Classification binar par arbre de décision par python ([High school information department information II] pédagogique pour la formation des enseignants)
introduction
Un arbre de décision est un graphique de la structure arborescente pour prendre des décisions dans le domaine de la théorie de la décision. Il existe une régression (arbre de régression) et une classification (arbre de classification) comme scènes où l'arbre de décision est utilisé, mais j'aimerais confirmer comment utiliser l'arbre de décision pour la classification. Plus précisément, je voudrais confirmer le mécanisme en implémentant en python ce qui est repris dans "Prédiction par classification" dans les supports de formation des enseignants d'Information II publiés sur la page du Ministère de l'Education, de la Culture, des Sports, des Sciences et de la Technologie. Je vais.
Matériel pédagogique
[Matériel de formation des enseignants du Département de l'information du lycée "Information II" (principal): Ministère de l'éducation, de la culture, des sports, de la science et de la technologie](https://www.mext.go.jp/a_menu/shotou/zyouhou/detail/mext_00742.html "Département de l'information du lycée Matériel pédagogique "Information II" pour la formation des enseignants (partie principale): Ministère de l'éducation, de la culture, des sports, des sciences et de la technologie ") Chapter 3 Information and Data Science Second Half (PDF: 7,6 Mo)
environnement
- ipython
- Colaboratory - Google Colab
Parties à reprendre dans le matériel pédagogique
Apprentissage 15 Prédiction par classification: "2. Classification binaire par arbre de décision"
J'aimerais voir comment cela fonctionne lors de l'implémentation du code source écrit en R en python.
Données traitées cette fois
Téléchargez les données titanesques de kaggle de la même manière que le matériel pédagogique. Cette fois, j'utiliserai "train.csv" de titanic.
https://www.kaggle.com/c/titanic/data
Ce sont les données qui décrivent la «survie / décès», «la qualité de la chambre», «sexe», «âge», etc. de certains passagers concernant l'accident du Titanic. Tout d'abord, je voudrais approfondir ma compréhension de l'arbre de décision en donnant un exemple d'implémentation dans lequel l'implémentation en R décrite dans le matériel pédagogique est ici remplacée par python.
Exemple d'implémentation et résultat en python
Chargement et prétraitement des données (python)
De train.csv, nous n'avons besoin que des informations sur Pclass (qualité de la chambre), sexe (sexe), âge (âge) et survécu (survie 1, décès 0), nous allons donc extraire uniquement les parties nécessaires. Les valeurs manquantes sont traitées comme «Non», et nous procéderons à la politique de suppression des valeurs manquantes.
Lecture des données originales, extraction des données, traitement des valeurs manquantes (code source)
import numpy as np
import pandas as pd
from IPython.display import display
from numpy import nan as NaN
titanic_train = pd.read_csv('/content/train.csv')
#Affichage des données d'origine
display(titanic_train)
# Pclass(Catégorie de la pièce)、Sex(sexe)、Age(âge)、Survived(Survie 1,Décès 0)
titanic_data = titanic_train[['Pclass', 'Sex', 'Age', 'Survived']]
display(titanic_data)
#Valeur manquante'NaN'Se débarrasser de
titanic_data = titanic_data.dropna()
display(titanic_data)
#Vérifiez les données pour voir si les valeurs manquantes ont été supprimées
titanic_data.isnull().sum()
Lecture des données originales, extraction des données, traitement des valeurs manquantes (résultat de sortie)
Lire les données originales

Extraction de données

Résultat de données de traitement de valeur manquante

Vérifiez les données pour voir si les valeurs manquantes ont été supprimées

Exécution de la visualisation de l'arbre de décision (code source)
Je vais utiliser dtreeviz pour visualiser l'arbre de décision avec python car c'est facile à voir.
installation de dtreeviz
!pip install dtreeviz pydotplus
Visualisation des arbres de décision
import sklearn.tree as tree
from dtreeviz.trees import dtreeviz
##Convertir un homme en 0 et une femme en 1
titanic_data["Sex"] = titanic_data["Sex"].map({"male":0,"female":1})
# 'Survived'Matrice caractéristique avec données regardant à travers les colonnes
# 'Survived'Variable objective pour les colonnes
X_train = titanic_data.drop('Survived', axis=1)
Y_train = titanic_data['Survived']
#Créer un arbre de décision (la profondeur maximale de l'arbre est spécifiée comme 3)
clf = tree.DecisionTreeClassifier(random_state=0, max_depth = 3)
model = clf.fit(X_train, Y_train)
viz = dtreeviz(
model,
X_train,
Y_train,
target_name = 'alive',
feature_names = X_train.columns,
class_names = ['Dead','Sruvived']
)
#Affichage de l'arbre de décision
display(viz)
Exécution de la visualisation de l'arbre de décision (sortie)

Dans l'analyse de l'arbre de décision, il est nécessaire de considérer à quelle profondeur l'arbre doit être analysé. Si l'arbre de décision n'est pas arrêté à une profondeur appropriée, il peut se produire un surajustement qui surpasse les données d'apprentissage utilisées pour l'analyse, et les performances de généralisation peuvent se détériorer. En raison de l'affichage cette fois, la profondeur maximale est spécifiée comme 3, donc elle n'est pas réglée trop profondément, mais dans le matériel didactique, un paramètre de complexité modérée est spécifié et l'arbre est élagué. Je fais (taille), donc je voudrais procéder de la même manière.
taille
Quand on regarde dans quelle mesure le branchement conditionnel de chaque nœud de l'arbre de décision est fait, un paramètre appelé impureté est souvent utilisé, et plus ce paramètre est petit, plus la norme est simple. Indique que la classification est terminée. Un autre facteur important impliqué est le paramètre de complexité, qui indique la complexité de l'arbre entier. Dans ce code source, l'impureté au moment de la génération de l'arbre de décision est appelée impureté de Gini. (DecisionTreeClassifier () argument critère {“gini”, “entropy”}, default = ”gini”) Et, comme méthode de génération de l'arbre de décision, nous utilisons un algorithme appelé élagage à coût-complexité minimale. Il s'agit d'un algorithme qui génère un arbre de décision qui minimise le coût de génération de l'arbre (nombre de nœuds à la fin de l'arbre x complexité de l'arbre + impureté de l'arbre), comme on l'appelle élagage de complexité à coût minimum. Lorsque la complexité est élevée, le nombre de nœuds de terminaison a une forte influence sur le coût de génération de l'arbre, et lors de la génération de l'arbre déterminé par l'élagage de complexité de coût minimum, un arbre plus petit (profondeur et nombre de nœuds plus petits) est généré. Je peux le faire. Inversement, lorsque la complexité est faible, l'effet du coût de génération d'arbre sur le nombre de nœuds terminaux est faible, et lors de la génération d'un arbre de décision également, un arbre grand et complexe (faible profondeur et nombre de nœuds) peut être généré.
J'ai parlé d'une image approximative sans utiliser de formules mathématiques, mais il existe de nombreux documents officiels et autres sites qui expliquent en détail, donc ce peut être une bonne idée de regarder de plus près. [Référence] https://scikit-learn.org/stable/modules/tree.html#minimal-cost-complexity-pruning
Taille (code source)
Relation entre les paramètres liés à la complexité et les paramètres liés à l'impureté
import matplotlib.pyplot as plt
#Créer un arbre de décision (aucune profondeur maximale d'arbre spécifiée)
clf = tree.DecisionTreeClassifier(random_state=0)
model = clf.fit(X_train, Y_train)
path = clf.cost_complexity_pruning_path(X_train, Y_train)
# ccp_alphas:Paramètres liés à la complexité
# impurities:Paramètres liés à l'impureté
ccp_alphas, impurities = path.ccp_alphas, path.impurities
fig, ax = plt.subplots()
ax.plot(ccp_alphas[:-1], impurities[:-1], marker='o', drawstyle="steps-post")
ax.set_xlabel("effective alpha")
ax.set_ylabel("total impurity of leaves")
ax.set_title("Total Impurity vs effective alpha for training set")
Relation entre les paramètres de complexité et le nombre de nœuds générés et la profondeur de l'arbre
clfs = []
for ccp_alpha in ccp_alphas:
clf = tree.DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
clf.fit(X_train, Y_train)
clfs.append(clf)
print("Number of nodes in the last tree is: {} with ccp_alpha: {}".format(
clfs[-1].tree_.node_count, ccp_alphas[-1]))
clfs = clfs[:-1]
ccp_alphas = ccp_alphas[:-1]
node_counts = [clf.tree_.node_count for clf in clfs]
depth = [clf.tree_.max_depth for clf in clfs]
fig, ax = plt.subplots(2, 1)
ax[0].plot(ccp_alphas, node_counts, marker='o', drawstyle="steps-post")
ax[0].set_xlabel("alpha")
ax[0].set_ylabel("number of nodes")
ax[0].set_title("Number of nodes vs alpha")
ax[1].plot(ccp_alphas, depth, marker='o', drawstyle="steps-post")
ax[1].set_xlabel("alpha")
ax[1].set_ylabel("depth of tree")
ax[1].set_title("Depth vs alpha")
fig.tight_layout()
Élagage (résultat de sortie)
Relation entre les paramètres liés à la complexité et les paramètres liés à l'impureté

Relation entre les paramètres de complexité et le nombre de nœuds générés et la profondeur de l'arbre

Dans le matériel pédagogique, l'arbre est élagué à une profondeur d'environ 1 à 2, donc si le paramètre de complexité ccp_alpha est d'environ 0,041, la profondeur est de 1, le nombre de nœuds est d'environ 1, et si ccp_alpha est d'environ 0,0151, il est profond. Vous pouvez voir qu'il s'agit probablement d'environ 2 et 3 nœuds.
Déterminer l'arbre après l'élagage (code source)
ccp_alpha=0.041
clf = tree.DecisionTreeClassifier(ccp_alpha = 0.041)
model = clf.fit(X_train, Y_train)
viz = dtreeviz(
model,
X_train,
Y_train,
target_name = 'alive',
feature_names = X_train.columns,
class_names = ['Dead','Sruvived']
)
display(viz)
ccp_alpha=0.0151
clf = tree.DecisionTreeClassifier(ccp_alpha = 0.0151)
model = clf.fit(X_train, Y_train)
viz = dtreeviz(
model,
X_train,
Y_train,
target_name = 'alive',
feature_names = X_train.columns,
class_names = ['Dead','Sruvived']
)
display(viz)
Arbre de décision après élagage (résultat de sortie)
ccp_alpha=0.041

ccp_alpha=0.0151

En regardant ces derniers, nous pouvons voir que le plus grand facteur qui sépare la vie et la mort est le sexe, et les femmes étaient plus susceptibles d'être sauvées. Même pour les hommes, plus ils sont jeunes (= enfants), plus le taux de survie est élevé. Pour les femmes, plus la note de la chambre est élevée, plus le taux de survie est élevé.
commentaire
Le matériel didactique a la description suivante.
La vie ou la mort de cet accident Le sexe est le principal facteur déterminant la vie ou la mort de cet accident. On peut également lire que l'équipage a activement sauvé des femmes et des enfants. De plus, la supériorité ou l'infériorité de la cabine ne semble pas être un facteur déterminant la vie ou la mort.
À la suite de la mise en œuvre et de la production par moi-même, il semblait que *** la supériorité ou l'infériorité de la cabine était également un facteur déterminant la vie ou la mort ***. La composition de l'arbre de décision était la même qu'il s'agisse de python ou de R, il est donc important non seulement de regarder les résultats du matériel pédagogique, mais de l'exécuter et de l'analyser à votre manière. J'ai pensé.
[Référence] Exemple de mise en œuvre et résultats en R (à partir du matériel didactique)
Lecture et prétraitement des données (R)
Lecture des données originales (code source)
titanic.train<-read.csv("/content/train.csv") #Spécifiez l'emplacement des données str(titanic.train)
### Lecture des données originales (résultat de sortie)
> ```console
'data.frame': 891 obs. of 12 variables:
$ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ...
$ Survived : int 0 1 1 1 0 0 0 0 1 1 ...
$ Pclass : int 3 1 3 1 3 3 1 3 3 2 ...
$ Name : Factor w/ 891 levels "Abbing, Mr. Anthony",..: 109 191 358 277 16 559 520 629 417 581 ...
$ Sex : Factor w/ 2 levels "female","male": 2 1 1 1 2 2 2 2 1 1 ...
$ Age : num 22 38 26 35 35 NA 54 2 27 14 ...
$ SibSp : int 1 1 0 1 0 0 0 3 0 1 ...
$ Parch : int 0 0 0 0 0 0 0 1 2 0 ...
$ Ticket : Factor w/ 681 levels "110152","110413",..: 524 597 670 50 473 276 86 396 345 133 ...
$ Fare : num 7.25 71.28 7.92 53.1 8.05 ...
$ Cabin : Factor w/ 148 levels "","A10","A14",..: 1 83 1 57 1 1 131 1 1 1 ...
$ Embarked : Factor w/ 4 levels "","C","Q","S": 4 2 4 4 4 3 4 4 4 2 ...
Extraction de données (code source)
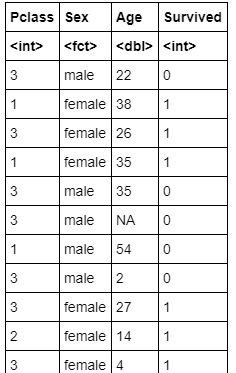
titanic.data<-titanic.train[,c("Pclass","Sex","Age","Survived")] titanic.data
### Extraction de données (résultat de sortie)
> 
### Valeur manquante (NA) (code source)
> ```R
titanic.data<-na.omit(titanic.data)
Exécution de la visualisation de l'arbre de décision (code source)
install.packages("partykit") library(rpart) library(partykit) titanic.ct<-rpart(Survived~.,data=titanic.data, method="class") plot(as.party(titanic.ct),tp_arg=T)
### Exécution de la visualisation de l'arbre de décision (résultat de sortie)
> <img width = "480" alt = "Télécharger (12) .png " src = "https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/677025/4c8bf0fc-369b -137d-21b4-4c41e77c0741.png ">
### Arbre de classification CP (code source)
> ```R
printcp(titanic.ct)
Arbre de classification CP (résultat de sortie)
Classification tree: rpart(formula = Survived ~ ., data = titanic.data, method = "class")
Variables actually used in tree construction: [1] Age Pclass Sex
Root node error: 290/714 = 0.40616
n= 714
CP nsplit rel error xerror xstd
1 0.458621 0 1.00000 1.00000 0.045252 2 0.027586 1 0.54138 0.54138 0.038162 3 0.012069 3 0.48621 0.53793 0.038074 4 0.010345 5 0.46207 0.53448 0.037986 5 0.010000 6 0.45172 0.53793 0.038074
### Arbre de classification (code source) lorsque CP est défini sur 0,028
> ```R
titanic.ct2<-rpart(Survived~.,data=titanic.data, method="class", cp=0.028)
plot(as.party(titanic.ct2))
Exécution de la visualisation de l'arbre de décision (résultat de sortie)

Arbre de classification (code source) lorsque CP vaut 0,027
titanic.ct3<-rpart(Survived~.,data=titanic.data, method="class", cp=0.027) plot(as.party(titanic.ct3))
### Exécution de la visualisation de l'arbre de décision (résultat de sortie)
> <img width = "480" alt = "Télécharger (14) .png " src = "https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/677025/74101e1b-623e -94c1-40a5-8a700a5e7ec2.png ">
# Code source
version python
https://gist.github.com/ereyester/dfb4fd6fb3e58c5d0539866f7e2622b4
Version R
https://gist.github.com/ereyester/182d5d49ea04be579da2ffc82412a82a
Recommended Posts