Codeforces Round # 594 (Div.2) Examen Bacha (10/29)
Les résultats de cette fois

Impressions de cette époque
En D **, je pleurais parce que les indices ne correspondaient pas pour toujours ... En conséquence, j'ai pu le résoudre si je le résolvais après avoir réorganisé la politique, donc je voudrais être conscient que ** je reconstruirai à partir de la politique si je reste bloqué dans la mise en œuvre **.
Problème A
Lorsque vous avez une intersection, la coordonnée $ x $ de l'intersection est $ x + p \ _i = -x + q \ _i \ leftrightarrow x = \ frac {q \ _i-p \ _i} {2} $. La condition pour que ce soit un entier est lorsque $ p \ _i, q \ _i $ est divisé par 2 et le reste est égal. Par conséquent, (nombre pair inclus dans $ p $) $ \ times $ (nombre pair contenu dans $ q $) + (nombre impair contenu dans $ p $) $ \ times $ (inclus dans $ q $) Le nombre impair) est la réponse.
A.py
for _ in range(int(input())):
n=int(input())
p=list(map(int,input().split()))
m=int(input())
q=list(map(int,input().split()))
co0=0
for i in range(n):
co0+=(p[i]%2==0)
co1=n-co0
co2=0
for i in range(m):
co2+=(q[i]%2==0)
co3=m-co2
print(co0*co2+co1*co3)
Problème B
Lorsque les coordonnées finales sont $ (x, y) $, pour maximiser $ x ^ 2 + y ^ 2 $, un seul de ** $ x, y $ doit être aussi grand que possible ** (Ici, nous supposons que $ x $ est augmenté). De plus, puisque les côtés doivent être placés perpendiculairement au côté juste avant, ** jusqu'à $ n- [\ frac {n} {2}] $ colle pour augmenter les coordonnées $ x $. Vous pouvez choisir comme **. Par conséquent, lors du tri d'un bâton donné, sélectionnez le bâton du plus petit au $ [\ frac {n} {2}] $ ème plus petit bâton comme celui pour augmenter la coordonnée $ y $, et $ [\ frac {n } {2}] + 1 Il est préférable de choisir le bâton après le troisième plus petit bâton comme celui qui augmente les coordonnées $ x $.
B.py
n=int(input())
a=list(map(int,input().split()))
a.sort()
c,d=0,0
for i in range(n//2):
c+=a[i]
for i in range(n//2,n):
d+=a[i]
print(c**2+d**2)
Problème C
C'est un problème difficile, mais vous pouvez le voir en expérimentant.
Je voudrais utiliser DP pour gérer la condition de 2 carrés consécutifs, mais ** le DP 2D normal semble être difficile ** car $ n et m $ sont grands. Par conséquent, j'ai mené une expérience dans l'espoir qu'elle serait décidée ** dans une certaine mesure régulièrement **.
À ce moment-là, lorsque j'ai mené une expérience en utilisant des échantillons, j'ai trouvé que ** si la première ligne était décidée, les lignes suivantes seraient décidées dans l'ordre **. Par exemple, s'il s'agit de 5 lignes et 3 colonnes, ce sera comme suit.
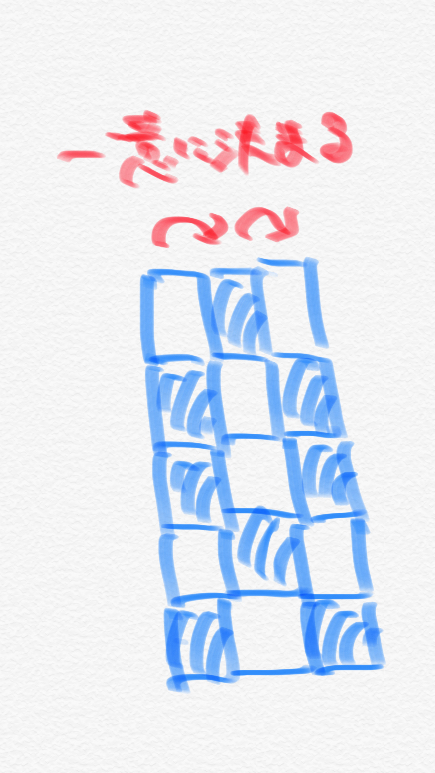
À partir de la figure ci-dessus, vous pouvez voir qu'en choisissant la première colonne, les colonnes suivantes sont ** déterminées de manière unique **. Vous pouvez également voir que les ** nombres pairs et impairs ont le même modèle de colonnes **.
Cependant, certains modèles ** ne peuvent pas être déterminés de manière unique. Autrement dit, il s'agit d'un modèle dans lequel les cellules noires et blanches sont décalées comme indiqué ci-dessous. Pour ce modèle, il peut y avoir plusieurs des colonnes suivantes: (Je ne prouverai pas ici qu'il n'y a pas de multiples façons dans d'autres modèles, mais cela peut être prouvé en utilisant le fait qu'il est uniquement déterminé dans le cas de cellules avec des couleurs consécutives)
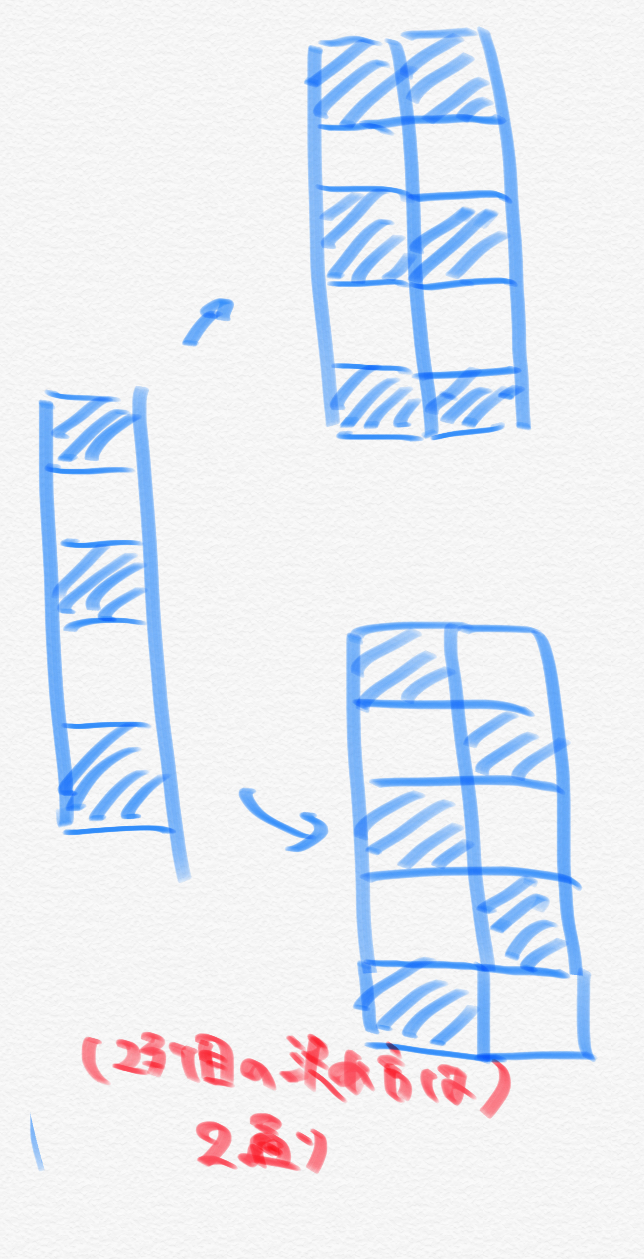
De plus, lorsque le motif dans lequel les carrés noirs sont dans la première rangée est A et le motif dans lequel les carrés blancs sont dans la première rangée est B, dans le cas de ** AA ou BB, les colonnes suivantes sont respectivement B et A. Doit être **. Sur la base de ce qui précède, après avoir trouvé le nombre de carrés noirs et blancs dans la première ligne, le nombre de lignes dans le motif d'alternance noir et blanc est calculé séparément et le total est de $. Vous pouvez voir que vous pouvez écrire un programme de O (n + m) $.
J'ai passé trop de temps car je ne pouvais pas passer à la mise en œuvre après avoir résumé les considérations jusqu'à présent. C'est une réflexion. Quoi qu'il en soit, nous examinerons la mise en œuvre ci-dessous. Vous devez également vous rappeler de diviser par 10 $ ^ 9 + 7 $.
① Comment décider de la première rangée
Lorsque le noir et le blanc alternent dans la première ligne, il y a toujours deux façons, qui sont comptées dans ② (d'où, ** exclu ici **). Pour les autres modèles, les colonnes qui suivent sont déterminées de manière unique. Par conséquent, considérez le DP suivant pour voir combien de cellules noires et blanches sont disposées dans la première ligne (blanc lorsque $ j = 0 $, noir lorsque $ j = 1 $, $ k = 0,1 $). est).
$ dp [i] [j] [k]: = $ (Nombre de cellules arrangées quand $ k + 1 $ cellules continuent quand $ i $ line est déterminé)
À ce stade, la transition est la suivante (abrégée).
(1) Quand $ k = 0 $ Vous pouvez choisir des carrés noirs ou blancs, vous pouvez donc considérer deux transitions de $ dp [i] [j] [k] $.
(2) Quand $ k = 1 $ Il ne peut y avoir qu'une seule façon de choisir une cellule de couleur différente de $ dp [i] [j] [k] $, car elle ne doit pas être plus de deux d'affilée.
Après avoir considéré la transition, (somme de $ dp [n-1] $) -2 est la réponse.
(2) Il existe plusieurs façons de décider si le motif est un motif dans lequel les cellules noires et blanches alternent dans la première rangée.
Comme précédemment, si vous considérez le modèle dans lequel les carrés noirs sont dans la rangée supérieure comme A et le modèle dans lequel les carrés blancs sont dans la rangée supérieure comme B, vous pouvez définir le DP suivant ($ j = 0). A quand $, B, $ k = 0,1 $ quand $ j = 1 $).
$ dp [i] [j] [k]: = $ (Nombre de colonnes arrangées lorsque $ k + 1 $ motifs de $ j $ continuent lorsque la colonne $ i $ est déterminée)
A ce moment, la transition est la suivante (elle est un peu abrégée).
(1) Quand $ k = 0 $ Vous pouvez choisir le modèle A ou B, ainsi vous pouvez penser à deux transitions de $ dp [i] [j] [k] $.
(2) Quand $ k = 1 $ Il ne peut y avoir qu'une seule façon de choisir un modèle de colonnes différent de $ dp [i] [j] [k] $, car il ne doit pas y en avoir plus d'une dans une ligne.
Après avoir considéré la transition, (la somme de $ dp [n-1] $) est la réponse.
Comme mentionné ci-dessus, le nombre total de motifs de ① et ② doit être calculé comme réponse. De plus, vous pouvez voir que le DP effectué en ① et ② est le même.
C.py
mod=10**9+7
n,m=map(int,input().split())
n,m=min(n,m),max(n,m)
dp=[[[0,0] for j in range(2)] for i in range(m)]
dp[0]=[[1,0],[1,0]]
for i in range(m-1):
for j in range(2):
for k in range(2):
if j==0 and k==0:
dp[i+1][j][1]+=dp[i][j][k]
dp[i+1][j+1][0]+=dp[i][j][k]
elif j==1 and k==0:
dp[i+1][j][1]+=dp[i][j][k]
dp[i+1][j-1][0]+=dp[i][j][k]
elif j==0 and k==1:
dp[i+1][j+1][0]+=dp[i][j][k]
else:
dp[i+1][j-1][0]+=dp[i][j][k]
for j in range(2):
for k in range(2):
dp[i+1][j][k]%=mod
ans=-2
for j in range(2):
for k in range(2):
ans+=dp[m-1][j][k]
ans%=mod
dp2=[[[0,0] for j in range(2)] for i in range(n)]
dp2[0]=[[1,0],[1,0]]
for i in range(n-1):
for j in range(2):
for k in range(2):
if j==0 and k==0:
dp2[i+1][j][1]+=dp2[i][j][k]
dp2[i+1][j+1][0]+=dp2[i][j][k]
elif j==1 and k==0:
dp2[i+1][j][1]+=dp2[i][j][k]
dp2[i+1][j-1][0]+=dp2[i][j][k]
elif j==0 and k==1:
dp2[i+1][j+1][0]+=dp2[i][j][k]
else:
dp2[i+1][j-1][0]+=dp2[i][j][k]
for j in range(2):
for k in range(2):
dp2[i+1][j][k]%=mod
for j in range(2):
for k in range(2):
ans+=dp[n-1][j][k]
ans%=mod
print(ans)
Problème D1
C'est un problème qui n'a pu être envisagé et organisé. C'est dommage car c'est le genre de problème que je ne veux pas le plus laisser tomber.
Dans ce problème, $ N $ est jusqu'à environ 500, donc vous pouvez voir que $ O (N ^ 3) $ est correct et $ O (N ^ 4) $ ne l'est pas. Maintenant, disons que vous permutez entre le $ i $ th et le $ j $ th, et essayez tous les ** décalages cycliques avec $ O (N) $ pour cette parenthèse **.
Ici, la condition pour établir la chaîne de parenthèses est que ** "(" est +1, ")" est considéré comme -1 et la somme cumulée est toujours 0 ou plus et le dernier élément est 0 **. Même si vous permutez ici, le nombre de "(" et ")" ne change pas, il vous suffit donc de vérifier si la valeur de l'élément qui minimise la somme cumulée est égale ou supérieure à 0 **. En outre, le décalage cyclique est facile à comprendre en déplaçant le premier élément comme indiqué ci-dessous (modèle dans l'échantillon 1).

Par conséquent, ** il est bon qu'il soit toujours égal ou supérieur à 0 du côté droit ou du côté gauche lors de l'exécution d'un décalage cyclique **. Cela signifie que si la somme cumulée prise par l'avant est sum1, la somme cumulée prise par l'arrière est sum2, le minimum cumulé pris par l'avant est amin1 et le minimum cumulé pris par l'arrière est amin2, l'indice de la position la plus à gauche est $. Lorsque k $, la condition du côté droit est $ amin2 [k + 1] -asum1 [k] \ geqq 0 $ et la condition du côté gauche est $ amin1 [k + 1] + asum2 [k] \ geqq 0 $. Si l'une de ces conditions est remplie, on peut dire que les parenthèses sont un décalage cyclique (✳︎).
D'après ce qui précède, c'est un programme suffisamment rapide car c'est $ O (N) $ pour le pré-calcul de la somme cumulée et le jugement dans chaque décalage cyclique.
(✳︎)… Ma tête s'est cassée dans la partie cumulative, mais ce n'est pas si difficile….
D.cc
//Options de débogage:-fsanitize=undefined,address
//Optimisation du compilateur
#pragma GCC optimize("Ofast")
//Inclure etc.
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
//macro
//pour boucle
//L'argument est(Variables dans la boucle,Amplitude de mouvement)Ou(Variables dans la boucle,Premier numéro,Nombre d'extrémités)、のどちらOu
//Les variables de boucle sont incrémentées de 1 pour celles sans D et les variables de boucle sont décrémentées de 1 pour celles avec D.
//FORA est une gamme de déclaration(Si c'est difficile à utiliser, effacez-le)
#define REP(i,n) for(ll i=0;i<ll(n);i++)
#define REPD(i,n) for(ll i=n-1;i>=0;i--)
#define FOR(i,a,b) for(ll i=a;i<=ll(b);i++)
#define FORD(i,a,b) for(ll i=a;i>=ll(b);i--)
#define FORA(i,I) for(const auto& i:I)
//x est un conteneur tel que vector
#define ALL(x) x.begin(),x.end()
#define SIZE(x) ll(x.size())
//constant
#define INF 1000000000000 //10^12:∞
#define MOD 1000000007 //10^9+7:Droit commun
#define MAXR 100000 //10^5:Portée maximale de la baie
//Abréviation
#define PB push_back //Insérer
#define MP make_pair //constructeur de paires
#define F first //Le premier élément de paire
#define S second //Le deuxième élément de paire
signed main(){
//Spécification de sortie du nombre de chiffres fractionnaires
//cout<<fixed<<setprecision(10);
//Code pour accélérer la saisie
//ios::sync_with_stdio(false);
//cin.tie(nullptr);
ll n;cin>>n;
string s;cin>>s;
ll ma=0;pair<ll,ll> now={1,1};
if(n%2!=0 or ll(count(ALL(s),'('))!=ll(n/2)){
cout<<0<<endl;
cout<<"1 1"<<endl;
return 0;
}
vector<ll> checks(n);
REP(i,n){
if(s[i]=='('){
checks[i]=1;
}else{
checks[i]=-1;
}
}
REP(i,n){
REP(j,n){
vector<ll> check=checks;
swap(check[i],check[j]);
//Prenez la somme cumulée du front
vector<ll> asum1(n);asum1[0]=check[0];
REP(k,n-1)asum1[k+1]=asum1[k]+check[k+1];
//Prenez la somme cumulée par derrière
vector<ll> asum2(n);asum2[n-1]=check[n-1];
REPD(k,n-1)asum2[k]=asum2[k+1]+check[k];
//Prenez le minimum cumulatif de l'avant(Somme cumulée)
vector<ll> amin1(n);amin1[0]=asum1[0];
REP(k,n-1)amin1[k+1]=min(amin1[k],asum1[k+1]);
//Prenez le minimum cumulatif par derrière(Somme cumulée)
vector<ll> amin2(n);amin2[n-1]=asum1[n-1];
REPD(k,n-1)amin2[k]=min(amin2[k+1],asum1[k]);
ll ans=0;
if(amin1[n-1]>=0)ans++;
REP(k,n-1){
if(amin2[k+1]-asum1[k]>=0 and amin1[k]+asum2[k+1]>=0){
ans++;
}
}
if(ma<ans){
ma=ans;
now={i+1,j+1};
}
}
}
cout<<ma<<endl;
cout<<now.F<<" "<<now.S<<endl;
}
Après le problème D2
Je ne résoudrai pas cette fois.
Recommended Posts