Création d'une application interactive à l'aide d'un modèle de rubrique
Je veux guérir mes yeux avec Blue Ocean plutôt que de me brûler les yeux avec Blue Light.
2015 touche à sa fin, mais comment allez-vous tous? Je veux revenir à la nature vers la fin de l'année, donc cette fois je vais vous présenter comment créer une application qui fait des propositions de voyage interactives à l'aide d'un modèle thématique.
Cet article est un article sœur de la publication précédente Création d'une application à l'aide du modèle de rubrique. À ce moment-là, la création de l'application ne rattrapait pas son retard, et bien qu'il ait été qualifié de "création de l'application", la création de l'application n'était pas terminée, le contenu la complète donc. Je ne parlerai pas du modèle du sujet lui-même cette fois, donc si vous êtes intéressé, veuillez vous référer à l'article ci-dessus.
Qu'est-ce qu'un modèle de sujet?
Je laisserai l'explication détaillée à ici, mais le modèle de sujet consiste à classer les documents par sujet comme son nom l'indique. C'est une méthode de. Plus précisément, le "sujet" ici a l'image suivante.
Il s'agit d'un nuage de mots créé à partir d'un blog de voyage. Un «sujet» est donc composé de mots, et certains des mots sont fréquents et d'autres non. L'estimation de la distribution de probabilité qui définit le «mot d'apparence» et la «probabilité d'apparence» est l'objectif principal du modèle thématique. Si cette distribution de probabilité est clarifiée, il sera possible de classer des documents avec des distributions similaires, et il sera également possible d'estimer le degré de pertinence entre les documents à partir de la distance entre les distributions.
Application aux applications interactives
Les sujets peuvent être représentés par des distributions de probabilité comme décrit ci-dessus, de sorte que la distance entre les distributions puisse être calculée (cette fois j'ai utilisé KL-divergence). En utilisant cette distance, essayez de proposer un emplacement pour le sujet A, et si la réponse est Non, proposez un sujet éloigné (sujet B, qui est le plus éloigné de la figure), et implémentez-le avec une politique simple. Je vais essayer.
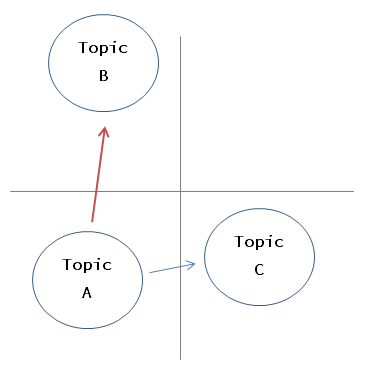
Mise en place d'une application interactive
L'application implémentée cette fois est ici.
Je suggère environ 3 candidats du même sujet, qui peuvent être commutés avec la flèche ci-dessous. S'il y a quelque chose que vous aimez / différent dans l'image, vous pouvez l'évaluer avec le bouton Bon / Mauvais ci-dessous. Recevez des évaluations et faites des suggestions pour des sujets similaires / éloignés.

Puisqu'il a un bouton Heroku, il peut être déployé dans votre environnement Heroku. Essayez-le avec le modèle de sujet que j'ai créé! C'est tout à fait possible. En tant que données, l'API de AB-ROAD est utilisée, et vous devez vous inscrire ici.
Implémentation de l'application
La configuration de l'application est la suivante.

- ʻApplication`: implémentation de l'application Web
data: stocke le fichier de modèle entraîné. Comme il était gênant d'utiliser la base de données, les données ponctuelles sont également incluses cette fois, mais à l'origine elles seront rejetées avec ignorer.pola: contient le modèle de sujet et l'implémentation du dialogue l'utilisant.polaest le nom du moteur qui mène ce" dialogue en utilisant le modèle de sujet "(j'ai choisi un nom semblable à un étranger car il s'agit d'un voyage à l'étranger).scripts: divers scripts pour l'extraction, le formatage et la formation des donnéestests: code de test
Dans la composition, j'ai prêté attention aux points suivants.
- ** Mise en œuvre d'application distincte et implémentation d'apprentissage automatique ** (séparation de ʻapplication
etpola`) Lors d'un développement avec plusieurs équipes, il est fort probable que ces responsabilités soient séparées, et je pense qu'il est préférable de les séparer en termes d'augmentation de la portabilité de la partie apprentissage automatique. - ** Extraction / mise en forme des données séparées et implémentation du modèle d'apprentissage automatique ** (séparation des scripts
polaet`) La mise en œuvre de la partie machine learning est principalement divisée entre le code lié à "l'extraction / mise en forme de données" et la partie "modèle d'apprentissage machine". Et le premier dépend souvent vraiment des données à traiter, et si cela est incorporé dans la «mise en œuvre d'un modèle d'apprentissage automatique», le modèle lui-même devient une source de données et beaucoup de gens, donc c'est séparé. Je pense qu'il est souhaitable d'abstraire la partie du modèle d'apprentissage automatique dans une certaine mesure, par exemple "applicable si les données sont entrées dans ce format". - ** Séparation des fichiers de modèles entraînés et mise en œuvre de l'apprentissage automatique ** (
polaetdata) Puisque la modification du modèle d'apprentissage automatique lui-même (modification de l'algorithme, etc.) et la mise à jour du modèle entraîné qui est le résultat d'apprentissage devraient être différentes, cette fois nous séparons explicitement les deux. Bien sûr, je pense qu'il y a aussi l'idée de gérer avec un modèle formé inclus.
Ensuite, comme l'application, écrivez le code de test exactement pour le modèle d'apprentissage automatique et joignez le document avec le bloc-notes iPython pour le modèle d'apprentissage automatique.
Les hypothèses de construction et la vérification du modèle de rubrique construit cette fois peuvent être référencées à partir du bloc-notes iPython suivant.
enigma_abroad/pola/machine/topic_model_evaluation.ipynb
Construire un modèle de sujet
Bien entendu, lors d'une proposition, il est essentiel de construire un modèle thématique, qui est le cerveau de l'application.
Cette fois, comme l'article sœur Créer une application à l'aide du modèle de sélection, [gensim]( Je l'ai construit en utilisant https://radimrehurek.com/gensim/) (j'ai également essayé d'utiliser pymc, mais il a été scellé car la mémoire a été perdue à cause de l'apprentissage). Et malheureusement, la précision n'était pas aussi bonne qu'elle l'était ... mais je vais continuer ici.
De plus, lorsqu'il s'agit d'utiliser réellement le machine learning dans une application, il est peu probable que "précision 99% ou!" Comme le tutoriel, et même s'il y en a, c'est soit une illusion due au surapprentissage, soit un bug créé par soi-même. C'est souvent le cas.
Pour surmonter cela, une collecte de données régulière et un prétraitement régulier des données sont nécessaires. Ah ... quand j'ai parlé de ce qui s'est passé, j'essayais de faire quelque chose de cool avec l'apprentissage automatique, mais avant de le savoir, je définissais méticuleusement les mots à exclure du corpus ... ・. Les recommandations basées sur le contenu comme le modèle thématique ont l'avantage de pouvoir faire des recommandations même lorsque les données d'évaluation des utilisateurs sont irrésistibles, par rapport au co-filtrage, qui est souvent utilisé pour les recommandations, mais après tout, la quantité de contenu et sa mise en forme doivent être faites correctement. Cela ne fonctionne pas bien (il y a plusieurs documents, mais j'ai l'impression que le volume d'un seul document doit être correct).
Considération
Bien qu'il ait été transformé en application, le modèle de sujet essentiel n'a pas été bien construit. La dernière fois, j'ai traité différentes données du salon de coiffure et cette fois du plan de voyage, mais toutes se sont retrouvées avec des résultats tristes que les sujets ne pouvaient pas être bien classés.
Je pense que la cause en est le problème des données.
- Nombre de mots par document: s'il n'est pas assez long, seuls quelques mots-clés apparaîtront, ce qui n'est pas si différent des autres mots. En conséquence, il devient difficile de déterminer de quel sujet il s'agit et cela affecte également le nombre total de mots.
- Différence de sujet claire: tous sont des documents dans les catégories existantes telles que "salon de coiffure" et "plan de voyage", il n'y a donc pas beaucoup de différence dans les mots qui apparaissent.
Bref, je pense qu'il est souhaitable de l'appliquer dans une situation où il existe diverses variantes de documents et chacune est raisonnablement longue. Si vous souhaitez faire des classifications plus détaillées dans la même catégorie, je pense que vous devez acquérir des connaissances préalables.
- Construisez un modèle de sujet avec des connaissances préalables: construisez un groupe de mots à l'avance à partir de Wikipédia, etc. («mer» et «plage» sont le même groupe, etc.), et construisez un modèle de sujet basé sur le groupe de mots au lieu des mots eux-mêmes. Faire. En faisant cela, il est possible d'assembler des fluctuations de notation et des mots de consensus, et il devient plus facile de trouver des sujets même si la quantité de documents est faible.
- Apprendre le sens des mots: les humains peuvent reconnaître les mots «mer» et «plage» comme parlant de la mer, même si la fréquence est une fois. On peut dire que le sujet est considéré par sa signification et les mots associés, non par la fréquence d'occurrence du mot. Puisque ces quantités de caractéristiques peuvent être vectorisées simplement en utilisant word2vec etc., la quantité vectorielle de chaque document est calculée sur la base du modèle entraîné à l'avance, et la classification est effectuée sur cette base.
Je pense qu'il y a beaucoup d'autres idées, alors essayez de créer votre propre modèle et de créer une application qui vous mènera à Blue Ocean.

Recommended Posts