCO]
Optimisation Bbox pour les ensembles de données personnalisés
Lors de la déduction en utilisant des données personnelles dans maskrcnn etc., il peut être optimisé s'il n'y a qu'une seule catégorie.
Par exemple, si la hauteur et la largeur sont prédéterminées, ou si la taille est à peu près connue avant que la taille ne soit déduite, lors de la génération de la boîte d'ancrage Créer quelque chose de proche de cette forme améliorera le coût et la précision des calculs.
Lorsqu'une boîte d'ancrage est créée dans la couche FPN
La taille initiale est (0.5,1.0,2.0) Le rapport hauteur / largeur est (32, 64, 128, 256, 512)
est. (Pour facebook / maskrcnn-benchmark)
Afin d'estimer quelle taille est bonne, la surface et le rapport hauteur / largeur sont convertis en un histogramme en utilisant les informations du polygone du masque annoté.
import IPython
import os
import json
import random
import numpy as np
import requests
from io import BytesIO
from math import trunc
from PIL import Image as PILImage
from PIL import ImageDraw as PILImageDraw
import base64
import pandas as pd
import numpy as np
# Load the dataset json
class CocoDataset():
def __init__(self, annotation_path, image_dir):
self.annotation_path = annotation_path
self.image_dir = image_dir
self.colors = colors = ['blue', 'purple', 'red', 'green', 'orange', 'salmon', 'pink', 'gold',
'orchid', 'slateblue', 'limegreen', 'seagreen', 'darkgreen', 'olive',
'teal', 'aquamarine', 'steelblue', 'powderblue', 'dodgerblue', 'navy',
'magenta', 'sienna', 'maroon']
json_file = open(self.annotation_path)
self.coco = json.load(json_file)
json_file.close()
self.process_categories()
self.process_images()
self.process_segmentations()
def display_info(self):
print('Dataset Info:')
print('=============')
for key, item in self.info.items():
print(' {}: {}'.format(key, item))
requirements = [['description', str],
['url', str],
['version', str],
['year', int],
['contributor', str],
['date_created', str]]
for req, req_type in requirements:
if req not in self.info:
print('ERROR: {} is missing'.format(req))
elif type(self.info[req]) != req_type:
print('ERROR: {} should be type {}'.format(req, str(req_type)))
print('')
def display_licenses(self):
print('Licenses:')
print('=========')
requirements = [['id', int],
['url', str],
['name', str]]
for license in self.licenses:
for key, item in license.items():
print(' {}: {}'.format(key, item))
for req, req_type in requirements:
if req not in license:
print('ERROR: {} is missing'.format(req))
elif type(license[req]) != req_type:
print('ERROR: {} should be type {}'.format(req, str(req_type)))
print('')
print('')
def display_categories(self):
print('Categories:')
print('=========')
for sc_key, sc_val in self.super_categories.items():
print(' super_category: {}'.format(sc_key))
for cat_id in sc_val:
print(' id {}: {}'.format(cat_id, self.categories[cat_id]['name']))
print('')
def print_segmentation(self):
self.segmentations = {}
data = []
for segmentation in self.coco['annotations']:
area = segmentation['area']
print(area)
bbox = segmentation['bbox']
aspect = bbox[2]/bbox[3]
print(bbox)
print(aspect)
data.append([area,aspect])
df = pd.DataFrame(data)
df.to_csv('out.csv')
print(df)
annotation_path = "Chemin du fichier json coco annoté"
image_dir = 'Chemin vers le dossier dans lequel les images sont stockées'
coco_dataset = CocoDataset(annotation_path, image_dir)
coco_dataset.print_segmentation()
Si vous faites cela, vous obtiendrez un csv avec la zone et le rapport hauteur / largeur comme indiqué ci-dessous.

Après cela, je vais faire un graphique avec Excel.
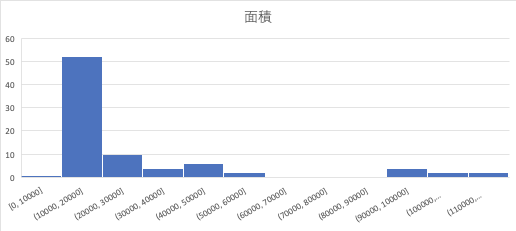
Dans ce cas, vous pouvez voir que la zone est souvent autour de 10000.
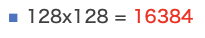 Donc cette fois, je sais que la taille de l'ancre 128 est importante.
Donc cette fois, je sais que la taille de l'ancre 128 est importante.
Vous pouvez voir que ce serait bien si nous pouvions fabriquer 256 ou 512 plus grands que cette taille. Au contraire, il s'avère que la taille de 64 est presque inexistante, donc elle peut être supprimée.
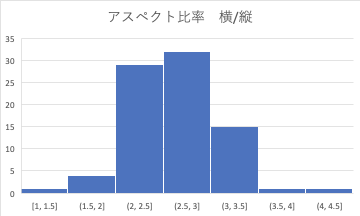
Si vous pensez au rapport hauteur / largeur de la même manière, vous pouvez voir qu'il y a très peu d'endroits où la hauteur: largeur est de 0,5 cette fois.
 Vous pouvez voir que vous devez le configurer.
Vous pouvez voir que vous devez le configurer.
Sommaire
Avec la méthode ci-dessus, vous pouvez trouver le paramètre optimal pour la boîte d'ancrage lorsqu'il y a peu de catégories. J'espère qu'il pourra être optimisé.