[JAVA] Introduction à Apache Beam (2) ~ ParDo ~
Idée générale
Créez un programme Apache Beam simple pour comprendre son fonctionnement
Contenu précédent
Le texte lu a été écrit tel quel pour confirmer le démarrage. Introduction à Apache Beam (1) ~ Lecture et écriture de texte ~
But de cette fois
Modifiez le type de données en effectuant un traitement ParDo pour chaque ligne de texte lu Plus précisément, le processus de «lecture des informations de ticker Bitcoin à partir de données textuelles et d'en extraire une valeur arbitraire» est effectué.
Qu'est-ce que ParDo en premier lieu?
Core Beam Transforms Beam fournit les 6 suivantes comme variantes de données de base (comme un aperçu général du traitement)
- ParDo (je ferai cette fois)
- GroupByKey
- CoGroupByKey
- Combine
- Flatten
- Partition
L'un d'eux est ParDo
Quel type de traitement?
- Responsable de la partie Map de l'algorithme MapReduce
- Traiter la PCollection reçue comme entrée
- Sortie 0 ou 1 ou plusieurs PCollections
En bref, le processus de traitement des données d'entrée (1 pièce) et de leur sortie (quel que soit le nombre)
Histoire principale
environnement
Le meme que la derniere fois
IntelliJ
IntelliJ IDEA 2017.3.3 (Ultimate Edition)
Build #IU-173.4301.25, built on January 16, 2018
Licensed to kaito iwatsuki
Subscription is active until January 24, 2019
For educational use only.
JRE: 1.8.0_152-release-1024-b11 x86_64
JVM: OpenJDK 64-Bit Server VM by JetBrains s.r.o
Mac OS X 10.12.6
Maven : 3.5.2
procédure
Données textuelles à utiliser
Les données utilisées sont les suivantes Les informations de taux BTC / JPY dans bitflyer sont acquises toutes les 10 secondes pendant 10 fois.
L'ordre est «
Sample.txt
BTC/JPY,bitflyer,1519845731987,1127174.0,1126166.0
BTC/JPY,bitflyer,1519845742363,1127470.0,1126176.0
BTC/JPY,bitflyer,1519845752427,1127601.0,1126227.0
BTC/JPY,bitflyer,1519845762038,1127591.0,1126316.0
BTC/JPY,bitflyer,1519845772637,1127801.0,1126368.0
BTC/JPY,bitflyer,1519845782073,1126990.0,1126411.0
BTC/JPY,bitflyer,1519845792827,1127990.0,1126457.0
BTC/JPY,bitflyer,1519845802008,1127980.0,1126500.0
BTC/JPY,bitflyer,1519845812088,1127980.0,1126566.0
BTC/JPY,bitflyer,1519845822743,1127970.0,1126601.0
Lisez ce texte et utilisez ParDo pour extraire des informations arbitraires («BID» cette fois) de chaque ligne.
Changement de code
Le code cette fois est le suivant.
SimpleBeam.java
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.values.PCollection;
public class SimpleBeam {
//ajouter à
public static class ExtractBid extends DoFn<String, String> {
@ProcessElement
public void process(ProcessContext c){
//Obtenir la ligne
String row = c.element();
//Séparer par une virgule
String[] cells = row.split(",");
//Renvoie BID
c.output(cells[4]);
}
}
public static void main(String[] args){
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
//Lire le texte
PCollection<String> textData = p.apply(TextIO.read().from("Sample.txt"));
//Ajouté à partir d'ici
PCollection<String> BidData = textData.apply(ParDo.of(new ExtractBid()));
//Ajouter ici
//Rédaction de texte
BidData.apply(TextIO.write().to("output/bid"));
//Pipeline run
p.run().waitUntilFinish();
}
}
La sortie du code précédent était "word count" et je savais que j'avais copié et collé l'échantillon, donc j'ai changé la destination de sortie. .. ..
La méthode d'exécution est la même que la dernière fois, veuillez donc vous référer à ici.
Résultat d'exécution
Le résultat de l'exécution est le suivant, et vous pouvez voir que les données BID (à l'extrême droite de Sample.txt) ont été extraites.
Cette fois, par souci de simplicité, une seule chaîne est extraite, mais cela vous permet de modifier le type de données et de formater les données.
Avec ce type de traitement, vous pouvez définir une clé arbitraire pour les données d'entrée et passer au traitement Réduire.
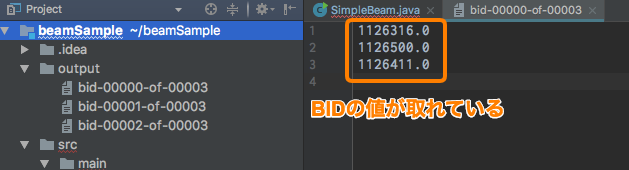
La sortie est-elle divisée en trois fichiers comme l'image parce que le processus de mappage est terminé, puis Réduire est distribué et exécuté?
À propos de SimpleFunction
Une classe appelée «SimpleFinction» est prête à réaliser le même traitement, et j'étais curieux de savoir ce qui était différent, donc je vais le résumer en bonus.
Selon le Document officiel,
If your ParDo performs a one-to-one mapping of input elements to output elements–that is, for each input element, it applies a function that produces exactly one output element, you can use the higher-level MapElements transform. MapElements can accept an anonymous Java 8 lambda function for additional brevity.
Cela ressemble à une histoire que vous pouvez décrire le traitement de manière plus abstraite et plus facile que DoFn of ParDo en utilisant une fonction anonyme.
Essayez de réécrire à l'aide de Simple Function
code
beamSample.java
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.values.PCollection;
import org.apache.beam.sdk.values.TypeDescriptors;
public class SimpleBeam {
public static void main(String[] args){
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
//Lire le texte
PCollection<String> textData = p.apply(TextIO.read().from("Sample.txt"));
//Implémentez le même processus en utilisant des fonctions anonymes
PCollection<String> BidData = textData.apply(
MapElements.into(TypeDescriptors.strings())
.via((String row) -> row.split(",")[4])
);
//Rédaction de texte
BidData.apply(TextIO.write().to("output/bid"));
//Pipeline run
p.run().waitUntilFinish();
}
}
C'est beaucoup plus simple!
En ce qui concerne l'impression que j'ai touché Beam pendant un certain temps, il est assez gênant de créer DoFn à chaque fois car le processus consistant à simplement changer le type de données correspond, je voudrais donc l'utiliser activement.
En d'autres termes
Java 8 ne peut pas être activé
Méthode de changement normal File => Project Structure...
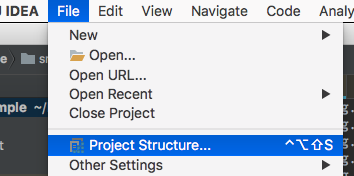
ProjectSettings => Projet => Définissez Niveau de langue du projet sur 8
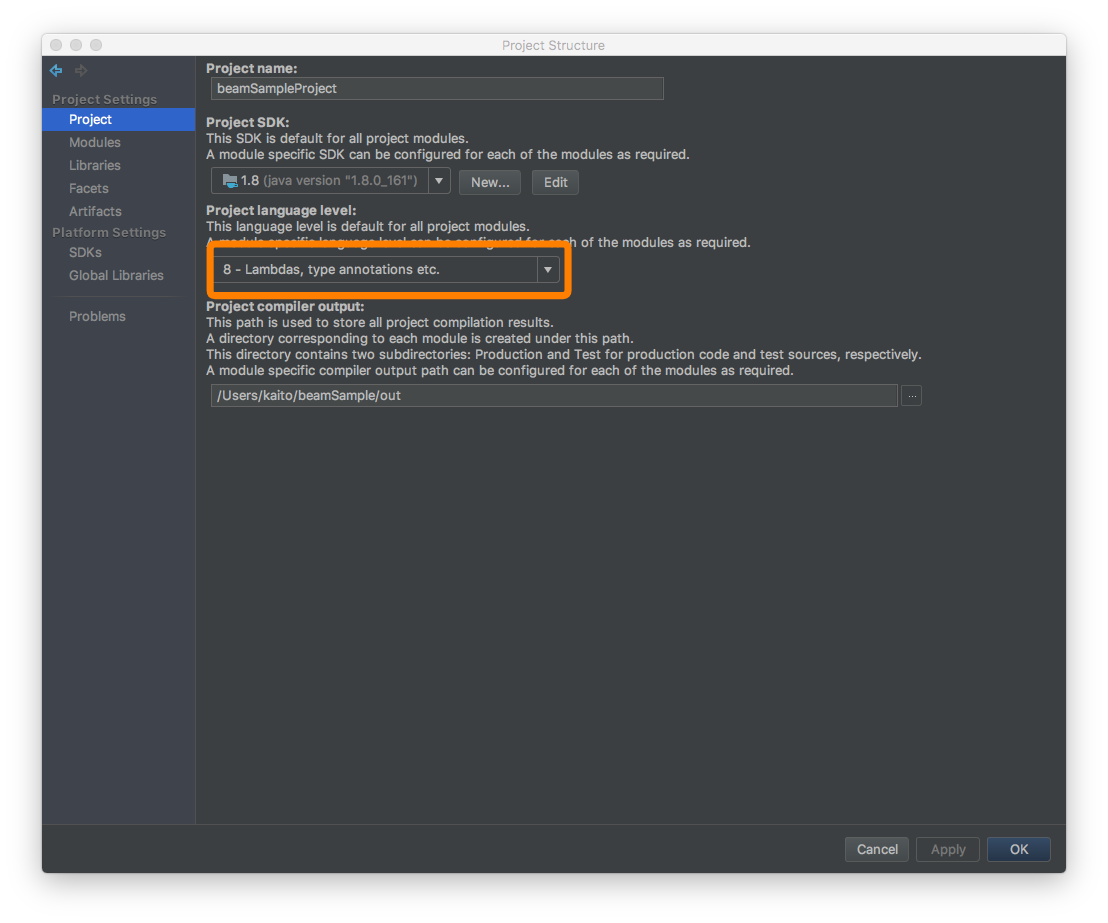
** Ne passe toujours pas ... Dans un tel cas, suivez les étapes ci-dessous **
Solution
Ajout de la description suivante à pom.xml
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>beamSample</groupId>
<artifactId>beamSample</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 1.Ajouté pour rendre 8 reconnu-->
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<!--Ajouter ici-->
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>2.4.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
</project>
de la prochaine fois
Cette fois, j'ai implémenté ParDo, qui équivaut au traitement Map de MapReduce. La prochaine fois, j'aimerais implémenter facilement le traitement Réduire et trouver la moyenne des informations de ticker.
Recommended Posts