"""
## 49.Extraction de chemins de dépendances entre nomenclature[Permalink](https://nlp100.github.io/ja/ch05.html#49-Extractiondecheminsdedépendancesentrenomenclature)
Extrayez le chemin de dépendance le plus court qui relie toutes les paires de nomenclatures de la phrase. Cependant, les numéros de clause de la paire de nomenclatures sont ii et jj (i)<ji<Dans le cas de j), le chemin de dépendance doit satisfaire aux spécifications suivantes.
-Comme dans la question 48, le chemin décrit la représentation (séquence morphologique de surface) de chaque phrase de la clause de début à la clause de fin.` -> `Express en vous connectant avec
-Remplacez la nomenclature contenue dans les clauses ii et jj par X et Y, respectivement.
De plus, la forme du chemin de dépendance peut être considérée des deux manières suivantes.
-Lorsque la clause jj existe sur le chemin de la clause ii à la racine de l'arbre syntaxique:Afficher le chemin de la clause jj de la clause ii
-Autre que ce qui précède, lorsque la clause ii et la clause jj se croisent à une clause commune kk sur la route à partir de la racine de l'arbre de syntaxe:Le chemin immédiatement avant la phrase ii vers la phrase kk, le chemin immédiatement avant la phrase jj vers la phrase kk et le contenu de la phrase kk sont décrits comme "` | `Affichage en se connectant avec
Prenons l'exemple de la phrase «John McCarthy a inventé le terme intelligence artificielle lors de la première conférence sur l'IA». Lorsque CaboCha est utilisé pour l'analyse des dépendances, la sortie suivante peut être obtenue.
'''
X est|À propos de Y->la première->À une réunion|Créé
X est|Y->À une réunion|Créé
X est|En Y|Créé
X est|Appelé Y->Terminologie|Créé
X est|Oui|Créé
À propos de X->Y
À propos de X->la première->En Y
À propos de X->la première->À une réunion|Appelé Y->Terminologie|Créé
À propos de X->la première->À une réunion|Oui|Créé
De X->En Y
De X->À une réunion|Appelé Y->Terminologie|Créé
De X->À une réunion|Oui|Créé
Avec X|Appelé Y->Terminologie|Créé
En X|Oui|Créé
Appelé X->Oui
'''
[Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(je), Morph(Est)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ici), Morph(alors)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(début), Morph(main)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Humain), Morph(Cette)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(chose), Morph(À)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(Vous voyez), Morph(Ta), Morph(。)] )]
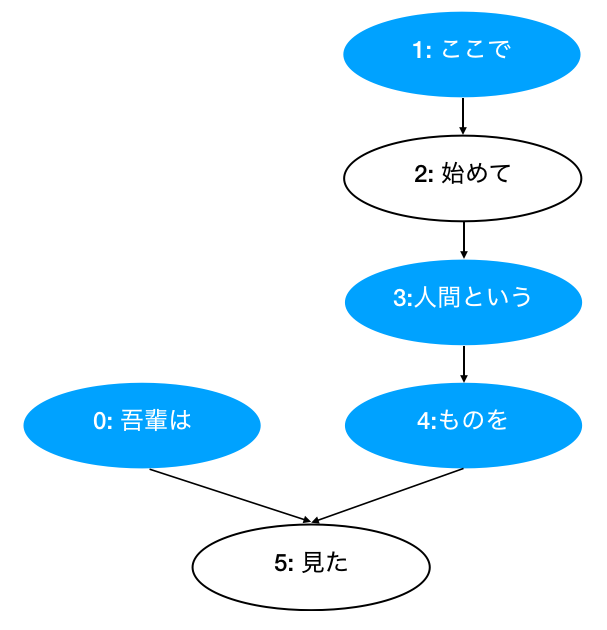
'''
Pattern 1 (Without root)
1 -> 3 -> 4
1 -> 3
1 -> 4
3 -> 4
Pattern 2 (With root):
From 0 to 1:
0 | 1 -> 3 -> 4 | 5
From 0 to 3:
0 | 3 -> 4 | 5
From 0 to 4:
0 | 4 | 5
'''
"""
from collections import defaultdict
from typing import List
def read_file(fpath: str) -> List[List[str]]:
"""Get clear format of parsed sentences.
Args:
fpath (str): File path.
Returns:
List[List[str]]: List of sentences, and each sentence contains a word list.
e.g. result[1]:
['* 0 2D 0/0 -0.764522',
'\u3000\symbole t,Vide,*,*,*,*,\u3000,\u3000,\u3000',
'* 1 2D 0/1 -0.764522',
'je\t substantif,Synonyme,Général,*,*,*,je,Wagahai,Wagahai',
'Est\t assistant,Assistance,*,*,*,*,Est,C,sensationnel',
'* 2 -1D 0/2 0.000000',
'Chat\t substantif,Général,*,*,*,*,Chat,chat,chat',
'alors\t verbe auxiliaire,*,*,*,Spécial,Type continu,Est,De,De',
'y a-t-il\t verbe auxiliaire,*,*,*,Cinq étapes, La ligne Al,Forme basique,y a-t-il,Al,Al',
'。\symbole t,Phrase,*,*,*,*,。,。,。']
"""
with open(fpath, mode="rt", encoding="utf-8") as f:
sentences = f.read().split("EOS\n")
return [sent.strip().split("\n") for sent in sentences if sent.strip() != ""]
class Morph:
"""Morph information for each token.
Args:
data (dict): A dictionary contains necessary information.
Attributes:
surface (str):Surface
base (str):Base
pos (str):Partie (base)
pos1 (str):Sous-classification des pièces détachées 1 (pos1)
"""
def __init__(self, data):
self.surface = data["surface"]
self.base = data["base"]
self.pos = data["pos"]
self.pos1 = data["pos1"]
def __repr__(self):
return f"Morph({self.surface})"
def __str__(self):
return "surface[{}]\tbase[{}]\tpos[{}]\tpos1[{}]".format(
self.surface, self.base, self.pos, self.pos1
)
class Chunk:
"""Containing information for Clause/phrase.
Args:
data (dict): A dictionary contains necessary information.
Attributes:
chunk_id (int): The number of clause chunk (Numéro de phrase).
morphs List[Morph]: Morph (morphème) list.
dst (int): The index of dependency target (Numéro d'index de la clause de contact).
srcs (List[str]): The index list of dependency source. (Numéro d'index de la clause d'origine).
"""
def __init__(self, chunk_id, dst):
self.id = int(chunk_id)
self.morphs = []
self.dst = int(dst)
self.srcs = []
def __repr__(self):
return "Chunk( id: {}, dst: {}, srcs: {}, morphs: {} )".format(
self.id, self.dst, self.srcs, self.morphs
)
def get_surface(self) -> str:
"""Concatenate morph surfaces in a chink.
Args:
chunk (Chunk): e.g. Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(je), Morph(Est)]
Return:
e.g. 'je suis'
"""
morphs = self.morphs
res = ""
for morph in morphs:
if morph.pos != "symbole":
res += morph.surface
return res
def validate_pos(self, pos: str) -> bool:
"""Return Ture if 'nom' or 'verbe' in chunk's morphs. Otherwise, return False."""
morphs = self.morphs
return any([morph.pos == pos for morph in morphs])
def get_noun_masked_surface(self, mask: str) -> str:
"""Get masked surface.
Args:
mask (str): e.g. X or Y.
Returns:
str: 'je suis' -> 'X est'
'Humain' -> 'Appelé Y'
"""
morphs = self.morphs
res = ""
for morph in morphs:
if morph.pos == "nom":
res += mask
elif morph.pos != "symbole":
res += morph.surface
return res
def convert_sent_to_chunks(sent: List[str]) -> List[Morph]:
"""Extract word and convert to morph.
Args:
sent (List[str]): A sentence contains a word list.
e.g. sent:
['* 0 1D 0/1 0.000000',
'je\t substantif,Synonyme,Général,*,*,*,je,Wagahai,Wagahai',
'Est\t assistant,Assistance,*,*,*,*,Est,C,sensationnel',
'* 1 -1D 0/2 0.000000',
'Chat\t substantif,Général,*,*,*,*,Chat,chat,chat',
'alors\t verbe auxiliaire,*,*,*,Spécial,Type continu,Est,De,De',
'y a-t-il\t verbe auxiliaire,*,*,*,Cinq étapes, La ligne Al,Forme basique,y a-t-il,Al,Al',
'。\symbole t,Phrase,*,*,*,*,。,。,。']
Parsing format:
e.g. "* 0 1D 0/1 0.000000"
|colonne|sens|
| :----: | :----------------------------------------------------------- |
| 1 |La première colonne est`*`.. Indique qu'il s'agit d'un résultat d'analyse des dépendances.|
| 2 |Numéro de phrase (entier à partir de 0)|
| 3 |Numéro de contact +`D` |
| 4 |Adresse principale/Position du mot de fonction et nombre illimité de colonnes d'identité|
| 5 |Score d'engagement. En général, plus la valeur est élevée, plus il est facile de s'engager.|
Returns:
List[Chunk]: List of chunks.
"""
chunks = []
chunk = None
srcs = defaultdict(list)
for i, word in enumerate(sent):
if word[0] == "*":
# Add chunk to chunks
if chunk is not None:
chunks.append(chunk)
# eNw Chunk beggin
chunk_id = word.split(" ")[1]
dst = word.split(" ")[2].rstrip("D")
chunk = Chunk(chunk_id, dst)
srcs[dst].append(chunk_id) # Add target->source to mapping list
else: # Add Morch to chunk.morphs
features = word.split(",")
dic = {
"surface": features[0].split("\t")[0],
"base": features[6],
"pos": features[0].split("\t")[1],
"pos1": features[1],
}
chunk.morphs.append(Morph(dic))
if i == len(sent) - 1: # Add the last chunk
chunks.append(chunk)
# Add srcs to each chunk
for chunk in chunks:
chunk.srcs = list(srcs[chunk.id])
return chunks
class Sentence:
"""A sentence contains a list of chunks.
e.g. [Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(je), Morph(Est)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ici), Morph(alors)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(début), Morph(main)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Humain), Morph(Cette)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(chose), Morph(À)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(Vous voyez), Morph(Ta), Morph(。)] )]
"""
def __init__(self, chunks):
self.chunks = chunks
self.root = None
def __repr__(self):
message = f"""Sentence:
{self.chunks}"""
return message
def get_root_chunk(self):
chunks = self.chunks
for chunk in chunks:
if chunk.dst == -1:
return chunk
def get_noun_path_to_root(self, src_chunk: Chunk) -> List[Chunk]:
"""Get path from noun Chunk to root Chunk.
e.g. [Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(je), Morph(Est)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ici), Morph(alors)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(début), Morph(main)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Humain), Morph(Cette)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(chose), Morph(À)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(Vous voyez), Morph(Ta), Morph(。)] )]
Args:
src_chunk (Chunk): A Chunk. e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ici), Morph(alors)] ),
Returns:
List[Chunk]: The path from a chunk to root.
The path from 'ici' to 'vu': ici ->Humain->Des choses-> vu
So we should get: ['ici', 'Humain', 'Des choses', 'vu']
"""
chunks = self.chunks
path = [src_chunk]
dst = src_chunk.dst
while dst != -1:
dst_chunk = chunks[dst]
if dst_chunk.validate_pos("nom") and dst_chunk.dst != -1:
path.append(dst_chunk)
dst = chunks[dst].dst
return path
def get_path_between_nouns(self, src_chunk: Chunk, dst_chunk: Chunk) -> List[Chunk]:
"""[summary]

Example:
[Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(je), Morph(Est)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ici), Morph(alors)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(début), Morph(main)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Humain), Morph(Cette)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(chose), Morph(À)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(Vous voyez), Morph(Ta), Morph(。)] )]
Two patterns:
Pattern 1 (Without root): save as a list.
1 -> 3 -> 4
1 -> 3
1 -> 4
3 -> 4
Pattern 2 (With root): save as a dict.
From 0 to 1:
0 | 1 -> 3 -> 4 | 5
From 0 to 3:
0 | 3 -> 4 | 5
From 0 to 4:
0 | 4 | 5
Pattern 1:
src_chunk (Chunk): e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ici), Morph(alors)] ),
dst_chunk (Chunk): e.g. Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(chose), Morph(À)] )
Path:
From 'ici' to 'Des choses': ici ->Humain-> Des choses
Returns:
List[Chunk]: [Chunk(Humain)]
Pattern 2:
src_chunk (Chunk): e.g. Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(je), Morph(Est)] ),
dst_chunk (Chunk): e.g. Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Humain), Morph(Cette)] )
Path:
From Chunk(je suis) to Chunk(Humain):
0 | 3 -> 4 | 5
- Chunk(je suis) -> Chunk(vu)
- Chunk(Humain) -> Chunk(Des choses) -> Chunk(vu)
Returns:
Dict: {'src_to_root': [Chunk(je suis)],
'dst_to_root': [Chunk(Humain), Chunk(Des choses)]}
"""
chunks = self.chunks
pattern1 = []
pattern2 = {"src_to_root": [], "dst_to_root": []}
if src_chunk.dst == dst_chunk.id:
return pattern1
current_src_chunk = chunks[src_chunk.dst]
while current_src_chunk.dst != dst_chunk.id:
# Pattern 1
if current_src_chunk.validate_pos("nom"):
pattern1.append(src_chunk)
# Pattern 2
if current_src_chunk.dst == -1:
pattern2["src_to_root"] = self.get_noun_path_to_root(src_chunk)
pattern2["dst_to_root"] = self.get_noun_path_to_root(dst_chunk)
return pattern2
current_src_chunk = chunks[current_src_chunk.dst]
return pattern1
def write_to_file(sents: List[dict], path: str) -> None:
"""Write to file.
Args:
sents ([type]):
e.g. [[['je suis', 'Être un chat']],
[['Nom est', 'Non']],
[['où', 'Est né', 'Ne pas utiliser'], ['J'ai un indice', 'Ne pas utiliser']]]
"""
# convert_frame_to_text
lines = []
for sent in sents:
for chunk in sent:
lines.append(" -> ".join(chunk))
# write_to_file
with open(path, "w") as f:
for line in lines:
f.write(f"{line}\n")
def get_pattern1_text(src_chunk, path_chunks, dst_chunk):
"""
Pattern 1:
src_chunk (Chunk): e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(ici), Morph(alors)] ),
dst_chunk (Chunk): e.g. Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(chose), Morph(À)] )
Path:
From 'ici' to 'Des choses': ici ->Humain-> Des choses
path_chunks:
List[Chunk]: [Chunk(Humain)]
"""
path = []
path.append(src_chunk.get_noun_masked_surface("X"))
for path_chunk in path_chunks:
path.append(path_chunk.get_surface())
path.append(dst_chunk.get_noun_masked_surface("Y"))
return " -> ".join(path)
def get_pattern2_text(path_chunks, sent):
"""
Path:
From Chunk(je suis) to Chunk(Humain):
0 | 3 -> 4 | 5
- Chunk(je suis) -> Chunk(vu)
- Chunk(Humain) -> Chunk(Des choses) -> Chunk(vu)
path_chunks:
Dict: {'src_to_root': [Chunk(je suis)],
'dst_to_root': [Chunk(Humain), Chunk(Des choses)]}
"""
path_text = "{} | {} | {}"
src_path = []
for i, chunk in enumerate(path_chunks["src_to_root"]):
if i == 0:
src_path.append(chunk.get_noun_masked_surface("X"))
else:
src_path.append(chunk.get_surface())
src_text = " -> ".join(src_path)
dst_path = []
for i, chunk in enumerate(path_chunks["dst_to_root"]):
if i == 0:
dst_path.append(chunk.get_noun_masked_surface("Y"))
else:
dst_path.append(chunk.get_surface())
dst_text = " -> ".join(dst_path)
root_chunk = sent.get_root_chunk()
root_text = root_chunk.get_surface()
return path_text.format(src_text, dst_text, root_text)
def get_paths(sent_chunks: List[Sentence]):
paths = []
for sent_chunk in sent_chunks:
sent = Sentence(sent_chunk)
chunks = sent.chunks
for i, src_chunk in enumerate(chunks):
if src_chunk.validate_pos("nom") and i + 1 < len(chunks):
for j, dst_chunk in enumerate(chunks[i + 1 :]):
if dst_chunk.validate_pos("nom"):
path_chunks = sent.get_path_between_nouns(src_chunk, dst_chunk)
if isinstance(path_chunks, list): # Pattern 1
paths.append(
get_pattern1_text(src_chunk, path_chunks, dst_chunk)
)
if isinstance(path_chunks, dict): # Pattern 2
paths.append(get_pattern2_text(path_chunks, sent))
return paths
fpath = "neko.txt.cabocha"
sentences = read_file(fpath)
sent_chunks = [convert_sent_to_chunks(sent) for sent in sentences] # ans41
# ans49
paths = get_paths(sent_chunks)
for p in paths[:20]:
print(p)
#X est|En Y->Humain->Des choses|vu
#X est|Appelé Y->Des choses|vu
#X est|Oui|vu
#Avec X->Appelé Y
#En X->Oui
#Appelé X->Oui
Recommended Posts