Sous-packages de SciPy fréquemment utilisés
SciPy est une collection de nombreux algorithmes mathématiques et fonctions utiles basés sur NumPy et en est une extension. Aujourd'hui, je vais explorer quelques-uns des énormes sous-packages SciPy qui sont souvent utilisés et utiles. Je vais.
Les sous-packages comprennent: Chacun de ceux-ci peut être appelé à partir de l'importation scipy PACKAGE_NAME. (Il y a d'autres façons de le faire)
| paquet | Contenu |
|---|---|
| cluster | Algorithme de clustering |
| constants | Constantes physiques et constantes mathématiques |
| fftpack | Routine de transformation de Fourier rapide |
| integrate | Intégration et équations différentielles normales |
| interpolate | Interpolation et lissage des splines |
| io | Entrée et sortie |
| linalg | algèbre linéaire |
| ndimage | Traitement en N dimensions |
| odr | Régression de distance orthogonale |
| optimize | Optimisation et routine de détection de racine |
| signal | Traitement de signal |
| sparse | Routines associées à des matrices clairsemées |
| spatial | Structure des données spatiales et algorithmes |
| special | Particularités |
| stats | Distribution statistique et fonction |
| weave | C/C++L'intégration |
À ma discrétion et selon mes préjugés, les sous-packages les plus fréquemment utilisés sont scipy.stats et scipy.linalg. .
Fonction statistique (scipy.stats)
scipy.stats est un sous-paquetage de statistiques. Premièrement, il existe deux classes générales qui encapsulent des variables de probabilité continues et discrètes. Sur cette base, SciPy a des classes pour plus de 80 variables stochastiques continues et plus de 10 variables probabilistes discrètes. Ces classes à dominante statistique sont organisées sous scipy.stats.
Les méthodes courantes pour les variables stochastiques continues comprennent:
| Méthode | Contenu |
|---|---|
| rvs | Variable aléatoire |
| Fonction de densité de probabilité | |
| cdf | Fonction de distribution cumulative |
| sf | Fonction de survie (1-CDF) |
| ppf | Fonction de pourcentage (inverse de CDF) |
| isf | Fonction de survie inverse (inverse de SF) |
| stats | Moyenne, dispersion, netteté de Fisher, vraisemblance |
| moment | Ratio de produit décentralisé |
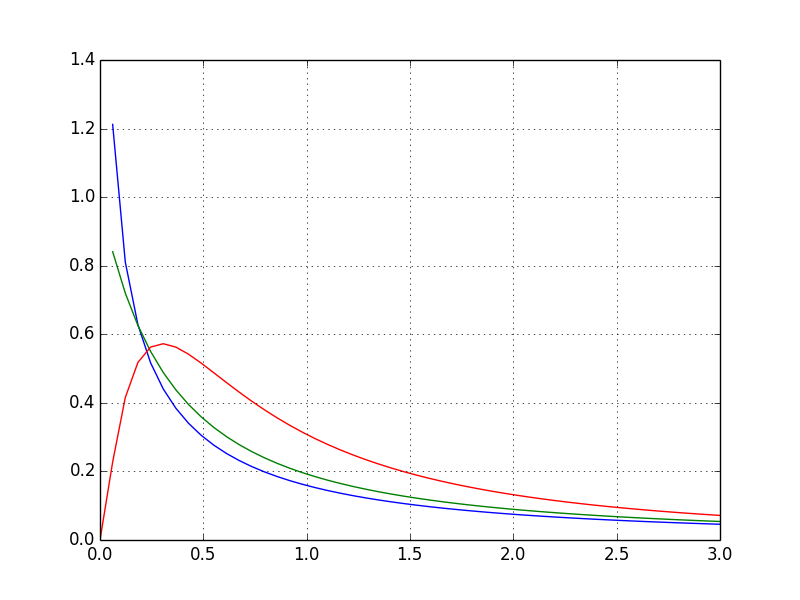
Distribution F
C'est une distribution F familière.
from scipy.stats import f #Appelez la distribution F à partir des statistiques
def draw_graph(dfn, dfd):
rv = f(dfn, dfd) #Tracez une distribution F avec les deux arguments donnés
x = np.linspace(0, np.minimum(rv.dist.b, 3))
plt.plot(x, rv.pdf(x))
draw_graph(1, 1)
draw_graph(2, 1)
draw_graph(5, 2)
score z
Il peut être obtenu comme suit.
x = np.array([61, 74, 55, 85, 68, 72, 64, 80, 82, 59])
print(stats.zscore(x))
#=> [-0.92047832 0.40910147 -1.53413053 1.53413053 -0.20455074 0.20455074
# -0.61365221 1.02275369 1.22730442 -1.12502906]
Algèbre linéaire (scipy.linalg)
Calculs d'algèbre linéaire très rapides avec BLAS et LAPACK ..
Toutes les routines algébriques linéaires supposent un objet qui peut être converti en un tableau à deux dimensions. La sortie de ces routines est également fondamentalement un tableau à deux dimensions.
x = np.array([[1,2],[3,4]])
linalg.inv(x)
#=>
# array([[-2. , 1. ],
# [ 1.5, -0.5]])
Résumé
Les sous-packages de SciPy ont un grand nombre de fonctions et sont loin d'être explicables. Si vous êtes intéressé, veuillez lire les Documents en ligne.
Si vous n'êtes pas satisfait de la documentation en ligne, vous pouvez également vous référer aux Livres gratuits présentés précédemment.
Recommended Posts