Données d'entraînement et données de test (Que sont X_train et y_train?) ②
Dans la continuité du ① précédent, nous allons diviser un peu plus pratiquement les données d'entraînement et les données de test.
Préparez d'abord les données.
Maintenant, il y a deux variables x.
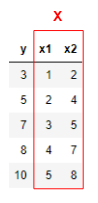 Ainsi, en machine learning, lorsqu'il y a deux variables ou plus x
Nous les combinerons en un seul et les traiterons comme des majuscules $ \ mathbf {X} $.
Ainsi, en machine learning, lorsqu'il y a deux variables ou plus x
Nous les combinerons en un seul et les traiterons comme des majuscules $ \ mathbf {X} $.
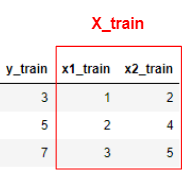
Ensuite, divisez-le en données d'entraînement et en données de test.
Données d'entraînement
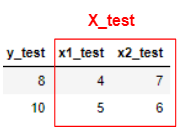
 données de test
données de test
 Ensuite, nous créerons une formule modèle à partir des données d'entraînement.
Si cela est calculé par la méthode des moindres carrés, il peut être obtenu comme suit.
Ensuite, nous créerons une formule modèle à partir des données d'entraînement.
Si cela est calculé par la méthode des moindres carrés, il peut être obtenu comme suit.
Et nous appliquerons cela aux données de test.
D'après ce qui précède, pour y_test des données de réponse correctes J'ai trouvé que le y_pred auquel je m'attendais était à peu près correct.
S'il y a deux ou plus $ x $ pour $ y $ En gros, pensez aux données d'entraînement et aux données de test comme ci-dessus.
Dans le machine learning réel, pour des données comme celle-ci y est le loyer, x1 et x2 sont les éléments constitutifs (marche en gare, âge, etc.) Nous analysons les données.
Aussi, l'article précédent ① et cet article ② Les deux utilisent une méthode appelée régression linéaire. J'espère publier à nouveau dans un proche avenir.
Recommended Posts