Un aperçu de DELG, une nouvelle méthode d'extraction de caractéristiques d'image qui attire l'attention avec Kaggle
introduction
Cet article présente DELG, un algorithme d'extraction de caractéristiques d'image qui attire l'attention dans Google Landmark Recognition.
Cet algorithme a été annoncé en janvier 2020, et il semble qu'il n'y ait presque pas de littérature japonaise.
Aperçu
L'extraction de caractéristiques d'image est approximativement divisée en fonction globale qui reflète les informations de l'image entière et fonction locale qui collecte les caractéristiques locales. Jusqu'à présent, différents algorithmes ont été adoptés pour ces deux extractions de caractéristiques. Dans cet article, ils sont combinés en un seul algorithme, et le but est d'extraire efficacement les caractéristiques. Plus précisément, cela est réalisé en utilisant la couche de mise en commun moyenne pour l'entité globale et la sélection attentive pour l'entité locale. Il introduit également la réduction de dimension des caractéristiques locales basée sur l'encodeur automatique.
En conséquence, ce modèle a atteint des performances de pointe dans un certain nombre d'ensembles de données (y compris l'ensemble de données Landmark publié par Google).
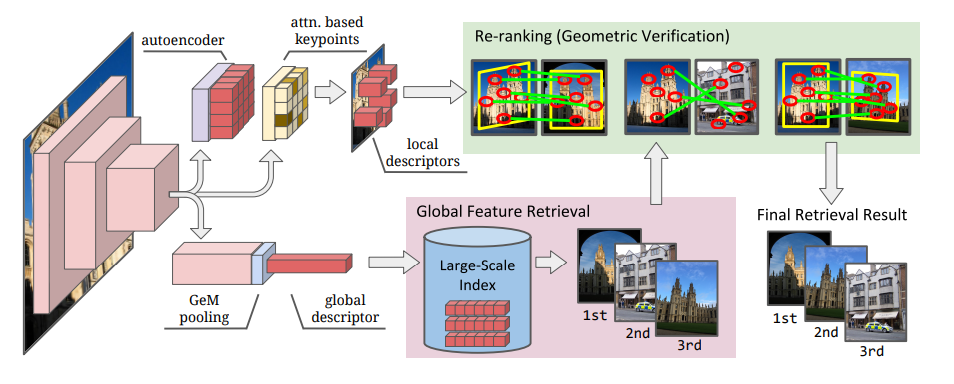
Qu'est-ce que la fonctionnalité globale / la fonctionnalité locale?
La caractéristique globale est une quantité de caractéristiques extraite de l'image entière. Une entité locale est une collection d'entités extraites d'une partie d'une image.
| Global feature (global descriptor, embedding) |
Local feature | |
|---|---|---|
| Gamme de cible d'extraction | -L'ensemble | -local |
| dimension | - 画像につき1dimension | - 画像につき複数dimensionになりうる |
| Procédure d'extraction | -Calculez le tout à la fois | 1.Sélectionnez le local à extraire(detector) 2.Extraire la quantité de fonction(descriptor) |
| Fonctionnalité | -Calcul léger car c'est une étape -Étant donné que la sortie est unidimensionnelle par image, la quantité de données peut être supprimée -Excellent rappel |
-Relativement robuste même si une partie de l'image est masquée -Excellente précision |
| Méthode typique | -Histogramme des couleurs - GeM pooling - ArcFace loss |
- SIFT - SURF - RANSAC - DELF |
référence
- Combining Local and Global Image Features for Object Class Recognition
- Image à grande échelle basée sur le hachage des caractéristiques locales
Vous pouvez voir que les forces et les faiblesses de la fonctionnalité globale et de la fonctionnalité locale sont différentes. Des algorithmes de sélection d'images similaires (Retrival) ont généralement une position en deux étapes dans laquelle la sélection est effectuée par la fonction globale, puis le classement est corrigé par la caractéristique locale (vérification géométrique).
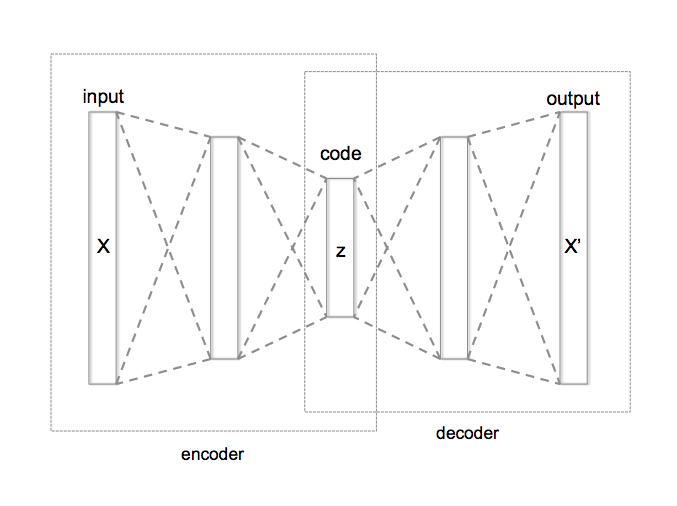
Qu'est-ce que Autoencoder
Il s'agit d'une méthode de réduction de dimension utilisant un réseau neuronal, et la dimension est réduite en prenant en sandwich une couche intermédiaire avec un plus petit nombre de nœuds que la couche d'entrée.
Étant donné que les entités locales ont généralement une grande dimension (100 à 1 000), il est habituel d'effectuer une réduction de dimension telle que l'ACP séparément. Cependant, dans cet article, nous visons à réduire les dimensions d'une manière unique, nous utilisons donc l'Autoencoder qui peut être incorporé dans le réseau neuronal pour réduire les dimensions.
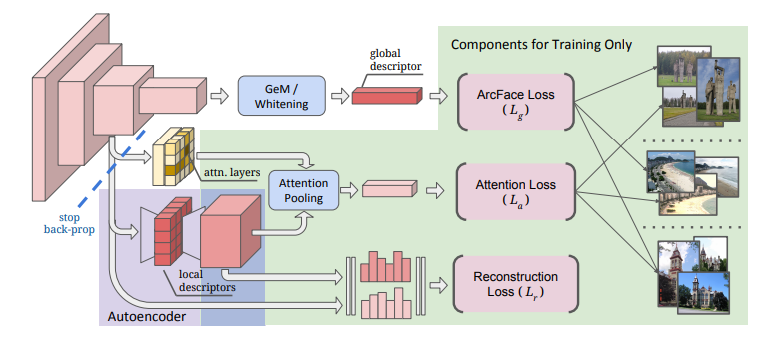
Modèle proposé
Les caractéristiques du modèle proposé sont les suivantes.
- Basé sur ResNet
- Global feature extraction
- Sortie ajustée par moyenne moyenne généralisée (GeM) et blanchiment de la couche entièrement connectée --Apprendre avec la perte d'ArcFace
- Local feature
- L'algorithme qui discrimine les zones locales caractéristiques est important. Adoptez le module Attention
- Réduction de la dimension avec auto-encodeur --Apprentissage avec perte d'attention et perte de reconstruction
la mise en oeuvre
Extrayez la fonctionnalité globale et la fonctionnalité locale de l'image suivante.

Global feature
import tensorflow as tf
#Charger le modèle DELG entraîné
SAVED_MODEL_DIR = '../input/delg-saved-models/local_and_global'
DELG_MODEL = tf.saved_model.load(SAVED_MODEL_DIR)
#Réglez les paramètres
##Dimension de la fonctionnalité globale à extraire
NUM_EMBEDDING_DIMENSIONS = 2048
##Réglez la résolution de l'image(Image Pyramids)
DELG_IMAGE_SCALES_TENSOR = tf.convert_to_tensor([0.70710677, 1.0, 1.4142135])
##Découpez uniquement la partie du modèle DELG utilisée pour l'extraction d'entités globales
DELG_INPUT_TENSOR_NAMES = ['input_image:0', 'input_scales:0']
GLOBAL_FEATURE_EXTRACTION_FN = DELG_MODEL.prune(DELG_INPUT_TENSOR_NAMES,
['global_descriptors:0'])
#Lire les données d'image en tant que tenseur à partir du chemin de l'image
# image_Veuillez définir le chemin de manière appropriée
image_tensor = load_image_tensor(image_path)
#Extraire la fonctionnalité globale avec DELF
embedding_tensor_1 = GLOBAL_FEATURE_EXTRACTION_FN(image_tensor, DELG_IMAGE_SCALES_TENSOR)[0]
#Standardiser
embedding_tensor_2 = tf.nn.l2_normalize(
embedding_tensor_1,
axis=1,
name='l2_normalization')
#Combinez les résultats de différentes résolutions
embedding_tensor_3 = tf.reduce_sum(
embedding_tensor_2, axis=0, name='sum_pooling')
#Normaliser davantage cela
embedding_res = tf.nn.l2_normalize(
embedding_tensor_3, axis=0, name='final_l2_normalization').numpy()
| opération | Taille | |
|---|---|---|
| image_tensor | données d'image | 450, 800, 3 |
| embedding_tensor_1 | Extraction de caractéristiques globales 2048 dimensions pour 3 résolutions | 3, 2048 |
| embedding_tensor_2 | Standardisation | 3, 2048 |
| embedding_tensor_3 | Total dans le sens de l'écrasement de l'axe de résolution | 2048, |
| embedding_res | Standardisation | 2048, |
Local feature
#Réglez les paramètres
##Nombre maximum d'entités à extraire
LOCAL_FEATURE_NUM_TENSOR = tf.constant(1000)
#Découpez le modèle
LOCAL_FEATURE_EXTRACTION_FN = DELG_MODEL.prune(
DELG_INPUT_TENSOR_NAMES + ['input_max_feature_num:0', 'input_abs_thres:0'],
['boxes:0', 'features:0'])
#Charger l'image avec tenseur
image_tensor = load_image_tensor(image_path)
#Extraction des caractéristiques locales par le DELF
#Sortie de la position et de la valeur du montant de la fonction
features = LOCAL_FEATURE_EXTRACTION_FN(image_tensor, DELG_IMAGE_SCALES_TENSOR,
LOCAL_FEATURE_NUM_TENSOR,
DELG_SCORE_THRESHOLD_TENSOR,
)
#Position de l'image extraite en tant que quantité de caractéristiques
#Ajoutez les 0ème et 2ème colonnes, les 1ère et 3ème colonnes de la sortie et divisez par 2.
keypoints = tf.divide(
tf.add(
tf.gather(features[0], [0, 1], axis=1),
tf.gather(features[0], [2, 3], axis=1)), 2.0).numpy()
#Valeur de la fonctionnalité
#Standardiser
descriptors = tf.nn.l2_normalize(
features[1], axis=1, name='l2_normalization').numpy()
train_keypoints = keypoints
train_descriptors = descriptors
test_keypoints = keypoints_2 #Comparaison
test_descriptors = descriptors_2 #Comparaison
#Convertissez les descripteurs en une structure arborescente et obtenez des points proches les uns des autres.
#Référence: https://myenigma.hatenablog.com/entry/2020/06/14/205753#kdtree%E3%81%A8%E3%81%AF
train_descriptor_tree = spatial.cKDTree(train_descriptors)
_, matches = train_descriptor_tree.query(
test_descriptors, distance_upper_bound=max_distance)
test_kp_count = test_keypoints.shape[0]
train_kp_count = train_keypoints.shape[0]
test_matching_keypoints = np.array([
test_keypoints[i,]
for i in range(test_kp_count)
#Le point le plus proche est max_Si la distance est dépassée, l'indice maximum +1 sera renvoyé.
if matches[i] != train_kp_count
])
train_matching_keypoints = np.array([
train_keypoints[matches[i],]
for i in range(test_kp_count)
if matches[i] != train_kp_count
])
Ce qui suit montre le résultat de la recherche des caractéristiques locales des deux images à comparer et de la visualisation des parties correspondantes en fonction des descripteurs correspondants. C'est dommage que les positions ne soient pas exactement correctes, mais vous pouvez voir que les parties caractéristiques sont à peu près associées.
| L'image originale | Augmentation des données |
|---|---|
 |
 |
 |
 |
Domaine de développement
Avec cela, la quantité de caractéristiques locales et sa correspondance ont été provisoirement obtenues, mais dans plus de développement, il y a les problèmes suivants.
- Je souhaite améliorer la précision des points correspondants
- Je veux comprendre la relation spatiale (comprendre à quel point les images ont été prises, etc.)
L'algorithme RANSAC est couramment utilisé pour ces problèmes. De plus, pydegensac est introduit dans kaggle comme un algorithme plus rapide que RANSAC. Les articles suivants sont faciles à comprendre, veuillez donc y jeter un œil.
référence:
- Association de points caractéristiques en calculant la "quantité de mouvement" et la "quantité de déformation" de chaque image
- RANSAC: Pydegensac vs Scikit
À la fin
Voir ci-dessous pour plus de détails.
Recommended Posts