Java pour extraire le contenu de texte PDF
Dans votre travail quotidien, vous devrez peut-être extraire le contenu textuel contenu dans un grand document PDF. Et Free Spire.PDF pour Java fournit un moyen pratique et rapide d'extraire du texte, suivi du code Java utilisé dans le processus.
** Étapes de base: ** ** 1. ** Free Spire.PDF pour Java Téléchargez et décompressez le package. ** 2. ** Importez le package Spire.Pdf.jar du dossier lib dans votre application Java en tant que dépendance, ou installez le package JAR à partir du référentiel Maven (voir ci-dessous le code qui compose le fichier pom.xml). S'il vous plaît). ** 3. ** Dans votre application Java, créez une nouvelle classe Java (nommée ici ExtractText) et entrez et exécutez le code Java correspondant.
** Configurez le fichier pom.xml: **
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf.free</artifactId>
<version>2.6.3</version>
</dependency>
</dependencies>
** Le document source PDF est: **
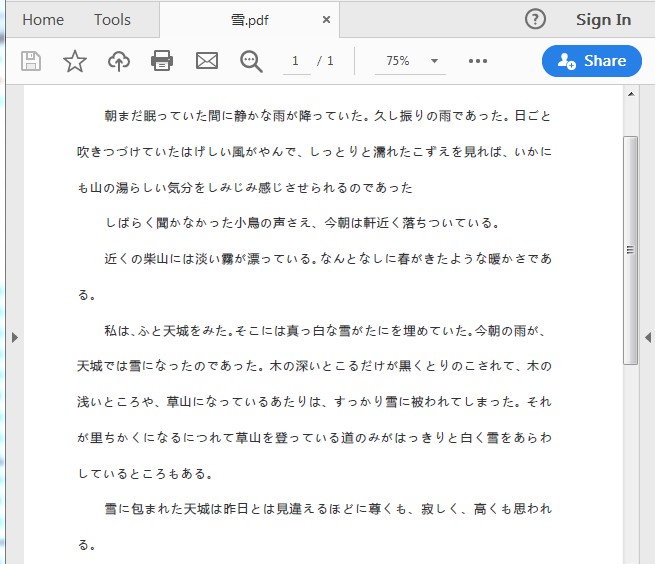
** Code Java: **
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import java.io.*;
public class ExtractText {
public static void main(String[] args) {
//Créer une instance PdfDocument
PdfDocument doc = new PdfDocument();
//Charger le fichier PDF
doc.loadFromFile("neige.pdf");
//Créer une instance StringBuilder
StringBuilder sb = new StringBuilder();
PdfPageBase page;
//Parcourez les pages PDF, récupérez le texte de chaque page et ajoutez-le à l'objet StringBuilder
for(int i= 0;i<doc.getPages().getCount();i++){
page = doc.getPages().get(i);
sb.append(page.extractText(true));
}
FileWriter writer;
try {
//Écrit le texte d'un objet StringBuilder dans un fichier texte
writer = new FileWriter("ExtractText.txt");
writer.write(sb.toString());
writer.flush();
} catch (IOException e) {
e.printStackTrace();
}
doc.close();
}
}
** Extraire les résultats: **
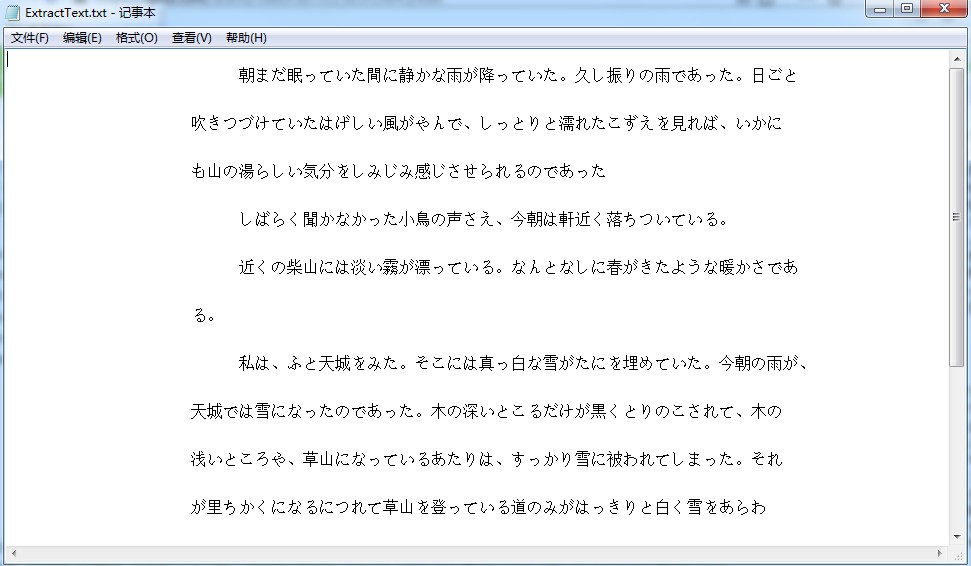
Recommended Posts