Enregistrez les données pandas dans des actifs de données au format Excel avec Cloud Pak for Data (Watson Studio)
Comment enregistrer des fichiers dans les actifs de données du projet d'analyse à l'aide de project_lib [Autre article](https://qiita.com/ttsuzuku/items/eac3e4bedc020da93bc1#%E3%83%87%E3%83%BC%E3% 82% BF% E8% B3% 87% E7% 94% A3% E3% 81% B8% E3% 81% AE% E3% 83% 87% E3% 83% BC% E3% 82% BF% E3% 81% AE% E4% BF% 9D% E5% AD% 98-% E5% 88% 86% E6% 9E% 90% E3% 83% 97% E3% 83% AD% E3% 82% B8% E3% 82% A7 Je l'ai écrit en% E3% 82% AF% E3% 83% 88), mais il a fallu quelques astuces pour l'enregistrer au format Excel. Après avoir recherché diverses choses, [cet article] de stackoverflow (https://stackoverflow.com/questions/56538138/saving-dataframe-as-excel-file-into-ibm-cloud-object-storage-with-python) C'était valable.
Voici un exemple que j'ai réellement essayé.
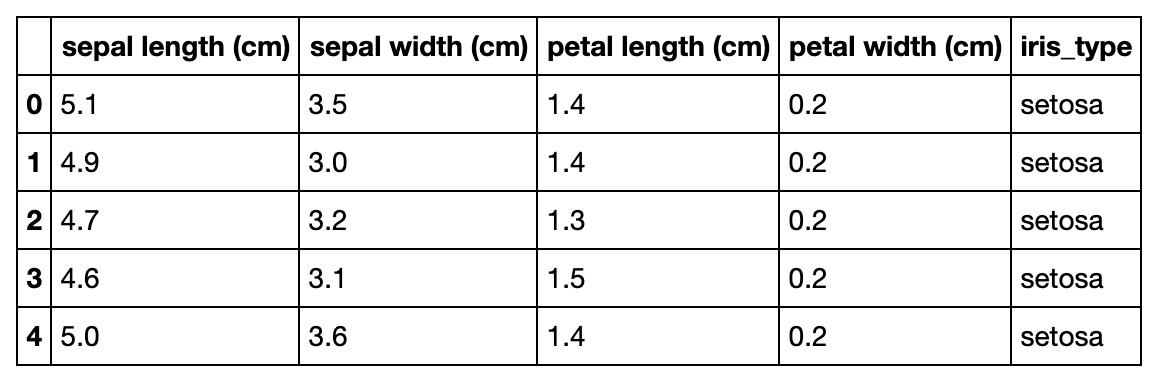
Trame de données Pandas utilisée
#Exemple de données Iris
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['iris_type'] = iris.target_names[iris.target]
df.head()
Sauvegardons ces données au format Excel. Le flux est une fois enregistré sous forme de fichier Excel dans l'environnement avec pandas.to_excel,
#Sortie vers l'environnement sous forme de fichier Excel une fois
filename = 'iris.xlsx'
df.to_excel(filename, index=False)
!pwd
!ls -l
# -output-
# /home/wsuser/work
# total 12
# -rw-r-----. 1 wsuser watsonstudio 8737 May 28 06:53 iris.xlsx
Lisez comme un flux d'octets io et enregistrez-le dans votre projet d'analyse avec project_lib.
from project_lib import Project
project = Project.access()
import io
with open(filename, 'rb') as z:
data = io.BytesIO(z.read())
project.save_data(filename, data, set_project_asset=True, overwrite=True)
Assurez-vous qu'il a été enregistré dans le projet d'analyse.

Au cas où, je le téléchargerai et jetterai un œil au contenu.
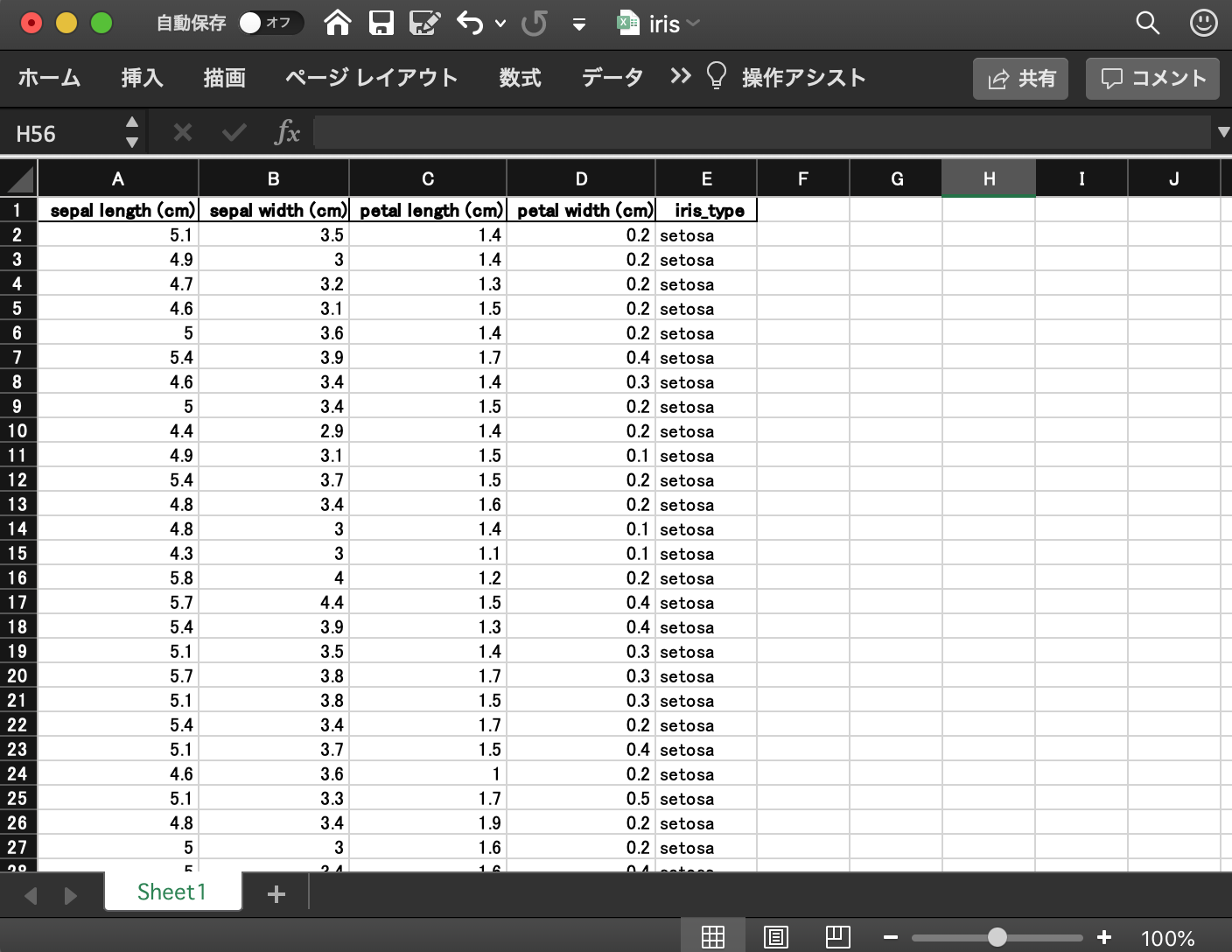 Vous avez enregistré avec succès 150 lignes de données Iris au format Excel.
Vous avez enregistré avec succès 150 lignes de données Iris au format Excel.
Recommended Posts