Analyse de Big Data à l'aide du framework de contrôle de flux de données Luigi
Qu'est-ce que Luigi
Luigi est un framework de contrôle de flux de données écrit en Python. Développé par Spotify, une importante société de distribution de musique en streaming. Le partenariat avec Sony est également devenu un sujet brûlant.
- Dépôt officiel de Luigi
- Le matériel de présentation du chef de famille est facile à comprendre.
Généralement, dans l'analyse de Big Data, il est nécessaire d'effectuer un certain nombre de processus de nettoyage et de filtrage avant d'effectuer un apprentissage statistique / machine. Les dépendances sont compliquées, et si vous commencez à remplacer des données ou à refaire en cas de panne ou d'interruption, ce n'est rien de plus qu'une pénitence. Luigi peut être utilisé dans un tel cas.
L'origine du nom Luigi est que le flux de données est assimilé à une conduite de distribution d'eau, "le deuxième tuyauteur le plus célèbre au monde, vêtu de vêtements verts". C'est peut-être du vert au lieu du rouge, car c'est la même couleur que celle de Spotify (rires).
Bien qu'il s'agisse de Python, il est facile de le combiner avec Hadoop et Treasure Data ainsi qu'avec le traitement par Python. C'est un outil super puissant qui possède toutes les fonctions que vous souhaitez pour l'analyse des données. Cependant, il semble que la reconnaissance au Japon ne soit pas encore si élevée. Par conséquent, je voudrais l'introduire à des fins missionnaires.
Principales caractéristiques
- Peut écrire des tâches de traitement de données d'une manière orientée objet
- Résoudre la dépendance entre les tâches de l'aval vers l'amont
- Si une erreur survient, elle s'arrêtera là
- Facile à reprendre là où il a échoué
- Assurer l'égalité en déterminant la fin d'une tâche en fonction de la présence ou de l'absence d'un objet de sortie
- Agit comme un cache lorsqu'une tâche faisant référence aux mêmes données est exécutée
- Facilité d'externalisation des paramètres dans le traitement des données
- Une coopération parfaite avec le moteur de base de données, Hadoop (HDFS, MapReduce Streaming, Hive, Spark!)
- Les dépendances et la progression du flux de données peuvent être visualisées avec un navigateur Web
- A une interface de ligne de commande (assez riche)
- Si vous le lancez dans git tel quel, vous pouvez bien gérer la version
- Facile à écrire des tests car c'est une classe Python elle-même
Bref, tout va bien. La seule chose regrettable est que vous ne pouvez pas activer le processus depuis le navigateur. De plus, le manuel concernant Hadoop n'est pas développé et je dois lire la source pour comprendre les spécifications.
Méthode d'introduction
sudo pip install luigi
C'est tout ce dont vous avez besoin pour entrer.
Comment écrire
L'unité minimale de traitement est Tâche
La plus petite unité de traitement Luigi est appelée Tâche et est gérée. 1 Ecrivez une classe qui hérite de la classe luigi.Task () pour Task.
Comment décrire la dépendance entre les tâches
Luigi décrit une chaîne de flux de données en reliant de l'aval à l'amont.
La classe luigi.Task () a la méthode suivante comme méthode.
requires (): Tâche dépendante en amont- ʻOutput ()
: objet de sortie (nom de fichier enveloppé dans la classe de familleluigi.Target () `) run (): Traitement dans la tâche

De cette façon, vous n'avez pas à encombrer vos dépendances. De plus, vous n'avez pas besoin d'écrire le fichier deux fois, du côté dépendant et du côté dépendant.
Lors de l'exécution, appelez la tâche la plus en aval. En faisant cela, Luigi résoudra automatiquement la dépendance en amont et l'exécutera dans l'ordre. À ce stade, si vous définissez plusieurs options --workers, les parties qui peuvent être parallélisées seront automatiquement exécutées en parallèle.
Illustration
D'ici, Exemple officiel de Luigi, [top_artists.py](https://github.com/spotify/luigi/blob/master/examples/top_artists.py Voyons comment écrire en utilisant) comme exemple.
Il s'agit d'un script qui imite l'agrégation quotidienne des vues d'artistes. Les journaux de lecture des chansons sont agrégés quotidiennement et les 10 meilleurs artistes sont extraits.
Dans top_artists.py, Top10Artists () [Trier et afficher les 10 premiers] -> ʻAggrigateArtists () [Agréger le nombre de vues pour chaque artiste] -> Le flux de données est décrit comme Streams ()` [journal quotidien].
top_artists.py
class Top10Artists(luigi.Task):
"""
This task runs over the target data returned by :py:meth:`~/.AggregateArtists.output` or
:py:meth:`~/.AggregateArtistsHadoop.output` in case :py:attr:`~/.Top10Artists.use_hadoop` is set and
writes the result into its :py:meth:`~.Top10Artists.output` target (a file in local filesystem).
"""
date_interval = luigi.DateIntervalParameter()
use_hadoop = luigi.BoolParameter()
def requires(self):
"""
This task's dependencies:
* :py:class:`~.AggregateArtists` or
* :py:class:`~.AggregateArtistsHadoop` if :py:attr:`~/.Top10Artists.use_hadoop` is set.
:return: object (:py:class:`luigi.task.Task`)
"""
if self.use_hadoop:
return AggregateArtistsHadoop(self.date_interval)
else:
return AggregateArtists(self.date_interval)
def output(self):
"""
Returns the target output for this task.
In this case, a successful execution of this task will create a file on the local filesystem.
:return: the target output for this task.
:rtype: object (:py:class:`luigi.target.Target`)
"""
return luigi.LocalTarget("data/top_artists_%s.tsv" % self.date_interval)
def run(self):
top_10 = nlargest(10, self._input_iterator())
with self.output().open('w') as out_file:
for streams, artist in top_10:
out_line = '\t'.join([
str(self.date_interval.date_a),
str(self.date_interval.date_b),
artist,
str(streams)
])
out_file.write((out_line + '\n'))
def _input_iterator(self):
with self.input().open('r') as in_file:
for line in in_file:
artist, streams = line.strip().split()
yield int(streams), artist
L'intérieur de chaque méthode peut être écrit en Python ordinaire. Par conséquent, il est possible de changer la dépendance en fonction du paramètre donné de l'extérieur et de décrire la dépendance à plusieurs tâches à l'aide d'une liste ou d'un dictionnaire.
Dans l'exemple de top_artitsts.py, la tâche de ʻAggrigateArtists () retourne le journal quotidien. En se référant à plusieurs tâches de Streams () `dans la liste, les données quotidiennes sont agrégées pendant un mois.
Pour l'exécuter, entrez la commande comme indiqué ci-dessous.
python top_artists.py Top10Artists --date-interval 2015-03 --local-scheduler
Luigi Scheduler
La commande luigid lance le planificateur. Même si un grand nombre de tâches sont reçues de plusieurs clients, elles seront exécutées dans l'ordre.
De plus, si vous accédez à localhost: 8082 depuis votre navigateur, vous pouvez visualiser la progression du traitement et des dépendances.
Pour lancer une tâche au planificateur, exécutez-la sans l'option --local-scheduler.
python top_artists.py Top10Artists --date-interval 2015-03
Un exemple de visualisation des dépendances est présenté ci-dessous.
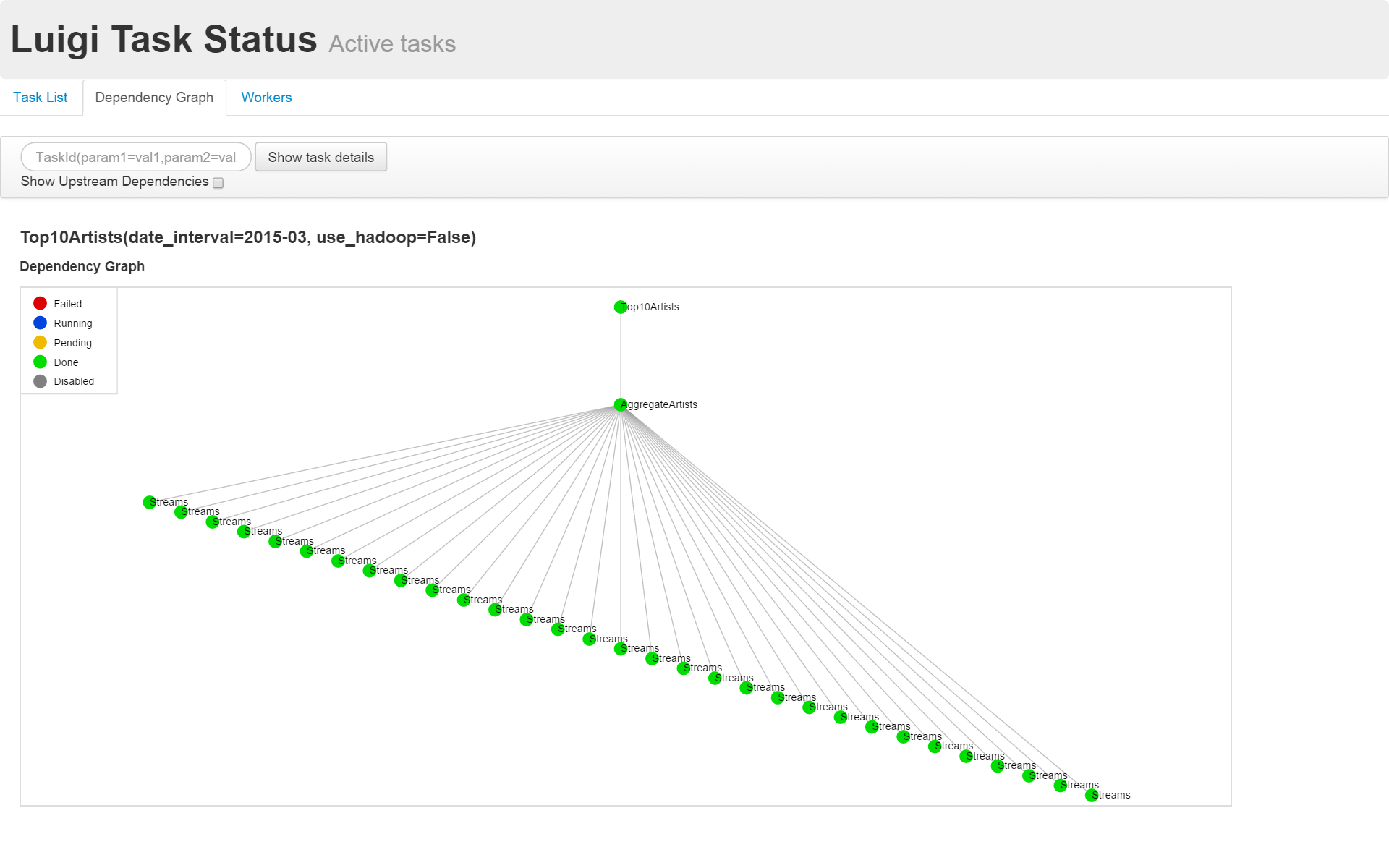
Exemple d'utilisation
J'ai essayé d'utiliser Luigi pour mon Common Kanji Analysis Script. J'ose connecter les commandes de filtre écrites en Ruby avec Luigi au lieu de les connecter avec le pipeline UNIX. C'est un peu surimplémenté, mais il est plus facile de vérifier l'opération car les fichiers intermédiaires sont sûrement laissés. De plus, c'est bien car vous n'avez pas à l'écrire deux fois du côté qui dépend du nom du fichier.
... Je suis désolé, rien de ce qui précède n'était du big data.
Recommended Posts