Prédiction des ondes sinusoïdales à l'aide de RNN dans la bibliothèque d'apprentissage en profondeur Keras
introduction
Keras est une bibliothèque de wrapper d'apprentissage en profondeur basée sur Theano et TensorFlow. Grâce à Theano et TensorFlow, il est devenu beaucoup plus facile d'entrer dans le deep learning, mais il est encore difficile d'écrire l'algorithme. Ainsi, Keras est une librairie qui permet d'écrire une structure de réseau assez simplement. Pour un aperçu de Keras lui-même, id: article de l'aidiary a été très utile.
En tant qu'échantillon de base de Keras, je vois beaucoup de classifications MNIST, mais je n'ai pas trouvé beaucoup d'échantillons simples utilisant RNN (Keras officiellement Exemple de classification des émotions de films utilisant RNN, mais c'était trop compliqué à gérer au début). Par conséquent, cette fois, je vais essayer l'implémentation RNN de Keras à travers un simple échantillon d'entraînement et de prédiction des ondes de sinus dans LSTM. Pour l'implémentation RNN utilisant TensorFlow, j'ai écrit un article sur ici avant, donc si vous êtes intéressé, veuillez le voir.
20.11.2017 postscript
Cette fois, nous prédisons les ondes de péché en mettant l'accent sur la compréhensibilité, mais comme nous voulions traiter des données de séries chronologiques plus complexes, nous avons utilisé [Python] QRNN pour prédire les données de séries chronologiques du chaos [Keras]](https://qiita.com). J'ai créé un article appelé / yukiB / items / 681f68690ffabbf3e1e1).
Installation
Keras peut utiliser à la fois Theano et Tensorflow comme backends, et les programmes écrits en Keras peuvent être commutés à tout moment sans aucune modification (Il semble y avoir quelques mises en garde. / nzw0301 / items / 2823243090b997aa00e5)), mais cette fois, je vais essayer la méthode en utilisant TensorFlow comme back-end.
On suppose que TensorFlow est installé à l'avance.
L'installation de Keras se fait normalement à l'aide de pip
pip install keras
Mais c'est d'accord,
Après avoir cloné la source par git
python setup.py install
Mais ça va.
Lorsque vous utilisez TensorFlow comme back-end, réécrivez le fichier de paramètres ~ / .keras / keras.json comme suit (voir documentation keras. Keras.json. Est généré par le premier démarrage (importation, etc.) de keras).
# before
{
"image_dim_ordering": "th",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "theano"
}
# after
{
"image_dim_ordering": "th",
"epsilon": 1e-07,
"floatx": "float32",
"backend": "tensorflow"
}
Le backend par défaut est pour Theano, mais avec la réécriture ci-dessus,
import keras
Quand tu fais
Using TensorFlow backend.
Doit être affiché.
Prédisez l'onde de péché avec le LSTM de Keras.
Création de données
Commencez par créer les données. Les données ont été créées par l'article de yuyakato J'ai essayé de prédire en laissant RNN apprendre les ondes de péché J'étais autorisé à me référer.
import pandas as pd
import numpy as np
import math
import random
%matplotlib inline
random.seed(0)
#Coefficient aléatoire
random_factor = 0.05
#Nombre d'étapes par cycle
steps_per_cycle = 80
#Nombre de cycles à générer
number_of_cycles = 50
df = pd.DataFrame(np.arange(steps_per_cycle * number_of_cycles + 1), columns=["t"])
df["sin_t"] = df.t.apply(lambda x: math.sin(x * (2 * math.pi / steps_per_cycle)+ random.uniform(-1.0, +1.0) * random_factor))
df[["sin_t"]].head(steps_per_cycle * 2).plot()
Créez une onde sinueuse avec du bruit comme indiqué ci-dessous.

Ensuite, classez-les en données d'apprentissage et en données de test, et créez un ensemble de données de sorte que la sortie y lorsqu'il y a une entrée X pendant 100 étapes soit la 101e étape.
def _load_data(data, n_prev = 100):
"""
data should be pd.DataFrame()
"""
docX, docY = [], []
for i in range(len(data)-n_prev):
docX.append(data.iloc[i:i+n_prev].as_matrix())
docY.append(data.iloc[i+n_prev].as_matrix())
alsX = np.array(docX)
alsY = np.array(docY)
return alsX, alsY
def train_test_split(df, test_size=0.1, n_prev = 100):
"""
This just splits data to training and testing parts
"""
ntrn = round(len(df) * (1 - test_size))
ntrn = int(ntrn)
X_train, y_train = _load_data(df.iloc[0:ntrn], n_prev)
X_test, y_test = _load_data(df.iloc[ntrn:], n_prev)
return (X_train, y_train), (X_test, y_test)
length_of_sequences = 100
(X_train, y_train), (X_test, y_test) = train_test_split(df[["sin_t"]], n_prev =length_of_sequences)
La modélisation
Maintenant que l'ensemble de données est complet, il est temps d'écrire la configuration réseau à l'aide de Keras.
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers.recurrent import LSTM
in_out_neurons = 1
hidden_neurons = 300
model = Sequential()
model.add(LSTM(hidden_neurons, batch_input_shape=(None, length_of_sequences, in_out_neurons), return_sequences=False))
model.add(Dense(in_out_neurons))
model.add(Activation("linear"))
model.compile(loss="mean_squared_error", optimizer="rmsprop")
model.fit(X_train, y_train, batch_size=600, nb_epoch=15, validation_split=0.05)
Seulement ça. Comme mentionné ci-dessus, la structure du réseau neuronal peut être construite en ajoutant diverses couches au `` modèle ''. Dans l'exemple ci-dessus, une entrée avec un tenseur de (, 100, 1) est jetée dans 300 couches intermédiaires LSTM, agrégée en une couche de sortie et multipliée par une fonction d'activation linéaire.
À propos, LSTM est une forme tridimensionnelle avec un Tensor d'entrée (batch_size, input_length, in_data_length). La sortie est
- return_sequences=True -> (batch_size, input_length, out_data_length)
- return_sequences=False -> (batch_size, out_data_length)
C'est la forme.
Lors de la compilation du modèle, spécifiez la fonction d'erreur (erreur quadratique moyenne dans l'exemple) et l'algorithme d'optimisation (RMSprop dans l'exemple). Bien sûr, l'entropie croisée peut être utilisée pour la fonction d'erreur, et les algorithmes d'optimisation sont complets, du SGD de base à Adam et RMSprop.
La formation est effectuée avec fit (), et vous pouvez spécifier le pourcentage des données de formation à utiliser comme données de formation et données d'enseignant, taille de lot, taille d'époque et données de validation.
Aussi,
# early stopping
early_stopping = EarlyStopping(monitor='val_loss', patience=2)
model.fit(X_train, y_train, batch_size=600, nb_epoch=15, validation_split=0.05, callbacks=[early_stopping])
En spécifiant le rappel de jugement de convergence comme dans, la boucle peut être arrêtée automatiquement lorsqu'elle converge.
Train on 3325 samples, validate on 176 samples
Epoch 1/15
3325/3325 [==============================] - 17s - loss: 0.0051 - val_loss: 0.0048
Epoch 2/15
1200/3325 [=========>....................] - ETA: 10s - loss: 0.0041
Lorsque vous commencez à apprendre, la barre vous montrera la progression de l'apprentissage, comme la prédiction du temps d'apprentissage, le temps nécessaire pour apprendre chaque époque, la perte / l'exactitude des données d'entraînement, la perte / l'exactitude des données de validation (comme décrit ci-dessus). Pratique!).
Prévoir
Prédiction à l'aide des données d'entraînement
predicted = model.predict(X_test)
Cela se fait en utilisant predire () comme dans.
Dans cet exemple,
dataf = pd.DataFrame(predicted[:200])
dataf.columns = ["predict"]
dataf["input"] = y_test[:200]
dataf.plot(figsize=(15, 5))

Le résultat de la prédiction est le suivant.
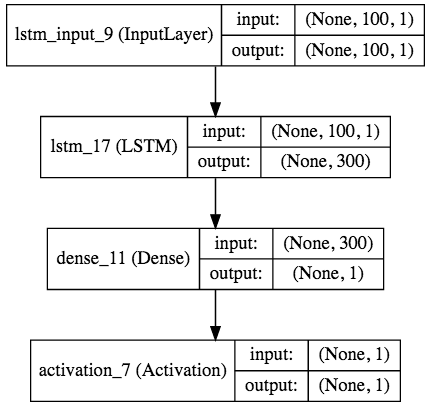
Keras prend également en charge la visualisation du modèle et vous pouvez facilement visualiser le modèle à l'aide de pygraphvis, etc. Depuis que j'utilisais jupyter cette fois, j'ai utilisé ʻIPython.display.SVG` et
from IPython.display import SVG
from keras.utils.visualize_util import model_to_dot, plot
SVG(model_to_dot(model, show_shapes=True).create(prog='dot', format='svg'))
En écrivant, le diagramme de modèle suivant sera généré (vous devez installer pydot avec pip et graphviz avec homebrew etc.).
en conclusion
Comme vous pouvez le voir, Keras vous permet d'écrire du code de modélisation de manière très concise. Je vais continuer à essayer des modèles plus compliqués utilisant Keras.
Les références
- Officiel de Keras (http://keras.io/) --Un dossier d'intelligence artificielle (http://aidiary.hatenablog.com/entry/20160328/1459174455)
- J'ai fait apprendre à RNN la vague du péché et j'ai fait une prédiction (http://qiita.com/yuyakato/items/ab38064ca215e8750865)
- Laissez Keras visualiser le modèle! !! (http://ket-30.hatenablog.com/entry/keras/graph)
Recommended Posts