Compléter les valeurs manquantes titanesques de Kaggle et créer des fonctionnalités
introduction
La dernière fois, j'ai regardé les données de train du Titanic pour voir quelles fonctionnalités sont liées au taux de survie. Dernière fois: Analyse des données avant la génération de fonctionnalités titanesques de Kaggle (J'espère que vous pouvez également lire cet article)
Sur la base du résultat, cette fois **, nous allons créer une base de données pour compléter les valeurs manquantes et ajouter les fonctionnalités nécessaires au modèle de prédiction **.
Cette fois-ci, comme modèle de prédiction, nous utiliserons "** GBDT (gradient boosting tree) xg boost **", qui est souvent utilisé dans les compétitions kaggle, donc nous rendrons les données adaptées.
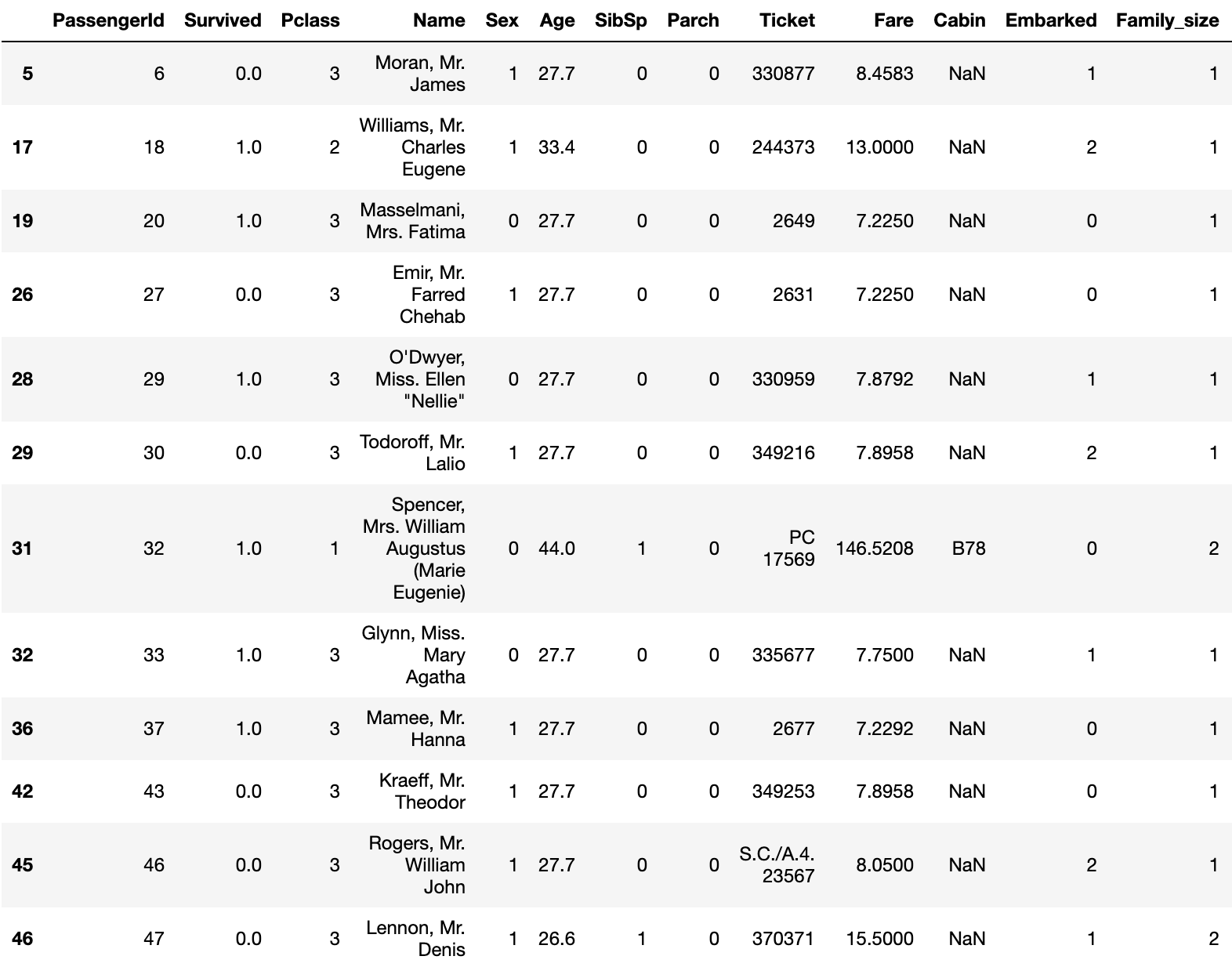
1. Acquisition des données et confirmation des valeurs manquantes
import pandas as pd
import numpy as np
train = pd.read_csv('/kaggle/input/titanic/train.csv')
test = pd.read_csv('/kaggle/input/titanic/test.csv')
#Combinez les données de train et les données de test en un seul
data = pd.concat([train,test]).reset_index(drop=True)
#Vérifiez le nombre de lignes contenant des valeurs manquantes
train.isnull().sum()
test.isnull().sum()
Le numéro de chaque valeur manquante est le suivant.
| données de train | données de test | |
|---|---|---|
| PassengerId | 0 | 0 |
| Survived | 0 | |
| Pclass | 0 | 0 |
| Name | 0 | 0 |
| Sex | 0 | 0 |
| Age | 177 | 86 |
| SibSp | 0 | 0 |
| Parch | 0 | 0 |
| Ticket | 0 | 0 |
| Fare | 0 | 1 |
| Cabin | 687 | 327 |
| Embarked | 2 | 0 |
2. Complément de l'embarquement et du tarif
Tout d'abord, en regardant les deux lignes où Embarked est manquant, ** Pclass est 1 ** et ** Fare est 80 **.
 Parmi ceux qui ont une
Parmi ceux qui ont une classe P de 1 '' et un tarif de 70 à 90 '', ** Embarqué a la plus forte proportion de S **, donc ces deux sont complétés par S.
data['Embarked'] = data['Embarked'].fillna('S')
Ensuite, en ce qui concerne Fare, la classe ** P de la ligne manquante était 3 ** et ** Embarqué était S **.
 Par conséquent, il est complété par la valeur médiane parmi ceux qui remplissent ces deux conditions.
Par conséquent, il est complété par la valeur médiane parmi ceux qui remplissent ces deux conditions.
data['Fare'] = data['Fare'].fillna(data.query('Pclass==3 & Embarked=="S"')['Fare'].median())
En ce qui concerne la valeur manquante de Age, je voudrais ** prédire l'âge en utilisant une forêt aléatoire ** après avoir créé d'autres quantités de caractéristiques, donc je la décrirai plus tard.
3. Classification des caractéristiques
** Family_size, Fare, Cabin, Ticket ** qui combinent Sibsp et Parch seront ** classés en fonction de la différence de taux de survie **. Pour connaître la différence de taux de survie pour chaque fonctionnalité, consultez l'article Précédent.
** Classification de la quantité d'entités 'Taille_famille' représentant le nombre de membres de la famille **
data['Family_size'] = data['SibSp']+data['Parch']+1
data['Family_size_bin'] = 0
data.loc[(data['Family_size']>=2) & (data['Family_size']<=4),'Family_size_bin'] = 1
data.loc[(data['Family_size']>=5) & (data['Family_size']<=7),'Family_size_bin'] = 2
data.loc[(data['Family_size']>=8),'Family_size_bin'] = 3
** Classification tarifaire **
data['Fare_bin'] = 0
data.loc[(data['Fare']>=10) & (data['Fare']<50), 'Fare_bin'] = 1
data.loc[(data['Fare']>=50) & (data['Fare']<100), 'Fare_bin'] = 2
data.loc[(data['Fare']>=100), 'Fare_bin'] = 3
** Classification des cabines **
#Quantité d'entités représentant le premier alphabet'Cabin_label'Créer(Valeur manquante'n')
data['Cabin_label'] = data['Cabin'].map(lambda x:str(x)[0])
data['Cabin_label_bin'] = 0
data.loc[(data['Cabin_label']=='A')|(data['Cabin_label']=='G'), 'Cabin_label_bin'] = 1
data.loc[(data['Cabin_label']=='C')|(data['Cabin_label']=='F'), 'Cabin_label_bin'] = 2
data.loc[(data['Cabin_label']=='T'), 'Cabin_label_bin'] = 3
data.loc[(data['Cabin_label']=='n'), 'Cabin_label_bin'] = 4
** Classification par le nombre de numéros de billets en double 'Ticket_count' **
data['Ticket_count'] = data.groupby('Ticket')['PassengerId'].transform('count')
data['Ticket_count_bin'] = 0
data.loc[(data['Ticket_count']>=2) & (data['Ticket_count']<=4), 'Ticket_count_bin'] = 1
data.loc[(data['Ticket_count']>=5), 'Ticket_count_bin'] = 2
** Classification par type de numéro de billet **
#Divisez en billets avec des chiffres uniquement et des billets avec des chiffres et des alphabets
#Obtenez un billet à numéro uniquement
num_ticket = data[data['Ticket'].str.match('[0-9]+')].copy()
num_ticket_index = num_ticket.index.values.tolist()
#Billets avec uniquement des numéros supprimés des données d'origine et le reste contient des alphabets
num_alpha_ticket = data.drop(num_ticket_index).copy()
#Classification des billets avec numéros seulement
#Le numéro du ticket étant une chaîne de caractères, il est converti en valeur numérique
num_ticket['Ticket'] = num_ticket['Ticket'].apply(lambda x:int(x))
num_ticket['Ticket_bin'] = 0
num_ticket.loc[(num_ticket['Ticket']>=100000) & (num_ticket['Ticket']<200000),
'Ticket_bin'] = 1
num_ticket.loc[(num_ticket['Ticket']>=200000) & (num_ticket['Ticket']<300000),
'Ticket_bin'] = 2
num_ticket.loc[(num_ticket['Ticket']>=300000),'Ticket_bin'] = 3
#Classification des billets avec numéros et alphabets
num_alpha_ticket['Ticket_bin'] = 4
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('A.+'),'Ticket_bin'] = 5
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C.+'),'Ticket_bin'] = 6
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C\.*A\.*.+'),'Ticket_bin'] = 7
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('F\.C.+'),'Ticket_bin'] = 8
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('PC.+'),'Ticket_bin'] = 9
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('S\.+.+'),'Ticket_bin'] = 10
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SC.+'),'Ticket_bin'] = 11
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SOTON.+'),'Ticket_bin'] = 12
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('STON.+'),'Ticket_bin'] = 13
num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('W\.*/C.+'),'Ticket_bin'] = 14
data = pd.concat([num_ticket,num_alpha_ticket]).sort_values('PassengerId')
4. Complément d'âge
Pour la valeur manquante de Age, il existe une méthode de ** médiane ** ou ** de trouver et de compléter l'âge moyen pour chaque titre du nom **, mais quand je l'ai recherché, il manquait ** en utilisant une forêt aléatoire. Il y avait une méthode ** pour prédire l'âge de la pièce où elle se trouve, donc cette fois je vais l'utiliser.
from sklearn.preprocessing import LabelEncoder
from sklearn.ensemble import RandomForestRegressor
#Étiqueter numériquement les caractéristiques non numériques
#Étiqueter également les fonctionnalités qui ne sont pas utilisées pour prédire l'âge
le = LabelEncoder()
data['Sex'] = le.fit_transform(data['Sex'])
data['Embarked'] = le.fit_transform(data['Embarked'])
data['Cabin_label'] = le.fit_transform(data['Cabin_label'])
#La quantité de fonction utilisée pour prédire l'âge'age_data'Mettre en
age_data = data[['Age','Pclass','Family_size',
'Fare_bin','Cabin_label','Ticket_count']].copy()
#Diviser en lignes manquantes et non manquantes
known_age = age_data[age_data['Age'].notnull()].values
unknown_age = age_data[age_data['Age'].isnull()].values
x = known_age[:, 1:]
y = known_age[:, 0]
#Apprenez dans une forêt aléatoire
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(x, y)
#Prédire la valeur et l'affecter à la ligne manquante
age_predict = rfr.predict(unknown_age[:, 1:])
data.loc[(data['Age'].isnull()), 'Age'] = np.round(age_predict,1)
Vous avez maintenant complété la valeur manquante pour Age.
 Et l'âge sera également classé.
Et l'âge sera également classé.
data['Age_bin'] = 0
data.loc[(data['Age']>10) & (data['Age']<=30),'Age_bin'] = 1
data.loc[(data['Age']>30) & (data['Age']<=50),'Age_bin'] = 2
data.loc[(data['Age']>50) & (data['Age']<=70),'Age_bin'] = 3
data.loc[(data['Age']>70),'Age_bin'] = 4
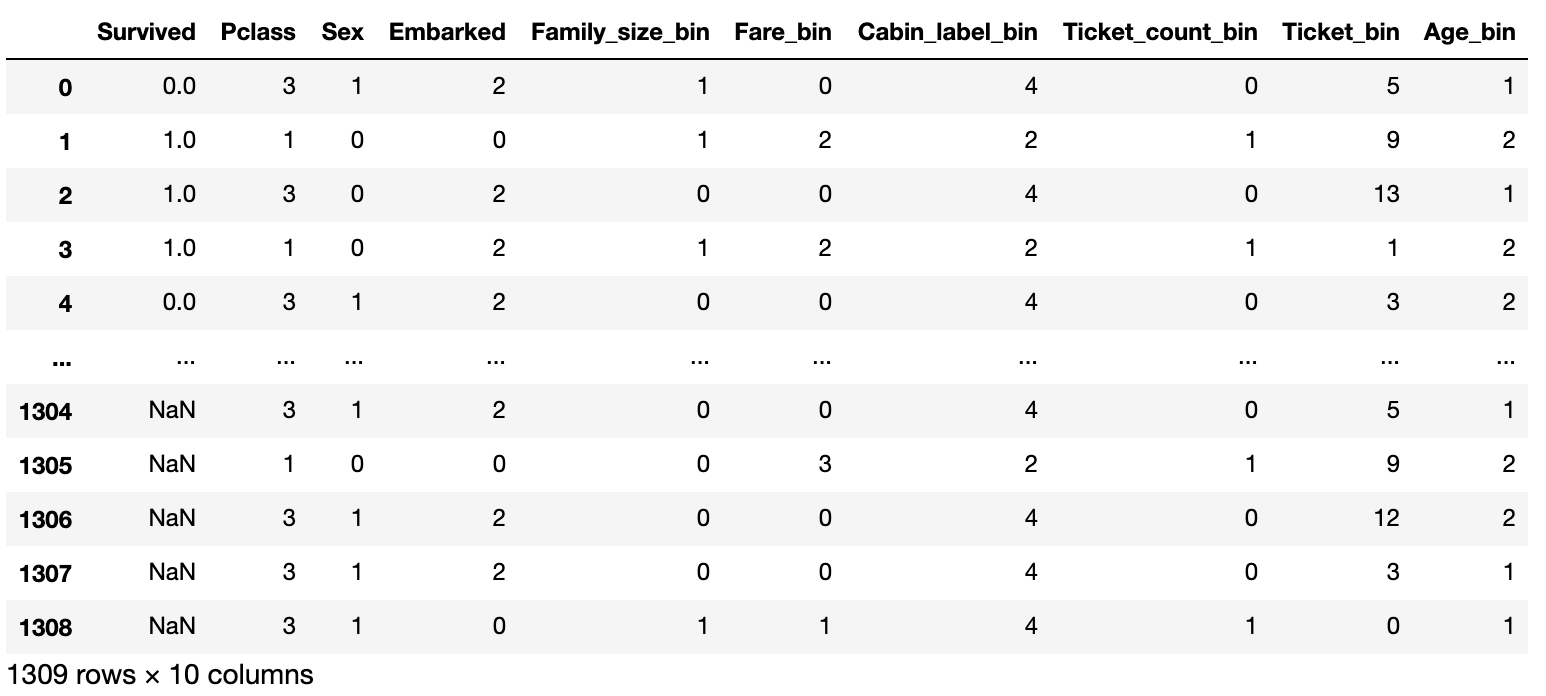
Enfin, supprimez le montant de fonction inutile et la création du montant de fonction est terminée.
#Supprimez les fonctionnalités inutiles.
data = data.drop(['PassengerId','Name','Age','Fare','SibSp','Parch','Ticket','Cabin',
'Family_size','Cabin_label','Ticket_count'], axis=1)
En fin de compte, la trame de données ressemble à ceci.
5. Prédiction avec xg boost
Commencez par diviser les données en données de train et en données de test à nouveau, et divisez-les en «X» uniquement pour les quantités de caractéristiques et «Y» pour «survécu» uniquement.
#Divisez en données de train et testez à nouveau les données
model_train = data[:891]
model_test = data[891:]
X = model_train.drop('Survived', axis=1)
Y = pd.DataFrame(model_train['Survived'])
x_test = model_test.drop('Survived', axis=1)
Regardons les performances du modèle en recherchant deux, ** logloss ** et ** exactitude **.
from sklearn.metrics import log_loss
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold
import xgboost as xgb
#Définir les paramètres
params = {'objective':'binary:logistic',
'max_depth':5,
'eta': 0.1,
'min_child_weight':1.0,
'gamma':0.0,
'colsample_bytree':0.8,
'subsample':0.8}
num_round = 1000
logloss = []
accuracy = []
kf = KFold(n_splits=4, shuffle=True, random_state=0)
for train_index, valid_index in kf.split(X):
x_train, x_valid = X.iloc[train_index], X.iloc[valid_index]
y_train, y_valid = Y.iloc[train_index], Y.iloc[valid_index]
#Convertir le bloc de données en une forme adaptée à l'augmentation de xg
dtrain = xgb.DMatrix(x_train, label=y_train)
dvalid = xgb.DMatrix(x_valid, label=y_valid)
dtest = xgb.DMatrix(x_test)
#Apprenez avec xgboost
model = xgb.train(params, dtrain, num_round,evals=[(dtrain,'train'),(dvalid,'eval')],
early_stopping_rounds=50)
valid_pred_proba = model.predict(dvalid)
#Demander la perte de journal
score = log_loss(y_valid, valid_pred_proba)
logloss.append(score)
#Trouvez la précision
#valid_pred_Puisque proba est une valeur de probabilité, elle est convertie en 0 et 1.
valid_pred = np.where(valid_pred_proba >0.5,1,0)
acc = accuracy_score(y_valid, valid_pred)
accuracy.append(acc)
print(f'log_loss:{np.mean(logloss)}')
print(f'accuracy:{np.mean(accuracy)}')
Avec ce code log_loss : 0.4234131996311837 accuracy : 0.8114369975356523 Le résultat était que.
Maintenant que le modèle est terminé, nous allons créer les données de prévision à soumettre à kaggle.
y_pred_proba = model.predict(dtest)
y_pred= np.where(y_pred_proba > 0.5,1,0)
submission = pd.DataFrame({'PassengerId':test['PassengerId'], 'Survived':y_pred})
submission.to_csv('titanic_xgboost.csv', index=False)
Le résultat ressemble à ceci.
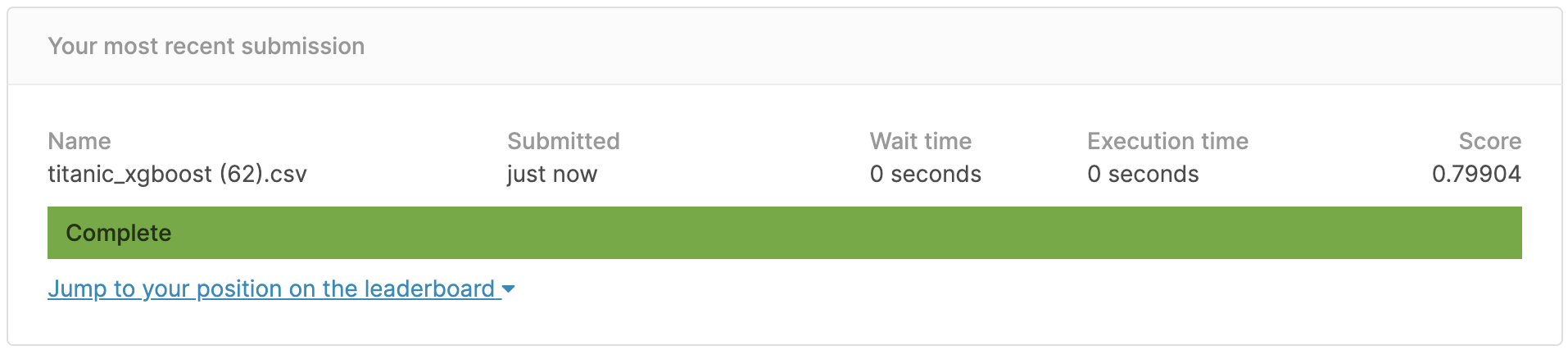 Le taux de réponse correcte était de ** 79,9% **, qui n'atteignait pas 80%, mais il semble qu'il puisse atteindre 80% en ajustant les paramètres du modèle.
Le taux de réponse correcte était de ** 79,9% **, qui n'atteignait pas 80%, mais il semble qu'il puisse atteindre 80% en ajustant les paramètres du modèle.
Résumé
Cette fois, j'ai essayé de soumettre la valeur prévue à kaggle.
Les données de la cabine que je pensais ne pas pouvoir être utilisées comme fonctionnalité car il y avait de nombreuses valeurs manquantes, mais lorsque j'ai essayé d'étiqueter chaque valeur manquante, le taux de précision de la valeur prédite a augmenté **, et la quantité de fonctionnalité peut être utilisée si les données sont correctement traitées. J'ai découvert que. De plus, si vous effectuez des prédictions sans classifier des fonctionnalités telles que le tarif et l'âge, ** les valeurs de perte de log et de précision s'amélioreront **, mais ** le taux de précision des valeurs prévues ne s'améliorera pas **. J'ai senti qu'il serait possible de créer un modèle approprié sans surapprentissage en classant en fonction de la différence de taux de survie plutôt que d'utiliser le montant de la fonctionnalité tel quel.
Si vous avez des opinions ou des suggestions, nous vous serions reconnaissants de bien vouloir faire un commentaire ou une demande de modification.
Sites et livres auxquels j'ai fait référence
Kaggle Tutorial Titanic's Top 2% Know-how pyhaya’s diary Livre: [La technologie d'analyse de données qui gagne avec Kaggle](https://www.amazon.co.jp/Kaggle%E3%81%A7%E5%8B%9D%E3%81%A4%E3%83%87% E3% 83% BC% E3% 82% BF% E5% 88% 86% E6% 9E% 90% E3% 81% AE% E6% 8A% 80% E8% A1% 93-% E9% 96% 80% E8 % 84% 87-% E5% A4% A7% E8% BC% 94-ebook / dp / B07YTDBC3Z)
Recommended Posts