Traitement et jugement de la collecte du plan d'analyse des données (partie 1)
Jusqu'à présent, j'ai écrit sur les méthodes pratiques de statistique, mais si vous acquérez des statistiques et de l'économie métrologique, pouvez-vous prédire l'avenir l'un après l'autre par l'analyse des données et gagner beaucoup d'argent en investissant dans des actions et autres? Non, alors les statisticiens et les économistes devraient se consacrer à investir dans la recherche et devenir très riches d'ici là.
Random Walker à Wall Street dit que de nombreux gestionnaires de fonds professionnels n'ont pas battu la méthode d'investissement consistant à acheter au hasard la totalité des actions cotées. Des données empiriques scientifiques sont écrites. L'imprévisibilité de l'avenir est très difficile à prévoir en raison du mélange complexe de facteurs.
Par exemple, les statistiques médicales peuvent être utilisées pour examiner la corrélation entre une certaine nutrition ou mode de vie et une certaine maladie. Cela nous permet-il donc de prédire avec précision quand vous mourrez de maladie? Bien sûr que non. L'analyse des données ne peut pas prédire avec précision quand vous mourrez.
En d'autres termes, les connaissances causales sont très importantes.
Par exemple, si vous êtes un responsable des achats et des ventes, quels sont les points de produits susceptibles de déboucher sur des ventes, si vous êtes commercial, quels sont les facteurs décisifs qui conduisent à des contrats, et si vous êtes un personnel, pour développer des ressources humaines qui conduiront aux bénéfices de votre entreprise Quelle est la clé, il est important de clarifier ces points à partir de l'analyse des données.
Et ce n'est pas un surhomme ou une personne ressemblant à une sorcière qui se qualifie de scientifique des données apparaissant de manière fringante et résolvant le problème et partant, mais c'est un problème dû aux efforts quotidiens constants et à certaines analyses statistiques en première ligne. C'est un indice à découvrir et à résoudre.
Par exemple, lorsqu'il devient clair qu'un produit particulier se vend à un certain moment de la saison, l'analyse informatique ne peut que conclure que nous devrions acheter davantage de ce produit. Cependant, si vous êtes une personne impliquée dans les magasins et les produits, le "quelque chose" derrière, par exemple, le client doit en fait rechercher ~ ~, et ainsi de suite. En fin de compte, la perspicacité et le jugement humains sont nécessaires, ce qui est très important.
Objectif d'analyse des données et plan d'analyse
Cette fois, prenons un cas comme exemple et considérons le flux d'analyse des données et de leur utilisation.
J'ai fait un émulateur gacha avec Flask dans précédemment, mais cette fois le sujet est aussi un jeu social. Les jeux sociaux sont familiers et pratiques en tant que matériaux car ils sont accessibles à tous et peuvent en fait collecter des données réelles.
Bien sûr, peu importe qu'il s'agisse réellement des ventes en magasin, des performances des vendeurs ou de quoi que ce soit sur le réseau social.
Le plan est comme suit.
- Certains jeux sociaux ont des événements mensuels.
- Lors de cet événement, les participants concourront pour les scores et seront récompensés en fonction de leur classement.
- Les récompenses de classement et les classements aux frontières changent tous les mois.
La procédure d'analyse est la suivante.
- Clarifier l'objectif
- Collectez des données
- Organiser et traiter les données
- Saisir les tendances
- Utiliser comme base de jugement
Clarifier le but
Pourquoi analysez-vous cet événement? Avant de pouvoir analyser les données, nous devons d'abord clarifier l'objectif.
- Participez à l'événement de ce mois
- Prédire la frontière de ce mois dans une certaine mesure à partir des données passées
- Si vous pouvez prévoir la frontière, vous pouvez maintenir le montant de l'investissement au minimum nécessaire
Le classement est un moyen efficace d'alimenter la facturation dans les jeux sociaux. Par exemple, disons que vous avez 10 000 points supplémentaires pour obtenir la récompense souhaitée. Vous n'avez qu'à payer 1000 yens pour 10 articles. Par conséquent, nous facturons 1000 yens, mais les rivaux pensent naturellement de la même manière et facturent 1000 yens. Cela augmentera le score à la frontière, donc le classement n'augmentera pas après tout.
C'est censé être un peu plus, un peu plus, mais c'est un mécanisme qui vous facturera une grosse somme d'argent en le répétant.
Plus haut l'esprit de jeu qui vous donne envie de facturer quelque chose comme ça Afin d'éviter le marais sans fond de l'événement, la frontière du classement qui finira par atterrir Prédisez votre score dans une certaine mesure et investissez autant d'argent que nécessaire pour gagner le score final, quel que soit votre classement actuel. Le but de cette analyse est d'estimer ce score le plus précisément possible.
Collecter des données
Dans tous les cas, nous devons collecter des données, mais dans l'analyse des données, ce processus de collecte est souvent un lourd fardeau.
Voici quelques exemples de données.
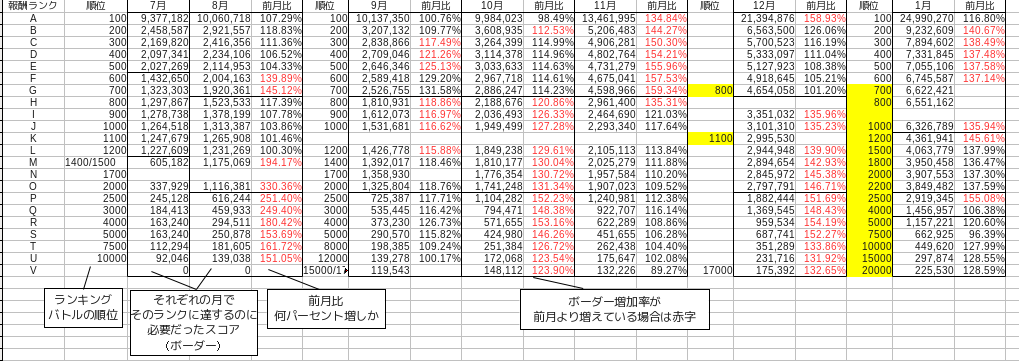
Il s'agit de données qui ne recueillent que le score final de l'événement pendant environ six mois, c'est-à-dire de juillet de l'année dernière à janvier de cette année.
Le score qui devient la frontière chaque mois fluctue un peu, mais fondamentalement la récompense la plus élevée = 100e place = rang A, la récompense supérieure = 700 à 800e place = rang G, la récompense inférieure = 2000 à 2200e place = rang O. Dans le tableau, ils sont séparés par des lignes noires. Le rang est pour des raisons de commodité, qui est attribué comme A, B, C à partir du haut du classement à la discrétion de l'auteur. Étant donné que l'ordre de division des frontières est différent chaque mois, considérez-le comme le rang depuis le sommet.
En outre, le taux mensuel est un pourcentage qui montre à quel point le score qui est devenu la frontière qui divise le classement a augmenté par rapport au mois précédent. Cela peut être calculé en divisant le mois en cours par le mois précédent.
Organiser et traiter les données
Même la simple collecte de données de cette manière est un fardeau considérable. Cependant, certains processus de collecte peuvent être automatisés.
Cependant, il existe toujours un besoin d'un processus pour organiser les données, même après qu'elles ont été collectées dans une base de données, par exemple au moyen de capteurs ou d'outils automatisés. Puisqu'il s'agit d'une phase de traitement par des mains humaines, elle ne peut pas être complètement automatisée.
Tout d'abord, visualisez et voyez la tendance générale. Pour le moment, la visualisation des données est un processus de base dans les bases. Quant à la méthode, c'est la base des pandas, donc je ne pense pas qu'elle ait besoin d'être expliquée plus.
df = pd.read_csv("data.csv", index_col=0) #Lisez les données
lines = df.interpolate(method="linear") #Remplissez les données manquantes
plt.figure()
lines.plot() #Tracer le graphique en courbes
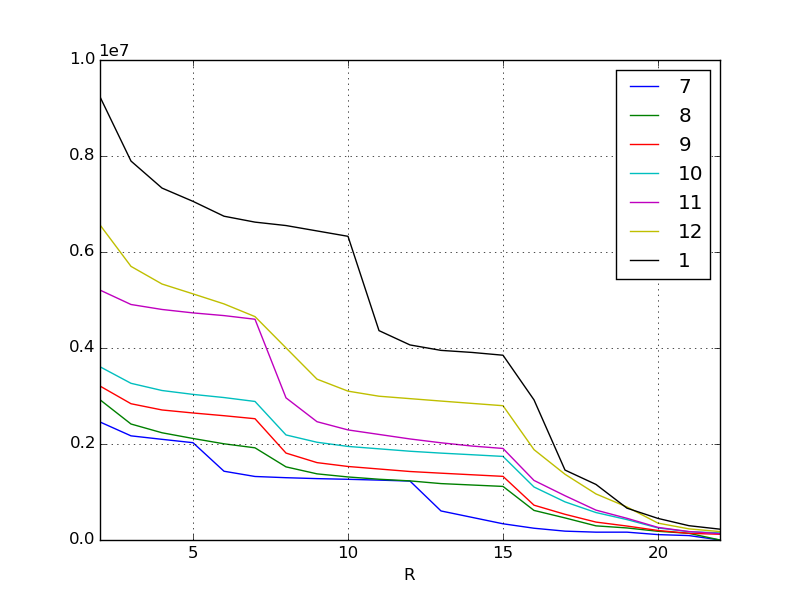
L'axe X est la bordure du classement, donc plus il va vers la gauche. L'axe Y est le score. Chaque ligne représente un mois, mais comme vous pouvez le voir en un coup d'œil à partir des données d'origine, le score requis augmente chaque mois. En particulier, l'inflation la plus récente en janvier et en novembre est incroyable.
Alors que les gens dépensent de plus en plus d'argent et deviennent plus forts, les scores qu'ils gagnent vont naturellement gonfler de plus en plus chaque mois. Je pense que ce genre de phénomène peut être vu dans la plupart des jeux sociaux. Le phénomène a été à nouveau visualisé.
Dans l'exemple ci-dessus, les valeurs manquantes ont été interpolées linéairement. pandas.DataFrame.interpolate peut interpoler et remplir les valeurs manquantes en fonction de divers critères. C'est l'une des puissantes caractéristiques des pandas.
Passez à la deuxième partie.
Recommended Posts