Créer une fonction pour visualiser / évaluer le résultat du clustering
Visualisez et évaluez les résultats groupés
Implémentation d'une fonction qui visualise le résultat du clustering avec vae etc. et affiche la valeur d'évaluation.
Renommez le libellé de la bonne réponse et le numéro de cluster qui est le résultat du clustering par décision majoritaire, Dessinez une pseudo matrice de confusion et calculez la précision. Il affiche également les valeurs d'évaluation par NMI et ARI. J'ai l'intention de créer une fonction qui peut évaluer à quel point il est bien groupé.
#Importer les bibliothèques requises
import numpy as np
import pandas as pd
import sklearn
#Afficher les résultats du tracé dans le notebook lors de l'utilisation du notebook Jupyter
import matplotlib.pyplot as plt
%matplotlib inline
df_result_dense = pd.read_csv('result-dense.csv')
df_result_dense
| Unnamed: 0 | labels | k-means | |
|---|---|---|---|
| 0 | 0 | 7 | 2 |
| 1 | 1 | 2 | 5 |
| 2 | 2 | 1 | 9 |
| 3 | 3 | 0 | 3 |
| 4 | 4 | 4 | 7 |
| ... | ... | ... | ... |
| 9995 | 9995 | 2 | 5 |
| 9996 | 9996 | 3 | 0 |
| 9997 | 9997 | 4 | 7 |
| 9998 | 9998 | 5 | 4 |
| 9999 | 9999 | 6 | 6 |
10000 rows × 3 columns
def relabel(ans, labels):
df = pd.DataFrame()
df['ans'] = ans
df['labels'] = labels
relabel(df, 'ans', 'labels')
def relabel(df, ans, label):
#Renommer le plus proche de ans
# df[ans]Bonne réponse, df[labels]S'attendre à avoir une étiquette de cluster dans
labels = df[label].unique()
label_dic = {}
for i in labels:
counts = df[df[label] == i][ans].value_counts()
label_dic[i] = counts.index[0]
display(label_dic)
return list(pd.Series(df[label]).replace(label_dic))
relabel_k_means = relabel(df_result_dense, 'labels', 'k-means')
df_result_dense['relabel_k_means'] = relabel_k_means
{2: 7, 5: 2, 9: 1, 3: 0, 7: 4, 1: 9, 4: 5, 8: 8, 6: 6, 0: 3}
from sklearn.metrics import accuracy_score
print(accuracy_score(df_result_dense['labels'],df_result_dense['k-means']))
print(accuracy_score(df_result_dense['labels'],df_result_dense['relabel_k_means']))
0.1841
0.9309
ans = df_result_dense['labels']
labels = df_result_dense['k-means']
relabels = df_result_dense['relabel_k_means']
def eval_cluster(ans, labels, relabels):
import seaborn as sns
from sklearn.metrics import confusion_matrix
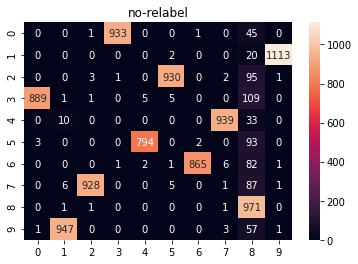
plt.title('no-relabel')
sns.heatmap(confusion_matrix(ans, labels), annot=True, fmt='d')
plt.show()
from sklearn.metrics import normalized_mutual_info_score
print("nmi: " + str(normalized_mutual_info_score(ans, labels)))
from sklearn.metrics.cluster import adjusted_rand_score
print("ari: " + str(adjusted_rand_score(ans, labels)))
plt.title('relabel')
sns.heatmap(confusion_matrix(ans, relabels), annot=True, fmt='d')
plt.show()
print("acc: " + str(accuracy_score(ans, relabels)))
eval_cluster(ans, labels, relabels)
nmi: 0.8804532777228216
ari: 0.8405114317316403

acc: 0.9309
Recommended Posts