Traduit l'explication du modèle supérieur du concours de détection des ondes cérébrales de Kaggle
Il n'y a pas si longtemps, je voulais classer les ondes cérébrales à l'aide de techniques d'apprentissage automatique et d'analyse de données. «Détection EEG de préhension et de levage» qui détecte les mouvements de la main dans la compétition kaggle (https://www.kaggle.com/c/grasp-and-lift-eeg-detection) J'ai donc essayé de le traduire pour étude. La date limite pour ce concours est août 2015, et de «Signal Processing & Classification Pipeline» à «Code» dans le référentiel Github de M. Alexandre Barachant de la meilleure équipe «Cat & Dog» au 25 février 2017. Je voulais traduire la section jusqu'à et l'explication générale du modèle.
Je suis désolé d'avoir peu de connaissances sur mon cerveau et le traitement du signal, et j'ai inséré "(* ~ *)" comme note pour le rendre difficile à lire. Veuillez signaler toute erreur.
Original: alexandrebarachant/Grasp-and-lift-EEG-challenge https://github.com/alexandrebarachant/Grasp-and-lift-EEG-challenge
Traitement du signal et pipeline de classification
Aperçu:
Le but de ce défi est de détecter six événements différents (* = événements ) liés aux mouvements de la main lors de la saisie, du levage d'objets, etc. N'utilisez que des ondes cérébrales ( = EEG (non invasives) *). Il est nécessaire de sortir la probabilité de 6 événements dans tous les échantillons de temps. La méthode d'évaluation est AUC (AreaUnderROCcurve) qui couvre 6 événements.
En termes d'ondes cérébrales, les modèles dans le cerveau lors des mouvements de la main sont caractérisés comme des changements dans la fréquence spatiale des signaux des ondes cérébrales. Plus spécifiquement, il devrait y avoir une diminution de la force du signal dans la bande de fréquence du cortex moteur controlatéral MU 12Hz. À mesure que l'intensité du signal du cortex moteur ipsilatéral augmente. Ces changements se produisent après l'exécution du mouvement et certains événements sont étiquetés au début du mouvement (par exemple, commencer à bouger). Il est difficile de noter les six événements avec un seul modèle, étant donné que d'autres sont étiquetés à la fin (comme le remplacement d'objets). En d'autres termes, qu'il s'agisse de prédiction ou de détection dépend de ce qui est classé.
Les six événements représentent différentes étapes d'une série de mouvements de la main (commencer à bouger, commencer à soulever, etc.). L'un des défis était de prendre en compte la structure temporaire de la série. Autrement dit, la relation continue entre les événements. De plus, certains événements se chevauchent et certains se produisent mutuellement exclusifs. Par conséquent, il est difficile d'utiliser une méthode multi-classes ou une machine à états finis (* automate? *) Pour décoder la séquence.
Enfin, l'étiquette Vrai est extraite du signal EMG (* = électromyogramme ) et reçoit une trame de + -150 ms (centrée sur l'occurrence de l'événement). Ces 300 ms n'ont pas de signification psychologique (?). (Semblable à un simple échantillon de 150 + 151 images ( 301 images *) avec des étiquettes différentes pour 150 et 151) Par conséquent, une autre difficulté était d'affiner la prédiction, FalsePositive (= faux positif) A minimiser (sur les bords du cadre).
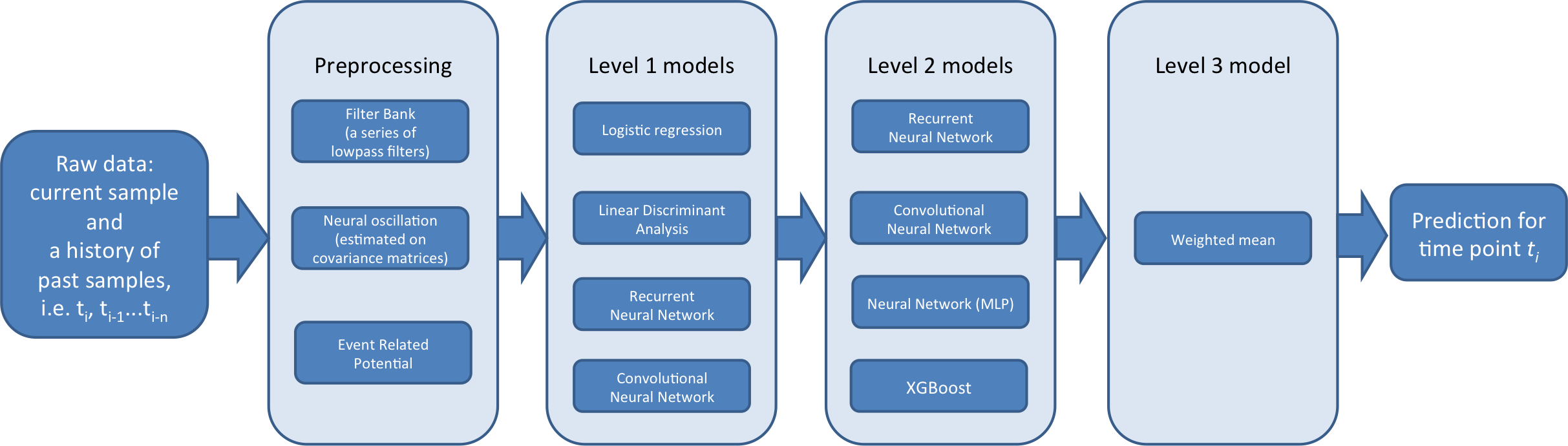
Dans un tel contexte, créez un pipeline de classificateur à trois niveaux:
--Lvl1 est spécifique au sujet. Autrement dit, chaque sujet est formé individuellement. Beaucoup d'entre eux sont également spécifiques à un événement (* c'est-à-dire qu'il semble que de nombreux sujets n'ont qu'un seul mouvement ). L'objectif principal de Lvl1 est de fournir support et polyvalence pour le module Lvl2. En intégrant des sujets et des événements avec différents types de fonctionnalités. ( Le niveau 1 génère une nouvelle fonctionnalité de la fonctionnalité et l'envoie au classificateur de niveau 2 à l'étape suivante *)
--Lvl2 est un modèle global (non spécifique au patient). Formé sur les résultats des prédictions de niveau 1 (méta-fonctionnalités). Leur objectif principal est de considérer la structure temporaire entre les événements. En outre, le fait qu'ils aident à corriger les prédictions parmi les sujets de manière significative dans le monde (* est *).
--Lvl3 est un ensemble de prédiction de Lvl2. Il passe par un algorithme qui optimise le poids de 2 pour maximiser l'AUC. Cette étape améliore la netteté des prédictions, évitant le surapprentissage.
Pas de règles de données futures
Nous avons porté une attention particulière à la relation causale. Un filtre temporaire est appliqué à tout moment, mais la fonction lFilter (Scipy) a été utilisée. C'est une fonction qui implémente le "filtrage causal direct de la forme II". Une fenêtre de diapositive est utilisée à chaque fois, mais nous avons complété le signal avec des zéros sur la gauche. La même idée s'applique lorsque l'historique des prédictions passées est utilisé. (La même idée a été appliquée quand une histoire de prédiction passée a été utilisée) Enfin, étant donné que le signal ou la prédiction était concaténé à travers la série chronologique non traitée, le dernier échantillon de la série précédente peut «fuir». Ce n'est pas une violation des règles. Parce que les règles s'appliquent uniquement dans une chronologie particulière.
Description du modèle
Voici un aperçu du pipeline à 3 niveaux
Lvl1 Le modèle est décrit comme suit. Formé avec des données brutes en mode validation et en mode test (?). Le modèle précédent a été formé dans les séries 1-6, avec des prédictions 7-8 (ces prédictions sont des données d'entraînement de niveau 2 (méta-caractéristiques). Les modes ultérieurs sont entraînés sur les séries 1 à 8 et prédits sur les séries de tests 9 à 10. (* 9-10 est la cible de prédiction à soumettre, apprend 1-6 vers elle, et sort la prédiction de 7-8. Après cela, cela signifie que la prédiction est sortie en entrée et la prédiction de 9-10 est sortie par Lvl2. ? *)
Cov La matrice de covariance est une caractéristique de sélection pour détecter les mouvements de la main à partir des ondes cérébrales. Ils contiennent des informations spatiales (via la co-distribution par canal) et des informations de fréquence (via la distribution du signal). La matrice de covariance est prédite dans une fenêtre de diapositive (généralement 500 échantillons). Après avoir utilisé le filtre passe-bande pour le signal. Il existe deux types de covariance:
-
1.AlexCov: Le libellé de l'événement est d'abord réétiqueté. À une série de 7 états. Pour chaque état cérébral, la moyenne géométrique (* décrite plus loin *) correspondant à chaque matrice de covariance est estimée. (En calculant la métrique euclidienne LOG) Ensuite, lors de la création d'un vecteur d'entités de taille 7, la distance de Lehman à chaque centre de gravité est calculée. Cette procédure peut être considérée comme un encastrement de variétés supervisé avec une métrique riemannienne. (?)
-
2.RafalCov: Même idée que ci-dessus, mais appliquée séparément pour chaque événement. Lors de la création d'un vecteur de caractéristiques de 12 éléments (Il y a 2 classes, 1 et 0, pour chaque événement)
ERP (* Potentiel événementiel, ERP) ) Cet ensemble de données contient des potentiels déclenchés visuellement (liés au paradigme expérimental). Les fonctionnalités de détection ERP asynchrone sont essentiellement basées sur ce qui a été fait dans le défi BCI précédent ( l'auteur a déjà travaillé sur le défi de détection ERP *). Pendant l'entraînement, le signal est daté 1 seconde avant le début de chaque événement. ERP a été moyenné et réduit à l'aide de l'algorithme Xdawn (avant d'être combiné avec un signal établi). Ensuite, la matrice de covariance a été déduite et traitée. Similaire à la fonction de co-dispersion.
FBL Le signal contenait beaucoup d'informations prédictives. Aux basses fréquences. Par conséquent, nous allons introduire la méthode du banc de filtres. Il consiste à combiner les résultats de l'application de certains filtres passe-bas Butterworth d'ordre 5. (Les fréquences de coupure sont 0,5, 1, 2, 3, 4, 5, 7, 9, 15, 30 Hz)
FBL_DELAY Le FBL, cependant, est qu'une seule donnée / observation brute prend également 2 secondes avec 5 échantillons passés (1000 échantillons dans le passé, chacun ne prenant que le 200ème échantillon?). Il est étendu en l'étendant dans un intervalle. Ces fonctionnalités supplémentaires permettent au modèle de capturer la structure temporaire de l'événement.
FBCL Dans la banque de filtres, les caractéristiques de la matrice de covariance sont combinées en un seul ensemble de caractéristiques.
algorithme
** LogisticRegression **, ** LDA (Linear Discrimination Analysis) ** Différentes standardisations sont appliquées aux tests et à la pré-formation) Sous les caractéristiques ci-dessus, une perspective spécifique à l'événement? Est fourni sur les données?
Il existe également deux méthodes LVL1NN, dont aucune n'est spécifique à un événement. (Tous les événements sont appris en même temps) (Suivant)
Convolutional Neural Network Il s'agit d'une famille de modèles (basés sur le script de Tim Hochverg et les ajustements de Bluefool. [Le script de Tim Hochberg avec les ajustements de Bluefool](https://www.kaggle.com/bitsofbits/grasp-and- lift-eeg-detection / naive-nnet): filtre passe-bas et option 2dCONV (il couvre toutes les électrodes, donc chaque filtre capture les dépendances entre toutes les électrodes en même temps.) En résumé, il s'agit d'une petite convolution 1D / 2D NN (entrée → décrochage → 1d / 2dConv → dense → décrochage → dense → décrochage → sortie) Comme être appris avec certains des échantillons actuels et passés. Chaque CNN est étiqueté 100 fois pour réduire la variance relativement élevée (* variation ) entre chaque cycle ( Bagging?, Voir ci-dessous *), Cette exécution est-elle amenée à tirer parti d'une stratégie d'époque efficace qui entraîne le réseau avec une partie aléatoire des données d'apprentissage? Quelque chose comme.
Recurrent Neural Network Petit RNN formé sur le signal après avoir passé le filtre passe-bas (entrée-> décrochage-> GRU-> dense-> décrochage-> sortie) (Banque de filtres de filtre passe-bas et fréquence de coupure de 1, 5, 10, 30 Hz) Entraîné avec un changement de série chronologique court et clairsemé de 8 secondes (prenez chaque 100ème échantillon jusqu'aux 4000 derniers échantillons). RNN semble parfaitement applicable à cette tâche (une structure temporaire bien définie des événements et de leurs dépendances intermédiaires (* interdépendances? *)), Mais en pratique, il obtient de bonnes prédictions. Etait dur. Par conséquent, le coût du calcul était élevé, je ne l'ai donc pas poursuivi autant que je m'y attendais.
Level2 Ces modèles sont formés avec la sortie des modèles de niveau 1. Ils s'entraînent aux modes Validation et Test. La validation est une méthode de validation croisée qui est effectuée et qui est divisée en séries (2 fois (* groupe *)). Les prédictions de chaque pli sont alors méta-caractéristiques (c'est ce que nous appelons les nouvelles fonctionnalités transformées à l'aide du modèle), pour le modèle Lvl3. Ce modèle de mode de test est formé dans les séries 7 et 8, et les prédictions sont générées pour les séries de tests 9 et 10.
algorithme
XGBoost La machine de renforcement de gradient offre une perspective unique sur les données, obtient de très bons scores et apporte de la polyvalence à l'étape suivante du modèle. Seul Lvl2 est formé individuellement pour chaque événement et l'ID du sujet est ajouté en tant que fonctionnalité. Il aide à corriger les prédictions entre les sujets (l'ajout d'un codage à chaud des identifiants de sujet n'améliore pas les performances des modèles basés sur NN). XGBoost prédit correctement un événement particulier, cette précision est très bonne lorsqu'il est formé avec quelques secondes de signaux de série temporelle, avec des méta-fonctionnalités de tous les événements, pas seulement de l'événement correspondant. Parce qu'ils extraient les informations prédictives contenues dans les dépendances intermédiaires entre les événements et les structures transitoires associées. De plus, si vous faites de votre mieux dans le sous-échantillon d'entrée, vous pouvez le standardiser et éviter le surapprentissage.
Recurrent Neural Network Une AUC très élevée peut être obtenue avec une structure temporaire bien définie d'événements et une variété de méta-fonctionnalités de niveau 2. La formation avec Adam a de faibles coûts de calcul (dans de nombreux cas, il ne faut qu'une seule époque pour converger). Le grand nombre de modèles de niveau 2 est une architecture RNN simple avec des modifications mineures (entrée-> décrochage-> GRU-> dense-> décrochage-> sortie), qui est un cours de temps court sous-échantillonné de 8 secondes (* parcours temporel). , Changement de série chronologique, longueur des données d'entrée? *).
Neural Network Entraîné dans une petite chronologie d'historique de 3 secondes sous-échantillonnée à plusieurs couches (une seule couche cachée). C'était pire que les RNN et XGBoost. Mais il a fourni de la polyvalence pour le modèle Lvl3.
Convolutional Neural Network Les petits CNN Lvl2 (une couche de convolution, pas de mise en commun, puis une couche dense) sont entraînés dans un cours temporel d'historique sous-échantillonné de 3 secondes. Un filtre qui couvre toutes les prédictions et les foulées pour un seul échantillon de temps est créé entre les échantillons de temps. Pour les NN multicouches, l'objectif principal de ces CNN est de fournir une polyvalence pour le modèle Lvl3.
La polyvalence du modèle Lvl2 est étendue en exécutant l'algorithme ci-dessus avec les modifications suivantes:
- Transformez les méta-fonctionnalités en différents sous-ensembles --Modifier la durée de l'historique du cours de temps
- Historique des échantillons de journal (* Créer un journal d'échantillons de séries chronologiques? *) (Les points de temps récents sont échantillonnés plus densément que l'échantillonnage par intervalles réguliers) --Bagging (voir ci-dessous)
Pour les NN, CNN, RNN:
--Utilisez ReLu paramétrique au lieu de Relu pour la fonction d'activation de couche dense --Multi-couche
- Changer l'optimiseur (SGD ou ADAM)
Cité de Toki no Mori Wiki http://ibisforest.org/index.php?%E3%83%90%E3%82%AE%E3%83%B3%E3%82%B0
Ensachage †
L'invention concerne un procédé de synthèse de discriminateurs générés en répétant un échantillonnage bootstrap pour générer des discriminateurs avec une précision de discrimination plus élevée. Le nom vient de Bootstrap AGGregatING
Dans le domaine des réseaux neuronaux, on l'appelle aussi machine de comité.
Échantillonnage bootstrap †
Comment créer un nouvel ensemble d'échantillons X 'à partir de l'ensemble d'échantillons X = {xi} N en permettant la duplication et l'échantillonnage
Bagging Certains modèles sont également étiquetés. Pour augmenter sa robustesse. Deux types d'ensachage sont utilisés:
--Sélectionnez un sous-ensemble aléatoire parmi les objectifs d'entraînement. Pour chaque sac (le modèle contient plusieurs sacs dans son nom) (* nom du fichier dans le référentiel de l'auteur *)
- À partir des méta-fonctionnalités de choix d'un sous-ensemble aléatoire, pour chaque sac (nommé bags_model) (* nom de fichier dans le référentiel de l'auteur *)
Trouvé 15 sacs dans tous les cas (* courir? *) Pour obtenir des résultats satisfaisants. L'AUC n'augmente pas beaucoup même si elle est encore augmentée.
Level3 Les prédictions de niveau 2 sont assemblées. Grâce à un algorithme qui optimise les poids d'ensemble pour maximiser l'AUC. Cette étape augmente la netteté (précision?) De la prédiction, et l'utilisation d'une méthode d'ensemble très simple empêche le surapprentissage. (C'était une menace pour l'ensemble (* = surapprentissage ) vraiment avancé ( niveau élevé, = plusieurs étapes? *). Nous avons utilisé trois moyennes pondérées pour:
- Moyenne arithmétique (* moyenne ordinaire *)
- Moyenne géométrique (* Multiplier chacun et prendre la racine *)
- Moyenne de l'indice:
f
\bar x_p = S(\sum x_i^{w_i}) , wherew_i=[0..3] andS is a logistic function that is used to force output into [0..1]
Le modèle Lvl3 est la moyenne des trois moyennes pondérées ci-dessus.
Soumission
| Submission name | CV AUC | SD | Public LB | Private LB |
|---|---|---|---|---|
| "Safe1" | 0.97831 | 0.000014 | 0.98108 | 0.98095 |
| "Safe2" | 0.97846 | 0.000011 | 0.98117 | 0.98111 |
| "YOLO" | 0.97881 | 0.000143 | 0.98128 | 0.98109 |
Safe1 Une validation croisée avec une AUC et une stabilité relativement élevées a été utilisée comme modèle de soumission finale (lvl3). Méta-fonctionnalités robustes de lvl2 (7/8 des modèles de lvl2 sont Baged)? (7 out of 8 level2 models were bagged.)
Safe2 Une autre soumission qui est un CV très stable (* validation croisée? *) AUC. Cette méta fonctionnalité Lvl2 (seulement 6/16 sac)? (seuls 6 modèles de niveau 2 sur 16 ont été mis en sac) a été considéré comme un choix moins sûr pour Lvl2 que safe1 (à tort (?)) Et n'a pas été choisi dans la soumission finale. Je suis juste intéressé ici.
YOLO (* YOLO, signifiant "la vie n'est qu'une fois"? *) La deuxième soumission finale est la moyenne de 18 modèles Lvl3. Les signifier ensemble entraîne une robustesse accrue. Des scores CV et LB publics en validation croisée. Cette soumission est un peu trop apprise et vous pouvez éviter ses coûts de calcul élevés en exécutant Safe1 ou Safe2. Les deux produisent des AUC similaires sur des classements privés.
Discussion
Décodez-vous réellement l'activité du cerveau?
Sur la base d'un large éventail de fonctionnalités, on ne sait pas si ces modèles décodent réellement l'activité cérébrale associée aux mouvements de la main. L'utilisation d'un prétraitement complexe (en raison de fonctionnalités co-distribuées) ou de l'algorithme de la boîte noire (CNN) pose des difficultés supplémentaires. Lors de l'analyse des résultats. (* Est-ce l'histoire du problème que le résultat de NN ne peut pas être expliqué pourquoi cela s'est produit? *)
Les bonnes performances des modèles basés sur des fonctionnalités peu fréquentes soulèvent des doutes supplémentaires. Ces caractéristiques ne sont pas connues pour être particulièrement utiles dans le décodage des mouvements de la main. Plus précisément, il est très difficile d'obtenir de bons résultats en détectant un événement avec une fréquence de 1 Hz ou moins et 300 ms. L'explication change lorsque la ligne de base (* données de forme d'onde de base? ) Change en raison du mouvement du corps, ou lorsque le sujet touche un objet et touche le sol. ( Je comprends que cela signifie qu'il peut être détecté dans de tels cas *)
En outre, avec un modèle de co-dispersion qui prédit dans la bande de fréquences 70-150 Hz, où des performances relativement bonnes peuvent être observées. Cette bande de fréquences contient beaucoup d'EEG (* = onde cérébrale *), et l'activité de l'EMG liée à la tâche est latente.
- Kindenzu (électromyographie --EMG) *
Mais l'ensemble de données est très propre et contient des modèles forts liés à l'événement, qui est ce [script](https://www.kaggle.com/alexandrebarachant/grasp-and-lift-eeg-detection/common- Vous pouvez le voir dans spatial-pattern-with-mne). D'autres activités (VEP *, EMG *, etc.) peuvent contribuer à la performance globale, en forçant des prédictions dans les cas plus difficiles (en renforçant les prédictions pour les cas plus difficiles), mais en fait nous Décode sans aucun doute l'activité cérébrale liée aux mouvements de la main.
- Les potentiels évoqués visuels (VEP) sont des potentiels générés dans la zone visuelle du cortex cérébral en donnant des stimuli visuels (de Wikipedia) *
Avez-vous besoin de tous ces modèles?
Dans ce défi, j'ai fait un grand usage de l'ensemble. Le problème de cette méthode (prédiction de tous les échantillons) a été consacré à ce type de solution. (?) (La façon dont le problème a été défini (prédiction de chaque échantillon) jouait en faveur de ce type de solution), Dans une telle situation, augmenter le nombre de modèles améliorera toujours les performances et la précision de la prédiction.
Dans une application réelle, il n'est pas nécessaire de classer tous les échantillons de temps et une méthode de trame de temps est utilisée, par exemple, une sortie toutes les 250 ms. Je crois qu'il est possible d'obtenir des performances de décodage égales avec une solution plus optimale, en arrêtant l'ensemble à Lvl2 et en n'utilisant qu'un sous-ensemble de certains modèles de niveau 1. (Un pour chaque type de fonctionnalité).
Recommended Posts