Manipulation des données Kintone avec le pilote ODBC Python & C Data d'AWS Lambda
introduction
Aperçu
Il s'agit de la procédure pour appeler du code Python à partir du service sans serveur AWS Lambda et gérer les données dans l'application kintone à l'aide du pilote ODBC CData.
Diagramme

Produits et services utilisés
・ AWS Lambda ・ "Kintone" (https: //kintone.cybozu.kom/jp/) ・ Pilote ODBC CData kintone pour Linux
- Depuis le 20 août 2017, la version bêta de kinton peut être téléchargée depuis ici. Les pilotes ODBC pour d'autres sources de données peuvent être téléchargés depuis ici ・ Pyodbc ・ RHEL5.7 (pour extraire la bibliothèque pyodbc)
Exemple de code
https://github.com/kuwazzy/pycdatakintonedemo
référence
Préparation du package de fonctions Lambda
Préparation du pilote ODBC CData kintone
Accédez à la page Web du logiciel CData. La version d'évaluation et la version produit du pilote ODBC CData kintone peuvent être téléchargées depuis ici. Cependant, depuis le 20 août 2017, la version Linux est disponible en version bêta, veuillez donc la télécharger depuis ici. Veuillez consulter ici pour le manuel du produit.
Extraction de bibliothèques à partir du pilote ODBC CData kintone pour Linux
Décompressez le fichier de construction setup.x86_64.deb. Lorsque vous le décompressez, data.tar sera créé, alors décompressez-le davantage. Ensuite, un répertoire de données avec la structure suivante est créé.
data/ ├ opt/ | └ cdata/ | └ cdata-odbc-driver-for-kintone/ | ├ bin/ | ├ db/ | ├ demos/ | ├ etc/ | ├ help/ | └ lib/ | ├ cdata.odbc.kintone.ini | ├ CData.ODBCm.Kintone.DLL | ├ libcdatart.x64.so.4 | └ libkintoneodbc.x64.so └ usr/ └ doc/ └ cdata-odbc-driver-for-kintone/
Extrayez 4 fichiers sous / data / opt / cdata / cdata-odbc-driver-for-kintone / lib.
Préparation de pyodbc et des bibliothèques dépendantes
Préparez la bibliothèque pyodbc.so. Dans mon environnement, je l'ai copié depuis /usr/lib64/python2.7/site-packages de RHEL7.3.
De plus, préparez un groupe de bibliothèques dépendantes de pyodbc. Dans mon environnement, je l'ai copié depuis / usr / lib64 sous RHEL7.3.
Liste des bibliothèques dépendantes ajoutées
libodbc.so libodbc.so.2 libodbccr.so libodbccr.so.2 libodbcdrvcfg1S.so libodbcdrvcfg1S.so.2 libodbcdrvcfg2S.so libodbcdrvcfg2S.so.2 libodbcinst.so libodbcinst.so.2 libodbcminiS.so libodbcminiS.so.2 libodbcmyS.so libodbcmyS.so.2 libodbcnnS.so libodbcnnS.so.2 libodbcpsqlS.so libodbcpsqlS.so.2 libodbctxtS.so libodbctxtS.so.2 libomapi.so.0 liboplodbcS.so liboplodbcS.so.2 liboraodbcS.so liboraodbcS.so.2
Préparation du code Python
Obtenez-le sur GitHub ici.
pycdatakintonedemo.py
# -*- coding: utf-8 -*-
import pyodbc
import sys
def Main(event, context):
print('************************************************')
print('\t\t Kintone Demo')
print('This demo uses the CData ODBC for Kintone')
print('************************************************')
print('option:1, - List all the tables in the database')
print('option:2, table:name - List all the columns for a specific table')
print('option:3, table:name - Select data from table')
print('option:4, sql:statement - Custom SQL Query')
print('------------------------------------------------')
connStr = 'Driver={./cdata/libkintoneodbc.x64.so};' + event['conn_str']
conn = pyodbc.connect(connStr)
if event['option'] == '1':
for table in conn.cursor().tables():
print(table.table_name)
elif event['option'] == '2':
tableName = event['table']
for column in conn.cursor().columns(tableName):
print(column.column_name)
elif event['option'] == '3':
tableName = event['table']
c = conn.cursor();
c.execute('SELECT * FROM ' + tableName)
for row in c.fetchall():
print(row)
elif event['option'] == '4':
sql = event['sql']
c = conn.cursor();
c.execute(sql)
for row in c.fetchall():
print(row)
else:
print('Invalid option')
conn.close();
return {
'status' : 'finish'
}
La mise en garde est que la bibliothèque ODBC est spécifiée directement au lieu du DSN. J'ai fait référence à la page ici.
connStr = 'Driver={./cdata/libkintoneodbc.x64.so};' + event['conn_str']
Créer un package de fonctions
Préparez les fichiers préparés dans la procédure ci-dessus avec la structure de répertoires suivante. . ├ pycdatakintonedemo.py (code Python appelé depuis Lambda) ├ pyodbc.so (bibliothèque pyodbc) ├ cdata / (bibliothèque CData) | ├ cdata.odbc.kintone.ini | ├ CData.ODBCm.Kintone.DLL | ├ libcdatart.x64.so (renommé libcdatart.x64.so.4) | └ libkintoneodbc.x64.so └ lib/ └ libodbc * .so etc (bibliothèques dépendantes de pyodbc)
Ce groupe de fichiers est compressé. * Veuillez ne pas inclure le répertoire parent
Créer une fonction Lambda
Créer une fonction
Cliquez sur le bouton "Créer une fonction" sur l'écran du tableau de bord AWS Lambda.
 Cliquez sur le bouton «Créer à partir de zéro» sur l 'écran de sélection du dessin de conception à l' étape 1.
Cliquez sur le bouton «Créer à partir de zéro» sur l 'écran de sélection du dessin de conception à l' étape 1.
 Puisqu'il n'est pas réglé cette fois sur l'écran de réglage du déclencheur à l'étape 2, cliquez sur le bouton «Suivant».
Puisqu'il n'est pas réglé cette fois sur l'écran de réglage du déclencheur à l'étape 2, cliquez sur le bouton «Suivant».
 Entrez le nom de la fonction (facultatif) et la description (facultative) sur l'écran de configuration de la fonction à l'étape 3, et sélectionnez «Python 2.7» comme moteur d'exécution.
Entrez le nom de la fonction (facultatif) et la description (facultative) sur l'écran de configuration de la fonction à l'étape 3, et sélectionnez «Python 2.7» comme moteur d'exécution.
 Dans le code de la fonction Lambda, sélectionnez le type d'entrée de code "Télécharger un fichier .ZIP" et téléchargez le fichier ZIP créé dans la procédure "Créer un package de fonctions".
Dans le code de la fonction Lambda, sélectionnez le type d'entrée de code "Télécharger un fichier .ZIP" et téléchargez le fichier ZIP créé dans la procédure "Créer un package de fonctions".
 Pour les gestionnaires de fonctions et les rôles Lambda, définissez le nom du fichier (exemple: pycdatakintonedemo) en excluant l'extension du code Python téléchargé depuis GitHub et le nom du gestionnaire (exemple: Main) connecté par des points.
Pour les gestionnaires de fonctions et les rôles Lambda, définissez le nom du fichier (exemple: pycdatakintonedemo) en excluant l'extension du code Python téléchargé depuis GitHub et le nom du gestionnaire (exemple: Main) connecté par des points.
 Dans les paramètres avancés, définissez le délai d'expiration sur une valeur appropriée (exemple: 1 minute).
Dans les paramètres avancés, définissez le délai d'expiration sur une valeur appropriée (exemple: 1 minute).

Après avoir terminé les paramètres jusqu'à présent, cliquez sur le bouton "Suivant" en bas, et s'il n'y a pas de problèmes sur l'écran de confirmation, cliquez sur le bouton "Créer une fonction".
 Confirmez que la fonction a été créée.
Confirmez que la fonction a été créée.

Exécution de la fonction Lambda
Créer un événement de test
Dans Actions, sélectionnez Définir un événement de test.

L'exemple de modèle d'événement reste HelloWorld et définit les valeurs des quatre paramètres.
sample.json
{
"conn_str": "Url=https://***.cybozu.com;User=***;Password=***;",
"option": "1",
"table": "table_name",
"sql": "SELECT * FROM table_name"
}
"Conn_str" est la chaîne de connexion à kintone. Au minimum, vous aurez besoin de trois éléments: URL, utilisateur et mot de passe. Il y a quatre «options» ci-dessous. Pour quelques-uns, spécifiez également «table». Dans le cas de 4, spécifiez également "sql".
・ Option: 1, - Répertorier toutes les tables de la base de données ' ・ Option: 2, table: nom - Répertorie toutes les colonnes d'une table spécifique ' ・ Option: 3, table: nom --Sélectionnez les données de la table ' · Option: 4, sql: instruction - Requête SQL personnalisée '

Essai
Cliquez maintenant sur le bouton "Test" pour l'exécuter.

C'est OK si "Success" est affiché dans le résultat de l'exécution. Cliquez sur "Détails" et cliquez sur "Cliquez ici" dans la sortie du journal pour voir le journal dans CloudWatch. Si une erreur se produit, vérifiez le contenu du journal.
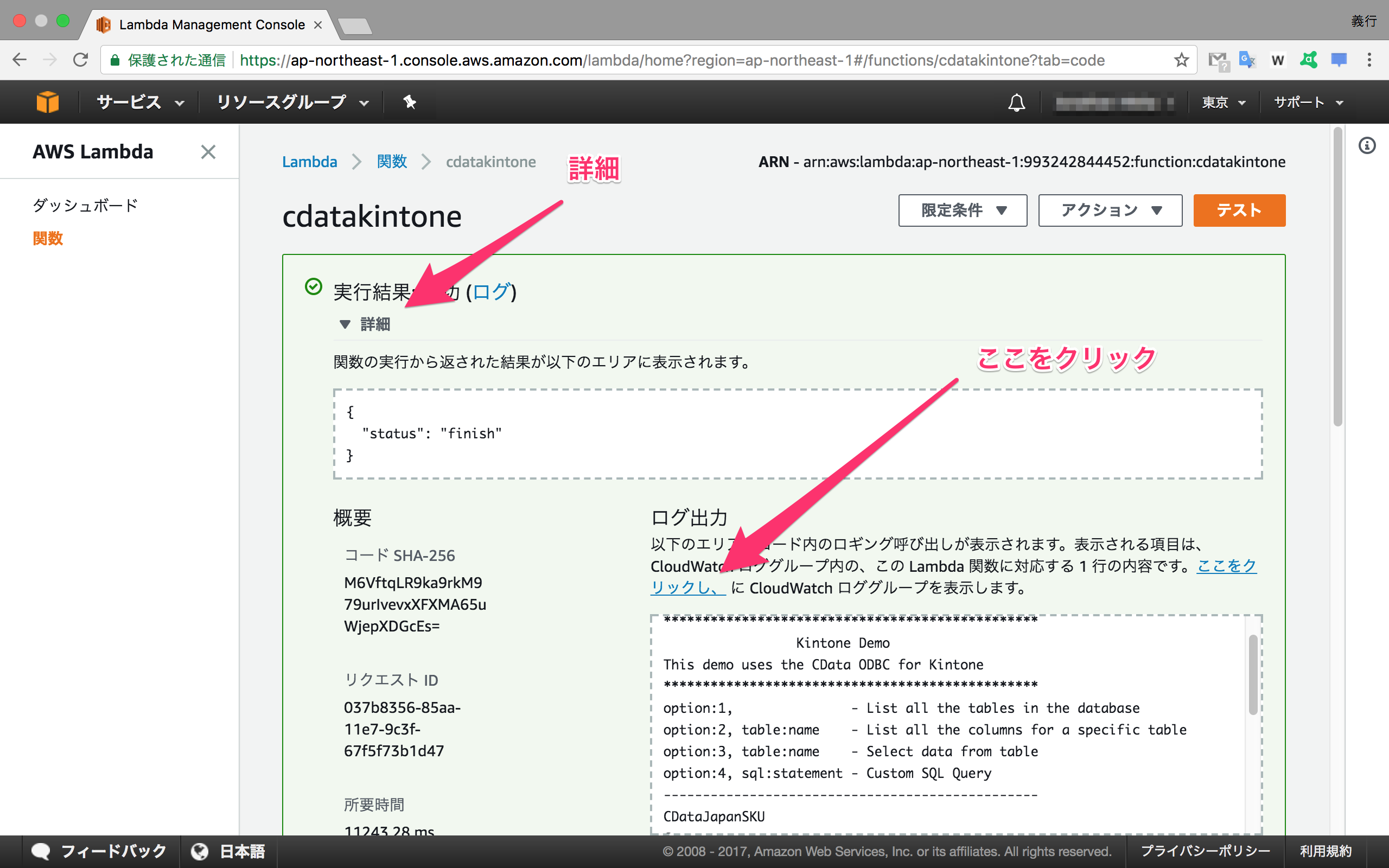
Si vous sélectionnez le flux de journal et regardez le contenu du message, vous pouvez voir que la liste des applications dans kintone est sortie.

Ensuite, ouvrez un événement de test, définissez "3" (affichage des données de la table) dans "option", définissez le nom de l'application (exemple: CDataJapanSKU) existant dans kintone dans "table", et "save" Cliquez sur Test.

Si vous ouvrez à nouveau le journal dans CloudWatch, vous pouvez voir que les données de l'application kintone (par exemple les données produit dans CDataJapanSKU) sont affichées.

Résumé
Il s'agissait d'une procédure d'intégration kintone par Python à partir d'AWS Lambda à l'aide du pilote ODBC CData. En plus de kintone, le pilote ODBC CData peut se connecter à plus de 90 Saas, applications et bases de données. Veuillez télécharger et essayer différents pilotes ODBC à partir de la page Web ici.
Recommended Posts