[Pratique pour les débutants] Lire ligne par ligne "Prédire les prix des logements" de kaggle (Partie 2: Confirmation des valeurs manquantes)
thème
Cliquez ici pour le premier contenu La deuxième partie du projet consiste à prendre note du contenu des travaux pratiques que tout le monde va contester le fameux thème "Prix de la maison" problème de kaggle. C'est plus un mémo qu'un commentaire, mais j'espère que cela aide quelqu'un quelque part.
- Thème original: https://www.kaggle.com/c/house-prices-advanced-regression-techniques
- Article référencé: https://yolo-kiyoshi.com/2018/12/17/post-1003/
Le travail d'aujourd'hui
Confirmation des valeurs manquantes (ne peut pas être complétée)
En conclusion, il semble qu'il y ait pas mal de valeurs manquantes.
Statut manquant des données d'entraînement (valeur manquante)
train.isnull().sum()[train.isnull().sum()>0].sort_values(ascending=False)
Valeur manquante
- Qu'est-ce qu'une "valeur manquante" en premier lieu: https://www.weblio.jp/content/%E6%AC%A0%E6%90%8D%E5%80%A4
Lors de la préparation d'un fichier de données, vous devez saisir une valeur numérique même si les données sont manquantes. Cependant, la valeur numérique saisie indique qu'il n'y avait en fait aucune donnée, il est donc nécessaire de l'exclure de la cible d'analyse. Par conséquent, entrez une valeur (valeur manquante) qui peut être clairement distinguée des autres données valides.
.isnull()
- .isnull (): Il vérifie si la valeur est entrée comme vrai ou faux pour chaque élément.
- Référence: https://note.nkmk.me/python-pandas-nan-judge-count/
- Lorsque le résultat est sorti uniquement par train.isnull ()
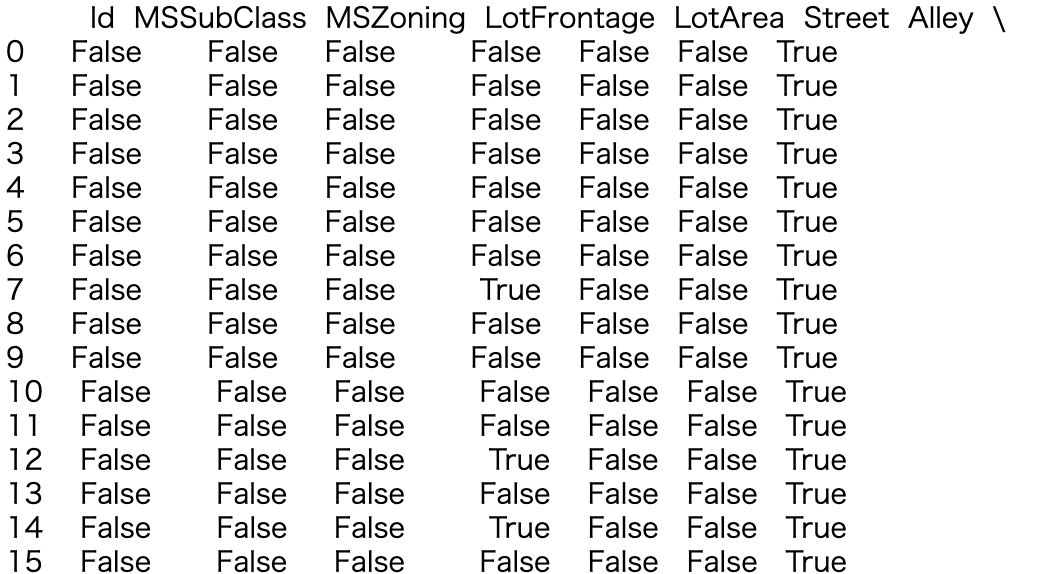
.sum()
-
.sum (): ajout familier. Il s'additionne à la fois verticalement et horizontalement en spécifiant un argument.
-
Référence: https://deepage.net/features/pandas-sum.html
-
Lorsque le résultat est sorti uniquement par train.isnull (). Sum ()
-
[train.isnull (). Sum ()> 0]: Sentiment que seules les colonnes avec des éléments manquants sont spécifiées comme des clés et organisées.
-
Lorsque le résultat est affiché uniquement avec train.isnull (). Sum () [train.isnull (). Sum ()> 0]

.sort_values()
- .sort_values (ascending = False): tri des données. Ici, seuls les arguments en ordre décroissant sont spécifiés, mais il semble que vous puissiez sélectionner les éléments pour trier ou modifier l'algorithme. Pratique.
- Référence: https://deepage.net/features/pandas-sort-values.html
- Affichage uniquement avec train.isnull (). Sum () [train.isnull (). Sum ()> 0] .sort_values (ascending = False)

Données de test manquantes
L'explication est la même que les données d'entraînement, je vais donc l'omettre.
test.isnull().sum()[test.isnull().sum()>0].sort_values(ascending=False)
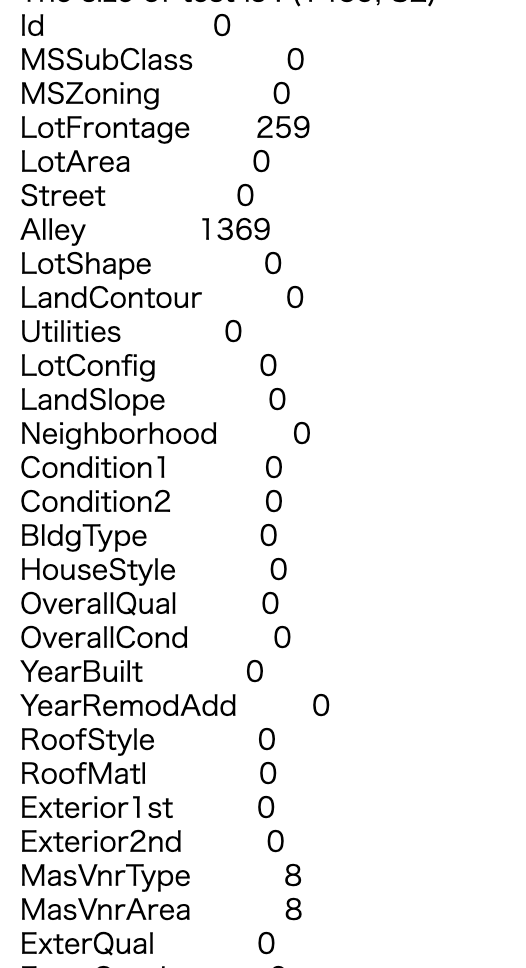
Statut de perte de données d'entraînement (type de données)
.index.tolist()
#Vérifiez le type de données de la colonne contenant le défaut
na_col_list = alldata.isnull().sum()[alldata.isnull().sum()>0].index.tolist() #Répertorier les colonnes contenant des défauts
alldata[na_col_list].dtypes.sort_values() #Type de données
- ʻAlldata.isnull (). Sum () [alldata.isnull (). Sum ()> 0] ʻJ'ai omis le contenu jusqu'au point où les valeurs manquantes sont alignées.
- .index: Est-ce différent de ʻindex () `? J'ai pensé, mais cela semble différent.
- .tolist (): Je l'ai utilisé à nouveau pour ne lister que les colonnes. (Légèrement ambigu)
- Référence: https://note.nkmk.me/python-pandas-list/
- Résultat de sortie de
na_col_list = alldata.isnull (). Sum () [alldata.isnull (). Sum ()> 0] .index.tolist ()
.dtypes
- .dtypes: Si vous appliquez ceci à un tableau, il vérifiera chaque type de données. Pratique. Il existe également un dtype similaire.
- Référence: https://www.sejuku.net/blog/62023
- Résultat de sortie ʻAlldata [na_col_list] .dtypes` (* Le contenu de sort_values () est omis, par ordre croissant)

Comprendre et gérer les situations de carence
Ceci est une description des opinions sur la manière de traiter les données de manière statistique. Nous vous recommandons de le lire et de le comprendre normalement. Une histoire différente de la compréhension de la programmation.
Les données d'entraînement et les données de test manquent considérablement. Dans un tel cas, vous souhaiterez supprimer la colonne présentant de nombreux défauts. Mais avant cela, Kaggle a un document détaillant les variables, alors jetons un coup d'œil dessus. Lorsque vous téléchargez les données de Kaggle, vous remarquerez qu'il contient également un fichier appelé "data_description.txt". Ce fichier détaille les données stockées dans les variables. Ensuite, vous pouvez voir que la majorité des lacunes ne signifie pas qu'il n'y a pas d'informations, mais que les lacunes elles-mêmes sont des informations. Par exemple, jetons un coup d'œil à PoolQC (qualité de la piscine), qui présente le plus de défauts. La perte de cette variable signifie que la piscine n'existe pas dans la maison et que la perte de données elle-même est une information. Pour les autres variables (variables catégorielles), une déficience signifie simplement que l'installation ou l'équipement n'existe pas. De plus, pour les variables numériques, la carence signifie uniquement que la surface occupée est nulle et qu'elle n'est pas sans information. Par conséquent, la complétion suivante est effectuée pour la perte des variables catégorielles et des variables de type numérique.
C'est tout.
Hmmm. Je viens de regarder les données.
Recommended Posts