Ensemble de données pour l'évaluation de l'algorithme de détection des réviseurs de spam
Aperçu
 Pour l'évaluation de l'algorithme de détection des critiques de spam,
Article [Un modèle de graphique bipartite et une analyse se renforçant mutuellement pour les sites d'évaluation](http://www.anrdoezrs.net/links/8186671/type/dlg/http://link.springer.com/chapter/10.1007%2F978-3 -642-23088-2_25)
Des données artificielles ont été publiées. Cet article résume comment l'utiliser.
Il résume également l'évaluation parallèle à l'aide de Google Cloud Platform.
Pour l'évaluation de l'algorithme de détection des critiques de spam,
Article [Un modèle de graphique bipartite et une analyse se renforçant mutuellement pour les sites d'évaluation](http://www.anrdoezrs.net/links/8186671/type/dlg/http://link.springer.com/chapter/10.1007%2F978-3 -642-23088-2_25)
Des données artificielles ont été publiées. Cet article résume comment l'utiliser.
Il résume également l'évaluation parallèle à l'aide de Google Cloud Platform.
Installation
Le paquet est enregistré dans PyPI, vous pouvez donc l'installer avec la commande pip.
$ pip install --upgrade rgmining-synthetic-dataset
Lecture de données graphiques artificielles
Le "rgmining-synthèse-dataset" contient le package "synthétique".
Exportez la fonction synthèse.load et la constanteynthétique.ANOMALOUS_REVIEWER_SIZE.
La fonction synthétique.load charge les données de graphique de revue artificielle
La constante synthétique.ANOMALOUS_REVIEWER_SIZE est incluse dans cet ensemble de données
Il représente le nombre d'examinateurs de spam particuliers («57»).
Le critique particulier de spam a «anomalie» dans son nom.
Par conséquent, dans l'évaluation utilisant cet ensemble de données,
Dans quelle mesure pouvez-vous trouver 57 critiques de spam avec précision et reproductibilité? Découvrir.
Je vais omettre l'explication de la façon dont les données artificielles ont été créées. Si vous êtes intéressé, [Original paper](http://www.anrdoezrs.net/links/8186671/type/dlg/http://link.springer.com/chapter/10.1007%2F978-3-642-23088- Veuillez vous référer à 2_25). (Je peux le résumer dans un autre article un jour)
La fonction synthétique.load prend un objet graphique comme argument.
Cet objet graphique est
--new_reviewer (nom) : Crée et renvoie un objet réviseur avec le nom nom.
--new_product (nom) : Crée et renvoie un objet produit avec le nom nom.
--ʻAdd_review (reviewer, product, rating) : Ajouter un avis dont le score pour produit par critique est note` Notez que. On suppose que «rating» est normalisé à 0 ou plus et 1 ou moins.
Vous devez avoir trois méthodes.
Le Fraud Eagle introduit l'autre jour remplit cette condition. Donc,
import fraud_eagle as feagle
import synthetic
graph = feagle.ReviewGraph(0.10)
synthetic.load(graph)
Ensuite, vous pouvez analyser ces données artificielles à l'aide de l'algorithme Fraud Eagle.
Analyse réelle
Fraud Eagle était un algorithme qui prend un paramètre, donc Découvrons quels paramètres conviennent à cet ensemble de données artificielles. Cette fois, parmi les 57 personnes avec un «score_anomal» élevé, Évaluez en utilisant le pourcentage qui était en fait un critique de spam particulier. (Plus ce ratio est élevé, plus les critiques de spam sont corrects et particuliers.)
analyze.py
#!/usr/bin/env python
import click
import fraud_eagle as feagle
import synthetic
@click.command()
@click.argument("epsilon", type=float)
def analyze(epsilon):
graph = feagle.ReviewGraph(epsilon)
synthetic.load(graph)
for _ in range(100):
diff = graph.update()
print("Iteration end: {0}".format(diff))
if diff < 10**-4:
break
reviewers = sorted(
graph.reviewers,
key=lambda r: -r.anomalous_score)[:synthetic.ANOMALOUS_REVIEWER_SIZE]
print(len([r for r in reviewers if "anomaly" in r.name]) / len(reviewers))
if __name__ == "__main__":
analyze()
J'ai utilisé click pour l'analyseur de ligne de commande.
$ chmod u+x analyze.py
$ ./analyze.py 0.1
Ensuite, vous pouvez expérimenter avec le paramètre «0,1». La sortie est
$ ./analyze.py 0.10
Iteration end: 0.388863491546
Iteration end: 0.486597792445
Iteration end: 0.679722652169
Iteration end: 0.546349261422
Iteration end: 0.333657951459
Iteration end: 0.143313076183
Iteration end: 0.0596751050403
Iteration end: 0.0265415183341
Iteration end: 0.0109979501706
Iteration end: 0.00584731865022
Iteration end: 0.00256288275348
Iteration end: 0.00102187920468
Iteration end: 0.000365458293609
Iteration end: 0.000151984909839
Iteration end: 4.14654814812e-05
0.543859649123
Il semble qu'environ 54% des 57 premières personnes étaient des critiques de spam particuliers.
Recherche des paramètres optimaux dans le cloud
J'ai défini le paramètre sur 0,1 plus tôt, mais le résultat change-t-il avec d'autres valeurs? Vérifions plusieurs valeurs. Fondamentalement, vous pouvez exécuter le script ci-dessus un par un avec différents paramètres. Comme cela semble prendre du temps, nous l'exécuterons en parallèle en utilisant le cloud de Google.
Pour utiliser le cloud Google, utilisez l'outil roadie présenté dans Utiliser Google Cloud Platform plus facilement. Veuillez vous référer à l'article ci-dessus pour l'installation et la méthode de configuration initiale.
Tout d'abord, listez les bibliothèques requises pour exécuter le fichier analyz.py créé précédemment dans requirements.txt.
requirements.txt
click==6.6
rgmining-fraud-eagle==0.9.0
rgmining-synthetic-dataset==0.9.0
Ensuite, créez un fichier script pour exécuter roadie.
analyze.yml
run:
- python analyze.py {{epsilon}}
Cette fois, nous n'avons pas besoin d'un fichier de données externe ou d'un package apt, donc
N'écrivez simplement que la commande d'exécution. La partie {{epsilon}} est un espace réservé.
Passez-le comme argument lors de la création d'une instance.
De plus, comme nous prévoyons de créer de nombreuses instances cette fois, nous utiliserons des files d'attente.
Tout d'abord, exécutez la première tâche, qui sert également de téléchargement du code source.
$ roadie run --local . --name feagle0.01 --queue feagle -e epsilon=0.01 analyze.yml
La première consiste à définir le paramètre sur 0,01.
Avec -e epsilon = 0.05, la valeur est définie sur` {{epsilon}} ʻinanalyser.yml.
Exécutez ensuite la tâche pour les paramètres restants.
$ for i in `seq -w 2 25`; do
roadie run --source "feagle0.01.tar.gz" --name "feagle0.${i}" \
--queue feagle -e "epsilon=0.$i" analyze.yml
done
—Source feagle0.01.tar.gz spécifie l'utilisation du code source téléchargé en premier.
De plus, si vous passez «—queue
$ roadie queue instance add --instances 7 feagle
Le statut d'exécution de chaque instance est
$ roadie status
Vous pouvez vérifier avec. Le nom de la file d'attente + un nombre aléatoire est le nom de l'instance traitant la file d'attente. Si l'état disparaît, le processus est terminé.
Étant donné que le résultat de l'exécution est enregistré dans Google Cloud Storage, Obtenez-le avec la commande suivante et écrivez-le dans un fichier CSV.
$ for i in `seq -w 1 25`; do
echo "0.${i}, `roadie result show feagle0.${i} | tail -1`" >> result.csv
done
Vous pouvez obtenir la sortie de chaque tâche avec roadie result show <nom de la tâche>.
Tracons le CSV obtenu.
plot.py
#!/usr/bin/env python
import click
from matplotlib import pyplot
import pandas as pd
@click.command()
@click.argument("infile")
def plot(infile):
data = pd.read_csv(infile, header=None)
pyplot.plot(data[0], data[1])
pyplot.show()
if __name__ == "__main__":
plot()
C'est assez simple, mais c'est un bon prototype.
$ chmod u+x plot.py
$ ./plot.py result.csv
Le résultat à portée de main est le suivant.

Puisque 0,01 à 0,13 sont plats, vérifions même une valeur légèrement plus petite. Mettez la tâche dans la file d'attente comme avant et exécutez-la en 8 parallèles.
$ for i in `seq -w 1 9`; do
roadie run --source "feagle0.01.tar.gz" --name "feagle0.00${i}" \
--queue feagle -e "epsilon=0.00$i" analyze.yml
done
$ roadie queue instance add --instances 7 feagle
Une fois l'exécution terminée, créez un CSV et tracez-le comme indiqué ci-dessous.
$ for i in `seq -w 1 9`; do
echo “0.00${i}, `roadie result show feagle0.00${i} | tail -1`" >> result2.csv
done
$ for i in `seq -w 1 25`; do
echo "0.${i}, `roadie result show feagle0.${i} | tail -1`" >> result2.csv
done
$ ./plot.py result2.csv
Le résultat est le suivant. Environ 54% semble être le meilleur de Fraud Eagle.
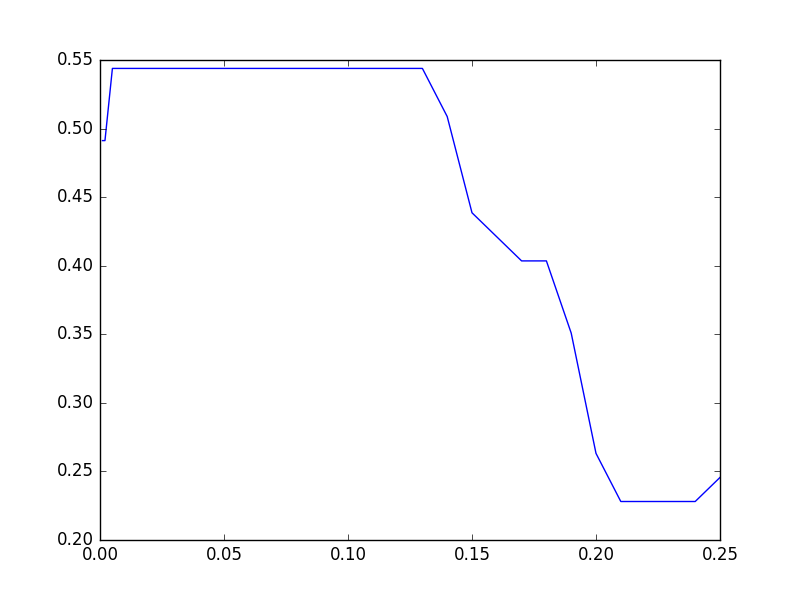
D'ailleurs, en fait, lorsque le paramètre est autour de "0,01", l'algorithme ne converge pas et vibre. Par exemple, dans le cas de 0,01, la sortie est
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Iteration end: 0.97009695897
Ça ressemble à ça. Cette fois, il est coupé en 100 boucles. Je pense que l'article original ne parlait pas des conditions de convergence, donc Il semble que nous devions enquêter un peu plus.
Recommended Posts