Comment dessiner de manière interactive un pipeline d'apprentissage automatique avec scikit-learn et l'enregistrer au format HTML
Dans cet article, j'expliquerai l'implémentation de la confirmation de pipeline interactive installée à partir de la v0.23 de scikit-learn, et comment la sauvegarder et l'utiliser au format HTML.
environnement
- scikit-learn==0.23.2
- Google Colaboratory
Le code d'implémentation de cet article est ici https://github.com/YutaroOgawa/Qiita/tree/master/sklearn
la mise en oeuvre
[1] Mise à jour de la version
Tout d'abord, la version de scikit-learn de Google Colaboratory est la v0.22 en septembre 2020, alors mettez-la à jour vers la v0.23.
!pip install scikit-learn==0.23.2
Après la mise à jour avec pip, exécutez "Runtime" -> "Restart runtime" de Google Colaboratory, Redémarrez le runtime. (Ceci est la nouvelle v0.23 que scikit-learn a mis avec pip)
[2] Construction du pipeline
Par exemple, le modèle de prétraitement et d'apprentissage automatique a été combiné comme suit: Créez un ** pipeline d'apprentissage automatique **.
[Effectuer l'importation nécessaire]
python
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import make_column_transformer
from sklearn.linear_model import LogisticRegression
[Construire un pipeline]
```python```
#Prétraitement des données numériques (normalisation en complétant les valeurs manquantes par la valeur médiane)
num_proc = make_pipeline(SimpleImputer(strategy='median'), StandardScaler())
#Prétraitement des données de catégorie (pour les valeurs manquantes"misssing"Achèvement de la substitution, un encodage à chaud)
cat_proc = make_pipeline(
SimpleImputer(strategy='constant', fill_value='missing'),
OneHotEncoder(handle_unknown='ignore'))
#Créer une classe de prétraitement
preprocessor = make_column_transformer((num_proc, ('feat1', 'feat3')),
(cat_proc, ('feat0', 'feat2')))
#Combinez les modèles de prétraitement et d'apprentissage automatique en un seul pipeline
clf = make_pipeline(preprocessor, LogisticRegression())
[3] Visualisation interactive du pipeline
Pour visualiser de manière interactive le pipeline, c'est simple,
sklearn.set_config(display="diagram")
Il suffit d'ajouter.
[Visualisation interactive]
python
Paramètres pour afficher le pipeline
from sklearn import set_config
set_config(display="diagram")
dessin
clf
Ensuite, le pipeline sera dessiné dans la colonne de résultats de JupyterNotebook (Google Colabortory) comme indiqué ci-dessous.
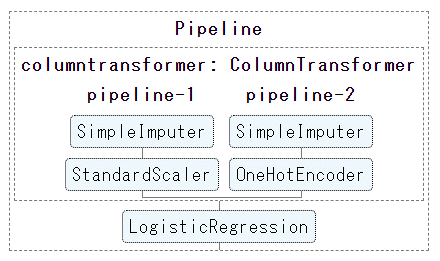
Cliquez sur chaque élément de ce diagramme de pipeline
L'image change de manière interactive, affichant les paramètres détaillés de cet élément.
(La figure ci-dessous montre la confirmation détaillée de la méthode de traitement des valeurs manquantes pour le prétraitement des colonnes: pipeline.-Cliquez sur 2 Impacteur simple)

##Comment enregistrer le pipeline au format HTML
Comme vous l'avez mentionné dans les commentaires, vous pouvez enregistrer ce pipeline interactif au format HTML.
"C'est un peu si ça ne marche que sur Jupyter Notebook ..."
J'ai pensé, donc c'est une très belle information.
@Merci à DataSkywalker.
Enfin, comme implémentation,
```python
from sklearn.utils import estimator_html_repr
with open('my_estimator.html', 'w') as f:
f.write(estimator_html_repr(clf))
Éxécuter. Alors mon_estimator.Le code HTML du pipeline interactif est enregistré au format html.
Avec Google Colaboratory
# Télécharger depuis Google Colaboratory
from google.colab import files
files.download('my_estimator.html')
En exécutant mon_estimator.Vous pouvez télécharger html (Le contenu était d'environ 300 lignes, y compris le style CSS dans le fichier HTML).
En tant que matériau pour expliquer le pipeline de manière interactive Il semble que vous puissiez coller du HTML dans des documents, etc.
Vous pouvez le mettre dans le fichier md sous forme de lien, ou vous pouvez le convertir de force en html, puis le combiner. (Il est difficile de lire le html tel qu'il est dans le fichier md ...?)

Tous les fichiers ici sont également placés ici https://github.com/YutaroOgawa/Qiita/tree/master/sklearn
##Résumé
scikit-Apprendre la version v0.23 ou plus
sklearn.set_config(display="diagram")Il suffit d'ajouter
Vous pouvez visualiser de manière interactive (et enregistrer au format HTML) votre pipeline.
Veuillez l'essayer ♪
###Remarques
**【Écrivain】**Service d'information international de Dentsu (ISID)Centre de transformation de l'IADéveloppement Gr Yutaro Ogawa (livre principal)"Apprenez en créant!Développement Deep Learning par PyTorch ",Autre"Détailsdel'auto-introduction")
【Twitter】 En me concentrant sur l'IT / IA et le business / management, j'envoie des articles que je trouve intéressants et des impressions de nouveaux livres que j'ai récemment lus. Si vous souhaitez collecter des informations sur ces champs, veuillez nous suivre ♪ (Il y a beaucoup d'informations à l'étranger)
[Autre] L '«équipe de développement AI Transformation Center» que je dirige recherche des membres. Si tu es intéressé,Cette pageNous attendons de recevoir votre demande.
[Sokumen-kun] Si vous souhaitez postuler soudainement, nous aurons un entretien informel avec "Sokumen-kun". Veuillez également l'utiliser ♪ https://sokumenkun.com/2020/08/17/yutaro-ogawa/
[Disclaimer] Le contenu de cet article est l'opinion de l'auteur./Il s'agit d'une transmission et non d'une vision officielle de l'entreprise à laquelle appartient l'auteur.
(référence) https://scikit-learn.org/stable/auto_examples/release_highlights/plot_release_highlights_0_23_0.html https://towardsdatascience.com/9-things-you-should-know-about-scikit-learn-0-23-9426d8e1772c
Recommended Posts