Génération de dialogue de caractères et conversion de ton par CVAE
1. 1. Aperçu
Bonsoir. Cette fois, comme le titre l'indique, j'ai essayé de générer le dialogue du personnage avec CVAE (Conditional Variational Auto-encoder). J'essaye également de changer le ton du personnage en utilisant la même méthode.
- 170624: Il y avait un problème avec le code github, il a donc été corrigé.
2. Article connexe (recherche existante)
Il existe de nombreux articles qui génèrent du dialogue dans le système RNN. [Evangelion] Essayez de générer automatiquement des lignes de type Asuka avec Deep Learning
Ces articles présentaient les défis suivants:
- Les données d'apprentissage du personnage sont petites (1000 phrases au maximum. De plus, si vous mélangez le dialogue d'autres personnages avec les données d'apprentissage, cela ne fonctionnera pas)
- Comme seules les lignes déjà prononcées par le personnage sont utilisées pour les données d'apprentissage, le personnage ne prononcera pas de mots qui n'apparaissent pas dans les lignes.
Je voudrais résoudre ces problèmes avec CVAE. Puisque CVAE peut apprendre les caractéristiques de chaque catégorie (caractère dans ce cas), il est possible d'améliorer la précision de la génération de dialogue pour chaque caractère même si le dialogue de différents caractères est ajouté aux données d'apprentissage.
3. 3. modèle
Suite à l'article que j'ai écrit la dernière fois, "Définir les paramètres de caractères avec VAE.", j'utilise également LST MVAE comme modèle. Les modèles LSTM, VAE et Encoder-Decoder ne seront pas abordés en détail ici, donc si vous ne les connaissez pas, veuillez vous référer aux articles suivants.
- Présentation du réseau LSTM
- Auto-Encoding Variational Bayes [arXiv:1312.6114]
- Chainer, RNN et traduction automatique
VAE est un modèle qui a transformé DeepNeuralNet en un modèle de génération, mais le problème était qu'il n'était pas possible de contrôler le type de données générées. CVAE a résolu ce problème.
CVAE est un modèle qui combine VAE avec un vecteur de catégorie (un vecteur qui exprime une catégorie, qui est également un paramètre).
Comme exemple d'application de VAE, la génération d'image de MNIST (reconnaissance de caractères des nombres) est introduite dans l'article.

Dans VAE normal, les nombres sont générés de manière aléatoire, mais dans CVAE, vous pouvez spécifier des nombres de 0 à 9 à générer.
En utilisant la même méthode, j'ai vérifié s'il était possible de spécifier un personnage et de générer un dialogue.
La configuration du modèle CVAE est fondamentalement la même que celle du LST MVAE dans Article précédemment écrit.
Ajoutez simplement le vecteur de catégorie à la valeur initiale de la couche cachée de l'encodeur et du décodeur de celui-ci.
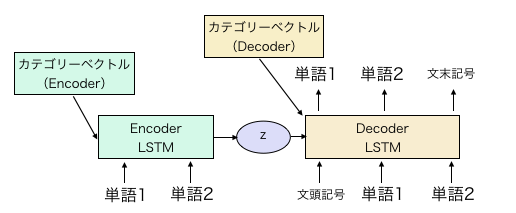
Une illustration simple montre le modèle ci-dessus. Le vecteur de catégorie dans la figure ci-dessus est un paramètre à modifier et à apprendre pour chaque caractère. Au moment de l'apprentissage, il est mis à la fois dans Encoder et Decoder, mais au moment de la génération, le dialogue du personnage en regard peut être généré en combinant la distribution de l'expression intermédiaire z et le vecteur de catégorie de Decoder.
L'encodeur est LSTM bidirectionnel et la dimension de chaque couche cachée est de 300. La dimension de la couche médiane z est de 600. La dimension de la couche cachée du décodeur est définie sur 600. Le vecteur de mot est de 300 pour le codeur et le décodeur. L'analyse morphologique est effectuée par le morceau de phrase, et le nombre de mots est d'environ 16000.
Plus tard, je n'étais pas sûr de ce qui suit, mais j'ai créé le vecteur de catégorie pour les couches cachées h et c du LSTM. Le codeur étant bidirectionnel, il existe au total 6 types de vecteurs de catégorie en 2x3. Les dimensions sont les mêmes que les dimensions de la couche cachée (300 pour l'encodeur, 600 pour le décodeur) Le code est comme d'habitude https://github.com/ashwatthaman/LSTMVAE Il est placé dans. src/each_case/sampleCVAESerif.py Le code d'exécution de VAE conditionnelle est écrit au format. Cependant, cette fois, les données ne peuvent pas être divulguées du point de vue du droit d'auteur, donc Seules les données factices sont placées.
4. Les données
Cela a été analysé à partir des sites suivants.
- Ce que vous devriez aimer-Introduction de lignes d'anime-
- Transcriptions d'anime @ Anime en anglais Un total de 218 caractères et environ 120 000 phrases sont en cours d'apprentissage. Les 120 000 phrases ci-dessus n'utilisent que les lignes de caractères de plus de 100 lignes.
5. résultat
5.1. Génération de phrases pour chaque caractère
Le résultat. Celui que j'ai dit le mieux (je pense) était la réplique de Rei Ayanami, donc je la posterai ici.
C'est un mensonge. Je suis le seul.
Ah, je devrais protéger la première machine
Je pense que je me cherchais.
Ikari a beaucoup échoué.
Vivant
Je ne sais pas. Je fais la première sortie de machine.
Il a un visage appelé Rei Ayanami.
...Maison. Puis...Seulement pour toi
Je viens avec un mauvais pressentiment?
Non. Je ne peux vraiment pas bouger.
Que dis-tu Cependant, il n'y a pas de faveur. Je ne sais pas ce que j'ai fait.
Merci merci. Je suis dans la porte du jour
Vous en avez terminé avec ce qu'on appelle Rei Ayanami.
Tais-toi et frappe quelqu'un.
Oui. Cet objet vous en est reconnaissant et a l'intention de le faire.
C'est effrayant de s'en occuper, avec le temps.?
Parce que c'est la situation. Tout le monde était inquiet.
félicitations!
Pourquoi es-tu vivant?
Alors je me suis enfui de ton père
Non, je suis moi. J'ai vécu ma vie!
Non, ne t'enfuis pas!
C'est subjectif, mais il semble que des phrases similaires soient générées plus que simplement en utilisant RNN. "Mentez. Je suis le seul." </ B> "Alors j'ai fui ton père" </ b> Je veux qu'Ayanami dise quelque chose comme Rahen, mais c'est normal de dire quelque chose qui n'est pas dit.
Vient ensuite Misato.
Il est normal de sortir pour la récupération?
Je suis désolé
Quoi qu'il en soit, couper l'alimentation de secours de Nerv!
Mais je veux être heureux.
D'après le rapport du siège, je vais le terminer un peu tôt le matin
Suivez les ordres de Shinji.
Je suis désolé, je l'ai. Alors je dois y aller tôt
Je vais l'ouvrir, Japon.
Un tel souhait déraisonnable
...Asuka, une forteresse de rechange
Un gars qui ne peut pas faire de blagues comme d'habitude.
Est-ce sur la blessure de votre mère??
Le comité coupe l'alimentation électrique de secours. Et tourner la première machine
Kamochi-kun, je vais vous bombarder?
Stupide...
Tu as une idée?
Effrayant!Quel genre de visage aviez-vous en écoutant la solitude??
J'ai un visage comme toi. Tu es un père
Apôtre?
Ça, Asuka, Ray?L'unité 0 est?
Je déteste ça!
...Le pilote d'Eva a un signal d'urgence...sensationnel
Et, non, non, non, je ne porte pas ça...
alors.
Ca c'était quoi!?
Que le Dara Saschi de te laisser frapper...
Bien!
changement?
Première, deuxième, deuxième qualification, quel sauvetage.
Asuka
Je déteste ça, je le sais!
je connais!Il l'a fait pour moi, alors prête-moi le déjeuner de ta mère.
Maman?
Il m'a apporté un bain avec M. Kamochi?
Ennuyeux!
...C'est bon, je déteste vraiment ça!
Haine...
Attends une minute ici!
Maman, idiot
D'accord, Sheggy Ete Yoi!
Stupide!あんたなんかStupideにすんのよ!
cette?
Je pars, je pars.
Comme ça, je suis un adulte en ce moment.
Je déteste ça!Stupide!
...Cet imbécile...
J'attends ici un moment. Pars s'il te plait!M. Kamochi!
Premièrement, je suis dans la première phase
Je déteste ça, je déteste ça, je l'ai tellement fait, ce n'est pas une autre
Remplacé, sauvegardez l'unité 2, vous-même.
Ne raconte pas les histoires des gens
Qu'est-ce que c'est?
Evangelion n ° 2 et n ° 2!
C'est un enfant étrange.
Hah...
Je connais.
...Kamochi est bruyant...
Ne t'appelle pas non plus!
Le taux de synchronisation est le quatrième en environ deux semaines.
Quel mensonge, ça
Je déteste ça, d'abord.
Prends ça pour le moment!
Vous roulez depuis longtemps même si vous ne vous êtes pas encore réveillé
Attends une minute ici!
Tu es stupide?D'abord réfrigéré en premier!
Quoi, la bouche vient de chaque bouche, s'entends bien!
D'accord, Shejoie Teyoi! </ B> Poptepipic soudain.
Le dialogue des autres personnages https://github.com/ashwatthaman/LSTMVAE/tree/master/src/each_case/serif/test28_Public.txt C'est dedans. Il y a Gundam, Code Gears, Haruhi, Rakisuta, Everyday, Squid Girl et ainsi de suite. Il semble que la précision de génération soit assez différente selon le personnage.
5.2. Conversion de tonalité
Ensuite, essayez de changer le ton. Quant à savoir quoi faire, j'ai mentionné plus tôt que CVAE ajoute des vecteurs de catégorie aux encodeurs et aux décodeurs. Normalement, le même vecteur de catégorie est inséré dans le codeur et le décodeur, mais est-il possible de convertir le dialogue du caractère du codeur en un autre style de caractère en insérant différents vecteurs? J'ai essayé ça.
Dialogue de Nao Yuri "Veuillez voir tout le monde" </ b> Sera converti en fille de calmar.
Alors ...
"Tout le monde, fais-le!" </ B>
A été sortie. Je suis désolé ... Cela aurait été parfait si je l'avais vu au lieu de le faire.
Ensuite, le dialogue d'Asuka "Halo, Misato! Comment vas-tu?" </ B> Est converti au style Shinji.
"Comme dit Misato. Contactez Ayanami." </ B>
est devenu. Eh bien, c'est subtil.
Un autre Dialogue de Char "Guney a arrêté les missiles nucléaires de l'ennemi. C'est le travail d'un humain renforcé." </ B> Pour ques.
"Je vous pardonne de m'avoir dit que Guney a arrêté les missiles nucléaires de l'ennemi." </ B> Maintenant ça. Je pense que cela peut être converti relativement.
Mais relativement comme ça? Personne sur dix n'a fonctionné. Dans la plupart des cas, il a été converti en mots avec des significations complètement différentes. Il semble qu'un peu plus d'ingéniosité soit nécessaire pour convertir la tonalité avec AutoEncoder.
6. Considération ou impression
6.1. Génération de dialogue
Tout d'abord, j'ai soulevé deux défis avec les méthodes existantes.
- Vous ne pouvez pas bien apprendre en raison du manque de données d'entraînement.
- Si vous apprenez uniquement avec le dialogue d'un personnage, ne dites pas de mots que le personnage n'a pas encore prononcés. C'est deux points.
Nous n'avons pas évalué quantitativement 1., mais je pense qu'il a été confirmé que la qualité des phrases peut être améliorée en incluant le dialogue d'autres personnages dans les données d'entraînement. Comparé aux méthodes existantes, le pourcentage de phrases grammaticalement brisées est faible. De plus, il n'émet pas directement ce qui se trouve dans le dialogue original.
Environ 2. Dans l'exemple ci-dessus, Ray dit «porte» et Misato dit «forteresse». Puisque ces mots n'apparaissent pas dans la phrase de dialogue originale, on peut dire qu'ils ont réussi à émettre de nouveaux mots. Cependant, le ratio est inférieur aux attentes.
6.2. Conversion de tonalité
En changeant le vecteur de catégorie avec encodeur et décodeur, nous avons montré la possibilité de changer la tonalité et le style. (Bien que ce ne soit pas encore à un niveau pratique)
Les résultats de l'addition / soustraction de mots dans word2vec et de l'addition / soustraction d'image (enlever et mettre des lunettes) dans GAN sont connus, mais il semble qu'il n'y ait pas de recherche pour changer le sens ou le style en ajoutant ou en soustrayant des phrases. Je vais. Bien sûr, vous pouvez changer le style lui-même en utilisant le modèle encodeur-décodeur, mais ce n'est pas réaliste du point de vue que vous devez collecter une grande quantité de phrases correspondantes.
La précision de la conversion à l'aide de CVAE peut être améliorée dans une certaine mesure en augmentant les données d'entraînement, mais on ne sait pas à ce stade dans quelle mesure elle peut être atteinte. Il y a un peu plus de place pour la recherche.
7. Problèmes futurs
- Si vous voulez vraiment vérifier si vous pouvez convertir le ton et le style, il semble préférable d'utiliser des données avec plus de phrases dans chaque catégorie.
- Même s'il y a 120 000 phrases, des phrases grammaticalement incorrectes peuvent être générées. Je pense que cela peut être résolu en augmentant les données d'entraînement.
- Cette fois, au lieu de MeCab, Sentencepiece est utilisé pour la division morphologique, donc si les conditions sont remplies, MeCab doit être utilisé pour la comparaison. Cependant, je ne pense pas que cela changera autant en fonction de la méthode de division morphologique, donc je pense que CVAE fonctionne.
- J'ai eu du mal à faire dire au personnage un mot qui n'était pas prononcé dans les données d'entraînement. Eh bien, avez-vous besoin de quelque chose qui est pré-distribué?
8. Site de référence (merci pour votre aide)
article
- [Evangelion] Essayez de générer automatiquement des lignes de type Asuka avec Deep Learning
- Effectuez les réglages de caractères avec VAE.
- Présentation du réseau LSTM
- Auto-Encoding Variational Bayes [arXiv:1312.6114]
- Chainer, RNN et traduction automatique
papier
Données d'entraînement