Réintroduction à Docker
Cela fait presque quatre ans depuis 2016 d'utiliser Docker au travail. Je vais essayer d'organiser les connaissances sur Docker que j'ai apprises de manière fragmentaire jusqu'à présent à la suite du chat technique de l'entreprise. Cette phrase explore la technologie utilisée derrière docker, pourquoi docker est créé à l'origine, plutôt que les commandes d'opération de docker et comment écrire un Dockerfile.
table des matières
- Retour sur l'évolution de l'infrastructure informatique
- Virtualisation
- Docker --Caractéristiques de Docker
~ Retour sur l'évolution de l'infrastructure informatique ~
L'infrastructure informatique a subi diverses évolutions environ 70 ans après l'invention des ordinateurs. Dans ce processus, diverses technologies sont nées pour permettre une utilisation efficace des ressources de l'infrastructure informatique. L'origine de la virtualisation actuelle des serveurs est devenue la technologie de virtualisation utilisée pour les mainframes dans les années 1970, et après cela, la virtualisation des serveurs CPU x86 avec la naissance de VMWare a été promue vers 1999.
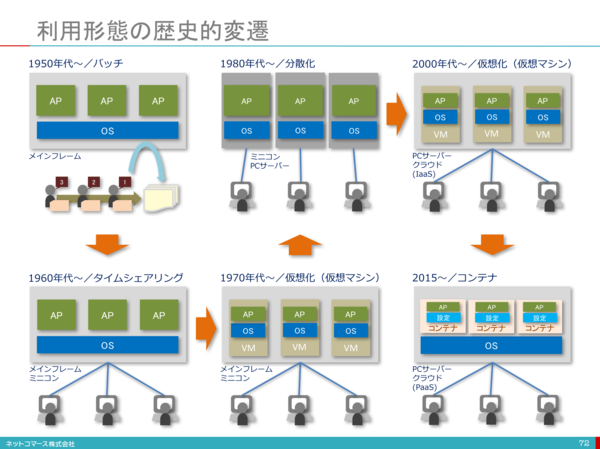 Le chiffre est basé sur [1].
Le chiffre est basé sur [1].
Indispensable à l'ère du cloud ~ virtualisation ~
Il existe différents types de virtualisation, même si cela s'appelle la virtualisation. Il existe de nombreux mots clés tels que la virtualisation du réseau, la virtualisation des serveurs et la virtualisation des applications. Ici, nous résumerons principalement la virtualisation des serveurs.
Virtualisation des serveurs
La virtualisation des serveurs consiste à fonctionner sur un serveur physique comme s'il s'agissait de plusieurs serveurs. La virtualisation des serveurs entraîne une réduction des coûts en réduisant le nombre de serveurs. Alors, quel type de méthode est la virtualisation des serveurs? Chaque fois que je recherche la virtualisation sur le net, je comprends qu'il existe un type d'hôte et un type d'hyperviseur. Cependant, en regardant la définition de l'hyperviseur dans wikipedia, on peut dire que tous ces deux types sont en fait des hyperviseurs. En premier lieu, [Hypervisor](https://ja.wikipedia.org/wiki/%E3%83%8F%E3%82%A4%E3%83%91%E3%83%BC%E3%83%90% E3% 82% A4% E3% 82% B6) [2] est un programme de contrôle pour la réalisation d'une machine virtuelle (machine virtuelle), qui est l'une des technologies de virtualisation informatique en termes informatiques. Parfois appelé un moniteur virtuel ou un système d'exploitation virtuel. Selon la définition de wikipedia, il existe deux types d'hyperviseurs.
- Hyperviseur de type 1 ("natif" ou "métal nu")
L'hyperviseur s'exécute directement sur le matériel et tous les systèmes d'exploitation (OS invités) s'exécutent sur l'hyperviseur. «Hyperviseur» au sens étroit se réfère uniquement à cela.
Produit: Microsoft Hyper-V, Citrix XenServer

- Hyperviseur de type 2 ("hôte")
Un autre système d'exploitation s'exécute d'abord sur le matériel (ce système d'exploitation s'appelle le système d'exploitation hôte), puis l'hyperviseur s'exécute (en tant qu'application du système d'exploitation hôte), puis un autre système d'exploitation (ce système d'exploitation) s'exécute sur l'hyperviseur. Il s'agit d'une méthode d'exécution d'un système d'exploitation (appelé OS invité). Au sens strict, le type 2 n'est pas inclus dans l'hyperviseur.
Produits: VirtualBox d'Oracle, Parallels Parallels Workstation et Parallels Desktop
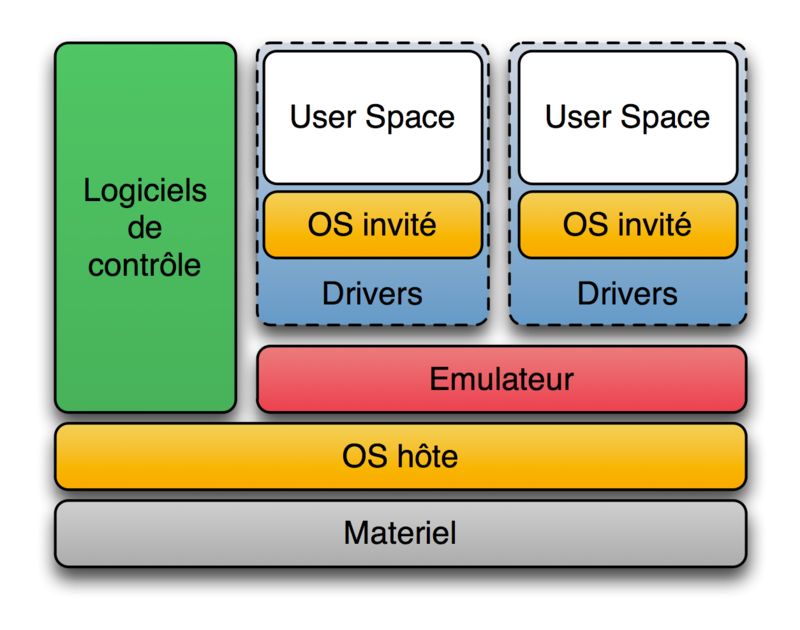
La virtualisation hébergée est souvent appelée Hypervisor Type2 et Hypervisor Type1.
Le type 1 présente l'avantage d'une vitesse de traitement élevée car les ressources sont complètement séparées et chaque serveur virtuel interagit directement avec le matériel. D'autre part, il présente également l'inconvénient de coûts d'installation élevés.
Le type 2 présente l'avantage d'un faible coût d'installation car vous pouvez créer un serveur virtuel immédiatement en installant le logiciel de virtualisation sur le système d'exploitation hôte, mais le serveur virtuel interagit avec le matériel via le système d'exploitation hôte, de sorte que la surcharge est importante. Il présente l'inconvénient de ralentir la vitesse de traitement.
Linux container (LXC) Normalement, dans un système d'exploitation hôte installé sur un serveur physique, plusieurs applications exécutées sur un même système d'exploitation utilisent les mêmes ressources système. À ce stade, plusieurs applications d'exploitation partagent un répertoire pour stocker les données et communiquer avec la même adresse IP définie sur le serveur. Par conséquent, si les versions de middleware et de bibliothèque utilisées par plusieurs applications sont différentes, il faut veiller à ne pas affecter les applications de l'autre [3]. En virtualisant le serveur, il est possible de résoudre complètement le problème ci-dessus en séparant l'ensemble du système d'exploitation et en implémentant une application dans chaque système d'exploitation virtuel, mais si vous le faites, le taux d'utilisation du serveur physique sera très élevé. Ce sera mauvais. C'est pourquoi Hypervisor a créé ici une technologie de virtualisation légère et de haut niveau.
LXC (English: Linux Containers) [4] est un système Linux isolé multiple sur un hôte de contrôle exécutant un noyau Linux. Logiciel de virtualisation au niveau du système d'exploitation qui s'exécute (conteneurs).
Le noyau Linux fournit une fonctionnalité appelée cgroups qui vous permet de limiter et de hiérarchiser les ressources (CPU, mémoire, bloc d'E / S, réseau, etc.), pour lesquelles vous devez utiliser des machines virtuelles. Absent. Vous pouvez également utiliser la fonction d'isolation d'espace de noms pour isoler complètement l'environnement du système d'exploitation du point de vue de l'application, en virtualisant les arborescences de processus, les réseaux, les identifiants d'utilisateur et les systèmes de fichiers montés. Peut être transformé en.
LXC combine les croupes de noyau avec la prise en charge des espaces de noms isolés pour fournir un environnement isolé pour les applications. cgroup cgroups (groupes de contrôle) [5] limite et isole l'utilisation des ressources du groupe de processus (CPU, mémoire, E / S disque, etc.) Fonctionnalités du noyau Linux. Rohit Seth a commencé le développement en septembre 2006 sous le nom de «process containers», a été renommé cgroups en 2007 et a été fusionné dans le noyau Linux 2.6.24 en janvier 2008. Depuis, de nombreuses fonctionnalités et contrôleurs ont été ajoutés.
L'explication de Linux man [6] est la suivante.
Control groups, usually referred to as cgroups, are a Linux kernel feature which allow processes to be organized into hierarchical groups whose usage of various types of resources can then be limited and monitored. The kernel's cgroup interface is provided through a pseudo-filesystem called cgroupfs. Grouping is implemented in the core cgroup kernel code, while resource tracking and limits are implemented in a set of per-resource-type subsystems (memory, CPU, and so on).
Les sous-systèmes doivent être compris comme un module de ressources du noyau. Les sous-systèmes contrôlés par cgroup sont les suivants.
cpu (since Linux 2.6.24; CONFIG_CGROUP_SCHED)
Cgroups can be guaranteed a minimum number of "CPU shares"
when a system is busy. This does not limit a cgroup's CPU
usage if the CPUs are not busy. For further information, see
Documentation/scheduler/sched-design-CFS.txt.
In Linux 3.2, this controller was extended to provide CPU
"bandwidth" control. If the kernel is configured with CON‐
FIG_CFS_BANDWIDTH, then within each scheduling period (defined
via a file in the cgroup directory), it is possible to define
an upper limit on the CPU time allocated to the processes in a
cgroup. This upper limit applies even if there is no other
competition for the CPU. Further information can be found in
the kernel source file Documentation/scheduler/sched-bwc.txt.
cpuacct (since Linux 2.6.24; CONFIG_CGROUP_CPUACCT)
This provides accounting for CPU usage by groups of processes.
Further information can be found in the kernel source file
Documentation/cgroup-v1/cpuacct.txt.
cpuset (since Linux 2.6.24; CONFIG_CPUSETS)
This cgroup can be used to bind the processes in a cgroup to a
specified set of CPUs and NUMA nodes.
Further information can be found in the kernel source file
Documentation/cgroup-v1/cpusets.txt.
memory (since Linux 2.6.25; CONFIG_MEMCG)
The memory controller supports reporting and limiting of
process memory, kernel memory, and swap used by cgroups.
Further information can be found in the kernel source file
Documentation/cgroup-v1/memory.txt.
devices (since Linux 2.6.26; CONFIG_CGROUP_DEVICE)
This supports controlling which processes may create (mknod)
devices as well as open them for reading or writing. The
policies may be specified as allow-lists and deny-lists.
Hierarchy is enforced, so new rules must not violate existing
rules for the target or ancestor cgroups.
Further information can be found in the kernel source file
Documentation/cgroup-v1/devices.txt.
freezer (since Linux 2.6.28; CONFIG_CGROUP_FREEZER)
The freezer cgroup can suspend and restore (resume) all pro‐
cesses in a cgroup. Freezing a cgroup /A also causes its
children, for example, processes in /A/B, to be frozen.
Further information can be found in the kernel source file
Documentation/cgroup-v1/freezer-subsystem.txt.
net_cls (since Linux 2.6.29; CONFIG_CGROUP_NET_CLASSID)
This places a classid, specified for the cgroup, on network
packets created by a cgroup. These classids can then be used
in firewall rules, as well as used to shape traffic using
tc(8). This applies only to packets leaving the cgroup, not
to traffic arriving at the cgroup.
Further information can be found in the kernel source file
Documentation/cgroup-v1/net_cls.txt.
blkio (since Linux 2.6.33; CONFIG_BLK_CGROUP)
The blkio cgroup controls and limits access to specified block
devices by applying IO control in the form of throttling and
upper limits against leaf nodes and intermediate nodes in the
storage hierarchy.
Two policies are available. The first is a proportional-
weight time-based division of disk implemented with CFQ. This
is in effect for leaf nodes using CFQ. The second is a throt‐
tling policy which specifies upper I/O rate limits on a
device.
Further information can be found in the kernel source file
Documentation/cgroup-v1/blkio-controller.txt.
perf_event (since Linux 2.6.39; CONFIG_CGROUP_PERF)
This controller allows perf monitoring of the set of processes
grouped in a cgroup.
Further information can be found in the kernel source file
tools/perf/Documentation/perf-record.txt.
net_prio (since Linux 3.3; CONFIG_CGROUP_NET_PRIO)
This allows priorities to be specified, per network interface,
for cgroups.
Further information can be found in the kernel source file
Documentation/cgroup-v1/net_prio.txt.
hugetlb (since Linux 3.5; CONFIG_CGROUP_HUGETLB)
This supports limiting the use of huge pages by cgroups.
Further information can be found in the kernel source file
Documentation/cgroup-v1/hugetlb.txt.
pids (since Linux 4.3; CONFIG_CGROUP_PIDS)
This controller permits limiting the number of process that
may be created in a cgroup (and its descendants).
Further information can be found in the kernel source file
Documentation/cgroup-v1/pids.txt.
rdma (since Linux 4.11; CONFIG_CGROUP_RDMA)
The RDMA controller permits limiting the use of RDMA/IB-spe‐
cific resources per cgroup.
Further information can be found in the kernel source file
Documentation/cgroup-v1/rdma.txt.
Exemple: limiter l'utilisation du processeur
Les opérations de Cgroup sont effectuées via un système de fichiers appelé cgroupfs. Fondamentalement, lorsque Linux démarre, cgroupfs est automatiquement monté.
$ mount | grep cgroup
cgroup on /sys/fs/cgroup/unified type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/pids type cgroup (rw,nosuid,nodev,noexec,relatime,pids)
cgroup on /sys/fs/cgroup/perf_event type cgroup (rw,nosuid,nodev,noexec,relatime,perf_event)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
cgroup on /sys/fs/cgroup/rdma type cgroup (rw,nosuid,nodev,noexec,relatime,rdma)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
À partir de là, vous pouvez utiliser cgroup pour limiter l'utilisation du processeur de votre application. Toutes les opérations sont effectuées avec ubuntu 18.04.
- Commencez par créer un simple programme c en boucle infinie.
loop_sample_cpu.c
#include <stdio.h>
int main(){
while(1){
}
}
Compilez le programme.
$ gcc -o loop_sample_cpu loop_sample_cpu.c
Je le ferai.
$./loop_sample_cpu
Vérifiez le taux d'utilisation du processeur. Le taux d'utilisation de loop_sample_cpu est proche de 100%.
zhenbin@zhenbin-VirtualBox:~$ top
top - 14:51:45 up 28 min, 1 user, load average: 0.29, 0.08, 0.02
Tasks: 175 total, 2 running, 140 sleeping, 0 stopped, 0 zombie
%Cpu(s): 98.6 us, 1.4 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8345424 total, 6421164 free, 875200 used, 1049060 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 7187568 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10403 zhenbin 20 0 4372 764 700 R 95.0 0.0 0:19.75 loop_sample_cpu
9547 zhenbin 20 0 3020252 278368 108992 S 2.3 3.3 0:09.34 gnome-shell
10342 zhenbin 20 0 870964 38352 28464 S 1.0 0.5 0:00.88 gnome-termi+
9354 zhenbin 20 0 428804 95048 61820 S 0.7 1.1 0:02.25 Xorg
922 root 20 0 757084 82776 45764 S 0.3 1.0 0:00.50 dockerd
1 root 20 0 159764 8972 6692 S 0.0 0.1 0:01.06 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0+
7 root 20 0 0 0 0 I 0.0 0.0 0:00.15 kworker/u2:+
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 0:00.13 ksoftirqd/0
10 root 20 0 0 0 0 I 0.0 0.0 0:00.16 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
12 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject+
13 root 20 0 0 0 0 I 0.0 0.0 0:00.11 kworker/0:1+
- Ajouter une limite de processeur au groupe de contrôle Créez un dossier sous / sys / fs / cgroup / cpu, cpuacct.
$ cd /sys/fs/cgroup/cpu,cpuacct
$ mkdir loop_sample_cpu
$ cd loop_sample_cpu
Ajoutez le PID de loop_sample_cpu à cgroup. Ici, seul l'utilisateur root est terminé.
$ sudo su
$ echo 10403 > cgroup.procs
Ajoutez une limite de CPU. Il existe des types de restriction de ressources dans le dossier loop_sample_cpu, mais cette fois, nous opérons sur ces deux. Veuillez consulter [7] pour la signification des autres éléments.
-
cpu.cfs_period_us Spécifie l'intervalle, en microsecondes (µs, mais ici indiqué par "nous"), pour réallouer l'accès aux ressources CPU par groupe de contrôle. Si les tâches du groupe de contrôle ont besoin d'accéder à un seul processeur pendant 0,2 seconde par seconde, définissez cpu.cfs_quota_us sur 200000 et cpu.cfs_period_us sur 1000000. La limite supérieure du paramètre cpu.cfs_quota_us est de 1 seconde et la limite inférieure est de 1 000 microsecondes.
-
cpu.cfs_quota_us Spécifie la durée totale, en microsecondes (µs, mais ici indiquée par «nous»), pendant laquelle toutes les tâches d'un groupe de contrôle s'exécuteront sur une période de temps (définie dans cpu.cfs_period_us). Si toutes les tâches du groupe de contrôle utilisent le temps spécifié par le quota, la tâche sera limitée pour le temps restant spécifié par cette période et ne sera pas autorisée à s'exécuter avant la période suivante. Définissez cpu.cfs_quota_us sur 200000 et cpu.cfs_period_us sur 1000000 si les tâches du groupe de contrôle ont besoin d'accéder à un seul processeur pendant 0,2 seconde par seconde. Notez que les paramètres de quota et de période fonctionnent sur une base CPU. Pour permettre au processus d'utiliser pleinement les deux processeurs, par exemple, définissez cpu.cfs_quota_us sur 200000 et cpu.cfs_period_us sur 100000. La définition de la valeur de cpu.cfs_quota_us sur -1 indique que le groupe de contrôle n'est pas conforme à la limite de temps CPU. C'est également la valeur par défaut pour tous les groupes de contrôle (sauf le groupe de contrôle racine).
Limitez le processeur à 20% par cœur. (Seulement 10 ms de temps CPU sont disponibles toutes les 50 ms)
$ echo 10000 > cpu.cfs_quota_us
$ echo 50000 > cpu.cfs_period_us
L'utilisation du processeur de loop_sample_cpu est limitée à 20%.
zhenbin@zhenbin-VirtualBox:~$ top
top - 15:06:05 up 42 min, 1 user, load average: 0.40, 0.72, 0.57
Tasks: 181 total, 2 running, 146 sleeping, 0 stopped, 0 zombie
%Cpu(s): 23.8 us, 1.0 sy, 0.0 ni, 75.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8345424 total, 6366748 free, 912068 used, 1066608 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 7134248 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10403 zhenbin 20 0 4372 764 700 R 19.9 0.0 12:16.90 loop_sample_cpu
9547 zhenbin 20 0 3032212 287524 111556 S 1.7 3.4 0:18.14 gnome-shell
9354 zhenbin 20 0 458868 125556 77832 S 1.3 1.5 0:06.06 Xorg
10342 zhenbin 20 0 873156 40500 28464 S 1.0 0.5 0:03.34 gnome-termi+
9998 zhenbin 20 0 1082256 120516 36164 S 0.3 1.4 0:01.92 gnome-softw+
1 root 20 0 159764 8972 6692 S 0.0 0.1 0:01.12 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0+
7 root 20 0 0 0 0 I 0.0 0.0 0:00.24 kworker/u2:+
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 0:00.16 ksoftirqd/0
10 root 20 0 0 0 0 I 0.0 0.0 0:00.22 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
12 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject+
14 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0
Namespace Namespace [8] est une ressource système globale recouverte d'une couche d'abstraction dans l'espace de noms. C'est un mécanisme qui fait apparaître le processus comme s'il disposait de ses propres ressources mondiales distinctes. Les modifications apportées aux ressources globales sont visibles par les autres processus membres de l'espace de noms, mais pas par les autres processus. Une utilisation des espaces de noms consiste à implémenter des conteneurs.
Exemple: espace de noms réseau
Il est possible de créer deux réseaux virtuels sur une carte réseau à l'aide de l'espace de noms réseau.
- Créez un espace de noms réseau
zhenbin@zhenbin-VirtualBox:~$ sudo unshare --uts --net /bin/bash
root@zhenbin-VirtualBox:~# hostname container001
root@zhenbin-VirtualBox:~# exec bash
root@container001:~# ip link set lo up
root@container001:~# ifconfig
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
root@container001:~# echo $$ # $$Est le PID de la commande elle-même(ID de processus)Variable à définir
1909
- Créez un lien d'interface réseau virtuelle. Veuillez vous référer à [9] pour l'explication de l'interface réseau virtuelle. Lancez un nouveau shell. Créez une paire de liens.
$ sudo ip link add veth0 type veth peer name veth1
Attribuez veth1 à l'espace de noms réseau que vous venez de créer.
$ sudo ip link set veth1 netns 1909
Configurer veth0
$ sudo ip address add dev veth0 192.168.100.1/24
$ sudo ip link set veth0 up
Configurez veth1 avec la coque du container001.
$ sudo ip address add dev veth1 192.168.100.2/24
$ sudo ip link set veth1 up
Vous pouvez maintenant communiquer entre l'hôte et le container001.
zhenbin@zhenbin-VirtualBox:~$ ping 192.168.100.2
PING 192.168.100.2 (192.168.100.2) 56(84) bytes of data.
64 bytes from 192.168.100.2: icmp_seq=1 ttl=64 time=0.019 ms
64 bytes from 192.168.100.2: icmp_seq=2 ttl=64 time=0.037 ms
^C
--- 192.168.100.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.019/0.028/0.037/0.009 ms
Présentation de Docker pour utiliser pleinement LXC
Les premières versions de Docker utilisaient LXC comme pilote d'exécution de conteneur, mais il est devenu une option dans Docker v0.9 et n'est plus pris en charge dans Docker v1.10. Ensuite, Docker utilise une bibliothèque appelée libcontainer développée par Docker pour contrôler le groupe de contrôle et l'espace de noms.
Voici un point important. Docker n'est pas une technologie de virtualisation! Si quoi que ce soit, il existe en tant qu'outil de gestion pour les groupes de contrôle et les espaces de noms. C'est un outil qui permet aux développeurs et aux opérateurs de serveur d'utiliser plus facilement les fonctions de virtualisation fournies par le noyau Linux. De plus, la présence de Dockerfile et Docker Hub a amélioré l'encapsulation et la portabilité des applications!
Ici, je voudrais souligner les caractéristiques de l'isolation des ressources docker et du contrôle sur les commandes docker générales.
Exemple: Limitez l'utilisation du processeur du conteneur avec docker.
- Créez un conteneur Docker contenant votre application.
Créez une image docker basée sur ubuntu qui inclut le programme loop_sample_cpu.c créé précédemment.
FROM ubuntu
RUN apt update && apt install -y gcc
WORKDIR /src
COPY loop_sample_cpu.c .
RUN gcc -o loop_sample_cpu loop_sample_cpu.c
CMD ./loop_sample_cpu
Créez l'image docker.
docker build -t ubuntu_cpu .
- Démarrez un conteneur sans aucune restriction de processeur.
docker run -d ubuntu_cpu
Regardons le taux d'utilisation du processeur.
zhenbin@zhenbin-VirtualBox:~/workspace/presentation$ top
top - 17:06:45 up 43 min, 1 user, load average: 0.89, 0.56, 0.37
Tasks: 178 total, 2 running, 142 sleeping, 0 stopped, 0 zombie
%Cpu(s): 99.0 us, 1.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8345424 total, 6156972 free, 894060 used, 1294392 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 7184360 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8853 root 20 0 4372 804 740 R 94.0 0.0 0:15.97 loop_sample_cpu
1253 zhenbin 20 0 3020528 278012 108704 S 2.0 3.3 0:31.41 gnome-shell
1056 zhenbin 20 0 424560 90824 55364 S 1.3 1.1 0:09.92 Xorg
1927 zhenbin 20 0 877384 44356 28584 S 1.3 0.5 0:08.01 gnome-terminal-
1 root 20 0 225292 9040 6724 S 0.0 0.1 0:01.62 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H-kb
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 0:00.29 ksoftirqd/0
10 root 20 0 0 0 0 I 0.0 0.0 0:00.31 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
12 root -51 0 0 0 0 S 0.0 0.0 0:00.00 idle_inject/0
14 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0
15 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
16 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 netns
- Démarrez un conteneur qui limite la CPU.
docker run -d --cpu-period=50000 --cpu-quota=10000 ubuntu_cpu
Vérifions l'utilisation du processeur.
zhenbin@zhenbin-VirtualBox:~$ top
top - 17:08:50 up 45 min, 1 user, load average: 0.77, 0.68, 0.45
Tasks: 178 total, 2 running, 141 sleeping, 0 stopped, 0 zombie
%Cpu(s): 25.8 us, 2.3 sy, 0.0 ni, 71.9 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 8345424 total, 6160808 free, 892384 used, 1292232 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 7188556 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
9066 root 20 0 4372 800 740 R 19.9 0.0 0:04.36 loop_sample+
1253 zhenbin 20 0 3017968 275536 106144 S 3.0 3.3 0:32.83 gnome-shell
1056 zhenbin 20 0 422000 88336 52876 S 2.7 1.1 0:10.59 Xorg
1927 zhenbin 20 0 877380 44468 28584 S 2.0 0.5 0:08.54 gnome-termi+
580 root 20 0 776548 46696 24888 S 0.3 0.6 0:02.71 containerd
1202 zhenbin 20 0 193504 2912 2536 S 0.3 0.0 0:03.92 VBoxClient
1461 zhenbin 20 0 441756 22836 17820 S 0.3 0.3 0:00.09 gsd-wacom
1475 zhenbin 20 0 670048 23676 18316 S 0.3 0.3 0:00.29 gsd-color
1 root 20 0 225292 9040 6724 S 0.0 0.1 0:01.65 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0+
8 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq
9 root 20 0 0 0 0 S 0.0 0.0 0:00.30 ksoftirqd/0
10 root 20 0 0 0 0 I 0.0 0.0 0:00.32 rcu_sched
11 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
Lorsque j'ai vérifié / sys / fs / cgroup / cpu, cpuacct, j'ai trouvé qu'un dossier appelé docker avait été créé.
zhenbin@zhenbin-VirtualBox:/sys/fs/cgroup/cpu,cpuacct$ ls
cgroup.clone_children cpuacct.usage cpuacct.usage_percpu_user cpu.cfs_quota_us notify_on_release user.slice
cgroup.procs cpuacct.usage_all cpuacct.usage_sys cpu.shares release_agent
cgroup.sane_behavior cpuacct.usage_percpu cpuacct.usage_user cpu.stat system.slice
cpuacct.stat cpuacct.usage_percpu_sys cpu.cfs_period_us docker tasks
Nous savons maintenant que l'application limite les ressources d'exécution en utilisant le groupe de contrôle et l'espace de noms dans docker.
Caractéristiques de Docker
――Comme expliqué ci-dessus, docker est juste un outil de gestion, c'est-à-dire qu'il s'agit d'un processus de système d'exploitation. Par conséquent, il démarre plus rapidement que la machine virtuelle.
- Bonne portabilité. Puisque le Dockerfile décrit l'environnement (bibliothèque, paramètres) que l'application exécute, la même application peut être reproduite n'importe où.
- Pour exécuter un processus dans un conteneur. Fondamentalement, il n'est pas recommandé que le conteneur Docker exécute plusieurs processus. Après tout, l'exécution de plusieurs processus rend impossible la séparation des ressources, ce qui revient à exécuter une application sur l'hôte dans le même environnement.
- Impossible de changer le noyau ou le matériel. Les conteneurs exécutés sur l'hôte partagent le noyau de l'hôte, donc toute modification apportée au module du noyau affectera tous les conteneurs. En outre, il existe de nombreuses restrictions sur le matériel. Par exemple, des opérations telles que l'usb sont assez problématiques.
- Puisque le système de fichiers à l'intérieur du conteneur Docker est enregistré dans la mémoire, lorsque le conteneur est supprimé, les données sont également supprimées, donc si vous souhaitez rendre les données persistantes, vous devez monter le système de fichiers hôte sur le conteneur. Cependant, il est généralement recommandé que l'application exécutée sur le docker soit sans état.
URL de référence
[1] https://blogs.itmedia.co.jp/itsolutionjuku/2017/10/1it_1.html [2] https://ja.wikipedia.org/wiki/%E3%83%8F%E3%82%A4%E3%83%91%E3%83%BC%E3%83%90%E3%82%A4%E3%82%B6 [3] https://codezine.jp/article/detail/11336 [4] https://ja.wikipedia.org/wiki/LXC [5] https://ja.wikipedia.org/wiki/Cgroups [6] http://man7.org/linux/man-pages/man7/cgroups.7.html [7] https://access.redhat.com/documentation/ja-jp/red_hat_enterprise_linux/6/html/resource_management_guide/sec-cpu [8] https://linuxjm.osdn.jp/html/LDP_man-pages/man7/namespaces.7.html [9] https://gihyo.jp/admin/serial/01/linux_containers/0006
Recommended Posts