Acquisition d'un groupe de points 3D avec Pepper de Softbank (Choregraphe, Python)
2015/03/01 Aldebaran Atelier Akihabara Pepper Development Touch & Try Record
À l'aide de la caméra 3D Pepper's eye (capteur de profondeur Xtion), j'ai créé une boîte pour acquérir un groupe de points 3D. Article de référence: Thorikawa's [Pepper-kun Point Cloud](http://qiita.com/thorikawa/items/a625b4766dcd283b783b#pcd%E3%83%95%E3%82%A1%E3%82%A4%E3% 83% AB% E3% 81% AE% E5% 87% BA% E5% 8A% 9B)
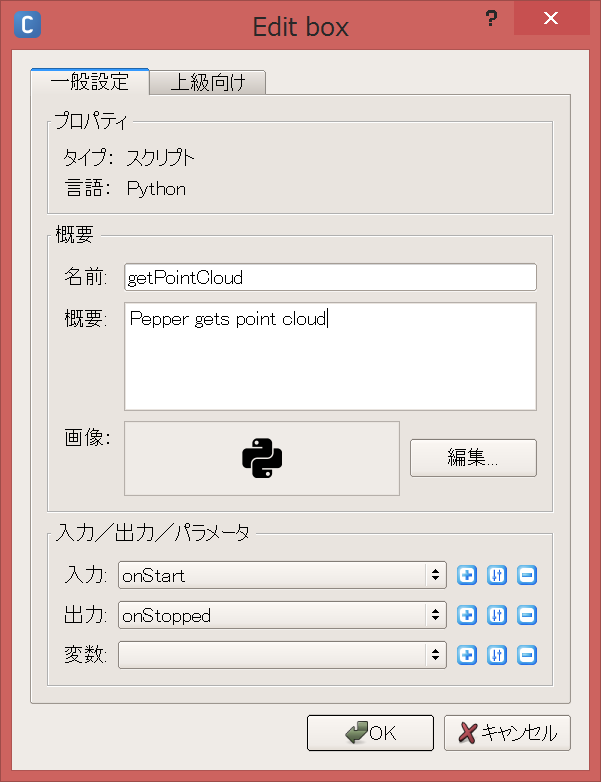
Créer une boîte getPointCloud
Lancez Choregraphe 2.1.2 et créez une boîte pour votre script Python. Cliquez avec le bouton droit de la souris → Nouvelle boîte → Script Python ou Standard de la bibliothèque de boîtes → Modèles → Script Python.

Entrez le nom et le contour de la boîte et appuyez sur le bouton OK.
Cliquez avec le bouton droit sur la boîte et modifiez le script Python.

Définissez la fonction getPointCloud comme suit:
class MyClass(GeneratedClass):
def __init__(self):
GeneratedClass.__init__(self)
def onLoad(self):
#put initialization code here
pass
def onUnload(self):
#put clean-up code here
pass
def getPointCloud(self):
import argparse
import Image
import time
# Camera parameters (only tested on Pepper)
# Focal length
FX = 525.0 / 2
FY = 525.0 / 2
# Optical center
CX = 319.5 / 2
CY = 239.5 / 2
# millimeter to meter
UNIT_SCALING = 0.001
NAME = "depth_camera"
CAMERA_ID = 2 # depth
RESOLUTION = 1 # 320*240
FRAMERATE = 15
COLOR_SPACE = 17 # mono16 Note: this is not documented as of Dec 14, 2014
video = ALProxy('ALVideoDevice')
client = video.subscribeCamera(NAME, CAMERA_ID, RESOLUTION, COLOR_SPACE, FRAMERATE)
try:
image = video.getImageRemote(client)
if image is None:
print 'Cannot obtain depth image.'
exit()
width = image[0]
height = image[1]
array = image[6]
cloud = []
for v in range(height):
for u in range(width):
offset = (v * width + u) * 2
depth = ord(array[offset]) + ord(array[offset+1]) * 256
x = (u - CX) * depth * UNIT_SCALING / FX
y = (v - CY) * depth * UNIT_SCALING / FY
z = depth * UNIT_SCALING
cloud.append((x, y, z))
finally:
video.unsubscribe(client)
fileName = '/home/nao/recordings/cameras/cloud%f.ply' % time.time()
f = open(fileName, 'w')
num = len(cloud)
header = '''ply
format ascii 1.0
comment Pepper 3D generated
element vertex %d
property float x
property float y
property float z
end_header
'''
f.write(header % (width*height))
f.write("\n")
for c in cloud:
f.write('%f %f %f' % (c[0], c[1], c[2]))
f.write("\n")
f.close()
pass
def onInput_onStart(self):
#self.onStopped() #activate the output of the box
self.getPointCloud()
pass
def onInput_onStop(self):
self.onUnload() #it is recommended to reuse the clean-up as the box is stopped
self.onStopped() #activate the output of the box
Courir
Téléchargez sur le robot et jouez (F5), Enregistrez localement le groupe de points 3D au format pli dans Pepper.
Celui connecté par la ligne est exécuté en premier.

Même s'il n'est pas connecté par une ligne, après avoir été téléchargé sur le robot, vous pouvez l'exécuter par lui-même en cliquant sur l'entrée (bouton de lecture).

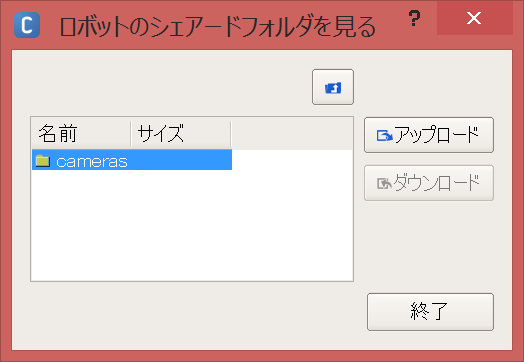
Télécharger le fichier de groupe de points
Dans la barre de menus, cliquez sur Connexion → Avancé → Transférer un fichier ID:nao Password:nao Vous pouvez voir le dossier local de Pepper avec.
Le fichier de groupe de points est enregistré dans les enregistrements / caméras /, alors téléchargeons-le.



Affichage du groupe de points
Si vous l'ouvrez avec Meshlab, vous pouvez voir le groupe de points 3D.

Résumé
En utilisant la caméra 3D de Pepper, j'ai pu enregistrer le groupe de points 3D avec ply, le télécharger localement et l'afficher avec Meshlab. Ensuite, j'aimerais faire du SLAM qui utilise les données brutes de Depth (16 bits, image png) pour créer une carte et estimer la position personnelle en même temps. Créez un ensemble de données d'odométrie (accélération), RVB (couleur) et profondeur (profondeur) lorsque vous vous déplacez sur la piste cible (move_traj.pmt).
Supplément
SLAM est utilisé lorsque vous souhaitez déplacer le robot de manière autonome sur une certaine trajectoire ou lorsque vous souhaitez comprendre l'environnement de conduite. Il est plus précis et fiable que les capteurs internes tels que les encodeurs et les capteurs d'accélération.
La caméra 3D peut également être appliquée à l'extraction de plan, à la détection d'objet, à la reconnaissance faciale, etc. Puisque Pepper a deux caméras 2D (caméras RVB), vous pouvez obtenir un groupe de points si vous utilisez une caméra stéréo (n'y a-t-il qu'une partie qui semble commune? W) et un groupe de points pouvant être obtenu à partir d'une caméra 3D. Vous pouvez également le colorier.
- Reposez-vous toujours lorsque vous n'utilisez pas de poivre. Pour prolonger la vie. Lol
Recommended Posts