Tensorflow, il semble que même la valeur propre de la matrice puisse être automatiquement différenciée
Synopsis
Dans Tensorflow, même s'il y a un endroit pour trouver la diagonalisation (valeur propre) de la matrice au milieu lors de la différenciation automatique par la méthode du gradient, il semble qu'elle puisse être minimisée par la différenciation automatique et la méthode du gradient sans aucun problème.
J'ai également ajouté une méthode pour ʻapply_gradientmanuellement en utilisantGradientTape et une méthode pour minimiser` la fonction de perte en se différenciant automatiquement.
Version
- Tensorflow 2.1.0
- Python 3.7.3 (Anaconda)
- Windows 10
Le point
Lorsque vous préparez une matrice 3 en 3 appropriée $ A $ et calculez sa valeur propre $ \ lambda $, la différenciation de chaque composant de la matrice $ A $ par rapport à la plus petite valeur propre $ \ lambda_0 $ $ d \ lambda_0 / Lorsque vous voulez calculer dA $ (c'est une matrice 3 par 3 car elle est pour chaque composant).
Vous pouvez calculer $ d \ lambda_0 / dA $ avec le code suivant. Puisqu'il est en mode Eager, utilisez GradientTape () pour saisir le graphe de calcul pour le calcul différentiel.
import tensorflow as tf
A = tf.random.uniform(shape=(3, 3))
with tf.GradientTape() as g:
g.watch(A)
val, vec = tf.linalg.eigh(A)
val0 = val[0]
grad0 = g.gradient(val0, A)
print(A)
print(val)
print(grad0)
A
tf.Tensor(
[[0.6102723 0.17637432 0.38962376]
[0.3735156 0.6306771 0.19141042]
[0.34370267 0.7677151 0.4024818 ]], shape=(3, 3), dtype=float32)
val
tf.Tensor([-0.25994763 0.34044334 1.5629349 ], shape=(3,), dtype=float32)
grad0
tf.Tensor(
[[ 5.3867564e-04 0.0000000e+00 0.0000000e+00]
[ 3.0038984e-02 4.1877732e-01 0.0000000e+00]
[-3.5372321e-02 -9.8626012e-01 5.8068389e-01]], shape=(3, 3), dtype=float32)
Enfin, puisque seule la moitié inférieure est non nulle, on suppose que «haut» n'utilise que la moitié inférieure.
En fait, l'opération de tranche est effectuée comme «val0 = val [0]», qui est le point principal. En d'autres termes, il fait plus que simplement trouver la valeur unique. G.gradient (val, A) sans couper une valeur unique fonctionne sans aucun problème, mais j'ai donné la priorité à la facilité d'explication avec des formules mathématiques.
Aussi, val0 = val [0], mais cela se fait dans l'environnement GradientTape (). Si toutes les opérations que vous souhaitez connecter les différentiels de cette manière ne sont pas effectuées dans cet environnement, g.gradient () retournera None.
application
Puisqu'il est automatiquement différencié, il est possible d'insérer des opérations avant et après. Je vais l'essayer à partir de maintenant.
Statut
Préparez six valeurs, organisez-les dans une matrice symétrique et calculez les valeurs propres. Soit cela est vrai pour une certaine condition, soit l'erreur est calculée comme étant une fonction d'erreur, qui est différenciée.
- Calcul avant valeur propre: structure matricielle
- Calcul après valeur propre: somme des erreurs entre la valeur propre et la valeur cible
Ensuite, mettons à jour la valeur d'origine par la méthode du gradient, qui semble être une bibliothèque d'apprentissage automatique appelée Tensorflow.
$ r $ contient 6 composantes de la matrice symétrique 3x3, et $ t = (t_0, t_1, t_2) $ sont les valeurs propres souhaitées.
r = \left(r_0, r_1, \cdots, r_5\right)
Trier ceci
A_h=\left(\begin{array}{ccc}
\frac{1}{2} r_0 & 0 & 0 \\
r_3 & \frac{1}{2} r_1 & 0 \\
r_5 & r_4 & \frac{1}{2} r_2
\end{array}
\right)
A = A_h + A_h^T
Construisez la matrice $ A $ comme, et trouvez la valeur unique de this. En supposant que $ \ lambda = (\ lambda_0, \ lambda_1, \ lambda_2) $ est un tableau de trois valeurs uniques de $ A $
L = \sum_{i=0}^2\left(t_i - \lambda_i\right)^2
Est la fonction de perte. Former $ r $
\frac{\partial L}{\partial r_n} = \sum_{i,j,k}\frac{\partial A_{ij}}{\partial r_n}\frac{\partial \lambda_k}{\partial A_{ij}}\frac{\partial L}{\partial \lambda_k}
Est un calcul nécessaire. Le milieu $ \ frac {\ partial \ lambda_k} {\ partial A_ {ij}} $ est la différenciation des valeurs propres par les composantes de la matrice.
En analyse, il peut être calculé en trouvant la solution $ \ lambda $ de $ \ det (A- \ lambda I) = 0 $, mais honnêtement, s'il dépasse 3 dimensions, il sera ingérable à moins que ce ne soit une matrice très clairsemée. .. Par conséquent, je m'appuie sur tensorflow, qui peut effectuer des calculs numériques.
Appel différentiel manuel
Tout d'abord, c'est ennuyeux, mais comment suivre le processus.
Préparation
r = tf.Variable(initial_value=tf.random.uniform(shape=[6]))
t = tf.constant([1.0, 1.0, 1.0])
«r» contient 6 composants de la matrice symétrique 3x3, et «t» est les valeurs propres souhaitées. Ici, un nombre aléatoire uniforme est donné à «r» comme valeur initiale. De plus, «t» est égal à 1.
Calcul pour la différenciation automatique
with tf.GradientTape() as g:
g.watch(r)
A = 0.5*tf.linalg.diag(r[0:3])
A = A + tf.pad(tf.linalg.diag(r[3:5]), [[0, 1], [1, 0]], "CONSTANT")
A = A + tf.sparse.to_dense(tf.sparse.SparseTensor(indices=[[0, 2]], values=[r[5]], dense_shape=(3, 3)))
A = A + tf.transpose(A)
eigval, eigvec = tf.linalg.eigh(A)
d = tf.reduce_sum((eigval - t)**2)
Puisque le traitement à partir d'ici est la cible de la différenciation automatique, il se fait dans GradientTape.
Il existe deux manières de remplacer un composant spécifique de «A» par «r», l'une consiste à utiliser «diag» pour l'introduction et l'autre à utiliser «SparseTensor».
J'ai utilisé tf.linalg.diag comme fonction pour organiser trois composants diagonaux et deux composants à côté d'eux.
Cependant, j'utilise pad pour l'organiser à un endroit à partir du composant diagonal, mais le document introduit l'option de l'organiser dans un endroit qui est k décalé de la diagonale en utilisant l'option k. Et quand vous l'utilisez
A = A + tf.linalg.diag(r[3:5], k=1)
Je peux écrire, mais d'une manière ou d'une autre l'option k ne fonctionnait pas. J'utilise donc volontairement pad.
De plus, en tant que méthode pour définir un seul des $ r_5 $ au coin de la matrice, Tensor n'a pas de spécification d'index assignée comme numpy, donc c'est gênant, mais il est défini en ajoutant via une matrice creuse. Fait.
Après avoir construit ʻA, il est normal de calculer la diagonalisation ʻeigh et la fonction de perte. Ici, la fonction de perte $ L $ est «d». Je suis désolé, c'est compliqué.
Calcul de la différenciation
grad_dr = g.gradient(d, r)
Encore une fois, d est la fonction de perte $ L $.
Un tensol de longueur 6 est attribué à «grad_dr». Cela a atteint l'objectif de cet article.
Mettre à jour la valeur
Utilisez un optimiseur approprié.
opt = tf.keras.optimizers.Adam()
opt.apply_gradients([(grad_dr, r), ])
Parce que vous pouvez utiliser la différenciation ici
opt.minimize(d, var_list=[r])
Puis
TypeError: 'tensorflow.python.framework.ops.EagerTensor' object is not callable
J'obtiens l'erreur. En effet, le premier argument «d» doit être une fonction sans argument qui renvoie une fonction de perte, et non «Tensor». Cette méthode sera décrite plus loin.
Exemple de sortie
Par exemple, le «r» initial
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.12108588, 0.8856114 , 0.00449729, 0.22199583, 0.8411281 ,
0.54751956], dtype=float32)>
À ce moment-là, «A» est
tf.Tensor(
[[0.12108588 0.22199583 0.54751956]
[0.22199583 0.8856114 0.8411281 ]
[0.54751956 0.8411281 0.00449729]], shape=(3, 3), dtype=float32)
Ce sera. Puis le différentiel $ \ frac {dL} {dr} $ de la fonction de perte
tf.Tensor([-1.757829 -0.22877683 -1.991005 0.88798404 3.3645139 2.1900787 ], shape=(6,), dtype=float32)
A été calculé. Si vous appliquez ceci comme ʻopt.apply_gradients ([(grad_dr, r),]) , la valeur de r` sera
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.12208588, 0.8866114 , 0.00549729, 0.22099583, 0.8401281 ,
0.5465196 ], dtype=float32)>
Vous pouvez voir qu'elle est légèrement différente de la première valeur «[0.12108588, 0.8856114, 0.00449729, 0.22199583, 0.8411281, 0.54751956]».
Vers la convergence
Pourquoi voulez-vous le répéter? Si l'optimisation réussit, vous obtiendrez une matrice symétrique avec les 1 valeurs propres définies par t.
while d > 1e-8:
with tf.GradientTape() as g:
g.watch(r)
A = 0.5*tf.linalg.diag(r[0:3])
A = A + tf.pad(tf.linalg.diag(r[3:5]), [[0, 1], [1, 0]], "CONSTANT")
A = A + tf.sparse.to_dense(tf.sparse.SparseTensor(indices=[[0, 2]], values=[r[5]], dense_shape=(3, 3)))
A = A + tf.transpose(A)
eigval, eigvec = tf.linalg.eigh(A)
d = tf.reduce_sum((eigval - t)**2)
grad_dr = g.gradient(d, r)
opt.apply_gradients([(grad_dr, r), ])
print("---------------")
print(r)
print(eigval)
print(d)
d est l'erreur carrée, et elle se répète dans la boucle while jusqu'à ce qu'elle tombe en dessous d'un certain niveau.
Quand tu fais ça
---------------
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.10630785, 0.18287621, 0.14753745, 0.16277793, 0.7271476 ,
0.08771187], dtype=float32)>
tf.Tensor([-0.56813365 0.07035071 0.9315046 ], shape=(3,), dtype=float32)
tf.Tensor(3.3279824, shape=(), dtype=float32)
---------------
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.10730778, 0.18387613, 0.14853737, 0.16177836, 0.72614765,
0.0867127 ], dtype=float32)>
tf.Tensor([-0.5661403 0.07189684 0.9309651 ], shape=(3,), dtype=float32)
tf.Tensor(3.3189366, shape=(), dtype=float32)
---------------
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([0.10830763, 0.18487597, 0.1495372 , 0.1607792 , 0.72514784,
0.08571426], dtype=float32)>
tf.Tensor([-0.564147 0.07343995 0.9304282 ], shape=(3,), dtype=float32)
tf.Tensor(3.3099096, shape=(), dtype=float32)
Ce qui suit est omis
Vous pouvez voir que «r» et «A» changent petit à petit. Quand il converge,
<tf.Variable 'Variable:0' shape=(6,) dtype=float32, numpy=
array([ 9.9999946e-01, 9.9999988e-01, 9.9999732e-01, 6.9962436e-05,
4.2644251e-07, -1.1688111e-14], dtype=float32)>
tf.Tensor([0.9999294 0.9999973 1.0000702], shape=(3,), dtype=float32)
tf.Tensor(9.917631e-09, shape=(), dtype=float32)
est devenu. «A» semble être une matrice unitaire. C'était la même chose après plusieurs tentatives, il semble donc que trouver une matrice avec une seule valeur propre de cette façon conduit à une matrice unitaire.
Si vous comptez le nombre de boucles, il semble que cela nécessite des milliers de pas tels que 3066, 2341, 3035.
Comment obtenir une différenciation automatique et un traitement de mise à jour
Le but est d'utiliser «minimiser ()».
Pour la construction de la matrice symétrique «A», reportez-vous à la section «Calcul pour la différenciation automatique» ci-dessus.
r = tf.Variable(initial_value=tf.random.uniform(shape=[6]))
t = tf.constant([1.0, 1.0, 1.0])
def calc_eigval(r):
A = 0.5*tf.linalg.diag(r[0:3])
A = A + tf.pad(tf.linalg.diag(r[3:5]), [[0, 1], [1, 0]], "CONSTANT")
A = A + tf.sparse.to_dense(tf.sparse.SparseTensor(indices=[[0, 2]], values=[r[5]], dense_shape=(3, 3)))
A = A + tf.transpose(A)
eigval, eigvec = tf.linalg.eigh(A)
return eigval
def calc_loss(r):
eigval = calc_eigval(r)
d = tf.reduce_sum((eigval - t)**2)
return d
opt = tf.keras.optimizers.Adam()
loss = lambda: calc_loss(r)
while d > 1e-8:
opt.minimize(loss, var_list=[r])
print("---------------")
print(r)
print(calc_eigval(r))
print(calc_loss(r))
calc_eigval est une fonction qui renvoie une valeur unique, et calc_loss est une fonction qui calcule une fonction de perte.
loss est une fonction qui calcule la fonction de perte sur la base de la valeur de r à ce stade et renvoie le Tensor, si la fonction estloss ().
Le premier argument de «minimiser» nécessite une fonction sans un tel argument. Alors
J'obtenais une erreur lorsque j'ai passé «d», qui a été calculé par «gradientTape», pour «minimiser».
Vous pouvez écrire calc_eigval dans calc_loss, mais je voulais voir comment les valeurs propres ont changé pendant la boucle, alors j'ai préparé une autre fonction.
def calc_loss (r) et loss = lambda: calc_loss (r) sont les points pour utiliser minimiser. Si vous définissez «calc_loss» depuis le début sans argument, vous pouvez le passer à «minimiser» tel quel.
De toute façon, je n'ai plus à gérer moi-même.
Si vous exécutez le code ci-dessus tel quel avec la fonction main, l'état de convergence sera affiché.
Autre
En prime, environ 4 modèles qui ont démarré la convergence des valeurs propres avec des valeurs initiales aléatoires. Les lignes sont <font color = # 1f77b4> valeur unique 1 </ font>, valeur unique 2 </ font> et <font color = # 2ca02c> valeur unique 3 </ font>. L'extrémité droite est 1, qui est la cible de la convergence, et vous pouvez voir qu'elle fonctionne correctement.
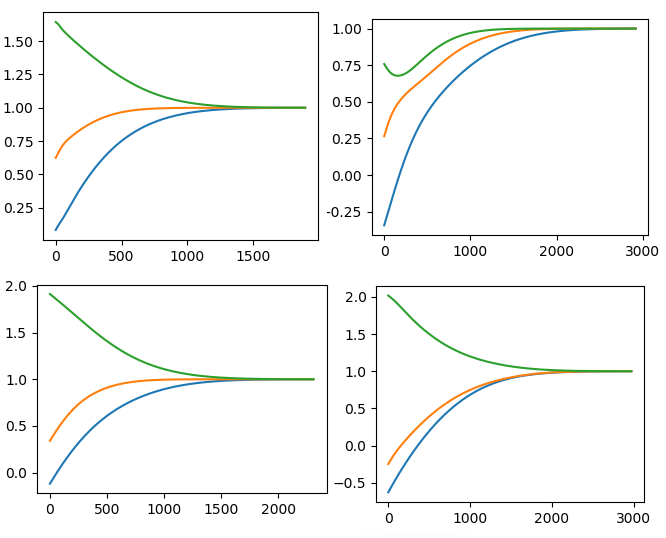
Une différenciation d'ordre supérieur est également possible en imbriquant GradientTape (). Il semble que la couverture de la différenciation automatique soit plus large que ce à quoi je m'attendais.
La raison de l'article principal de GradientTape est que je ne savais pas comment utiliser minimiser au début et que je pensais que je devais faire ʻapply_gradient` manuellement. Après avoir écrit la majeure partie de l'article, j'ai su le faire avec «minimiser».
Recommended Posts