Calibrer le modèle avec PyCaret
introduction
- Lors de la classification par binaire, il est bon de décider du seuil et de classer Pos / Neg.
- Puis-je considérer la valeur de sortie du modèle comme la probabilité de devenir positif? C'est une autre affaire.
- Si vous souhaitez faire ce qui précède, vous devrez peut-être calibrer selon le modèle.
- Je souhaite effectuer cet étalonnage à l'aide de PyCaret.
Faire un modèle
- Suivez le tutoriel de PyCaret pour modéliser avec un arbre de décision comme d'habitude.
- Utilisez l'ensemble de données sur le diabète comme ensemble de données.
Chargement des données
from pycaret.datasets import get_data
diabetes = get_data('diabetes')

Modélisation à l'aide d'un arbre de décision
- Je veux classer, alors importez pycaret.classification.
- Et vous pouvez modéliser en spécifiant dt (arbre de décision) dans create_model.
- Observez le modèle créé avec evalutate_model.
#Importer un package de classification
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
#Créer un arbre de décision
dt = create_model(estimator='dt')
#Visualisation
evaluate_model(dt)
Vérifiez la courbe d'étalonnage avant l'étalonnage
- Cliquez sur le bouton ci-dessous pour vérifier la courbe d'étalonnage.
- L'axe horizontal est l'élément qui a regroupé le résultat de la notation du modèle et l'a arrangé par ordre de valeur.
- L'axe vertical est le pourcentage de données positives qui sont apparues jusqu'à ce bac.
- Dans une situation idéale (*)
- Les données positives apparaissent de manière bien équilibrée par rapport à la valeur de sortie du modèle.
- Le modèle (ligne bleue) s'approche de la ligne diagonale idéale (ligne brisée)
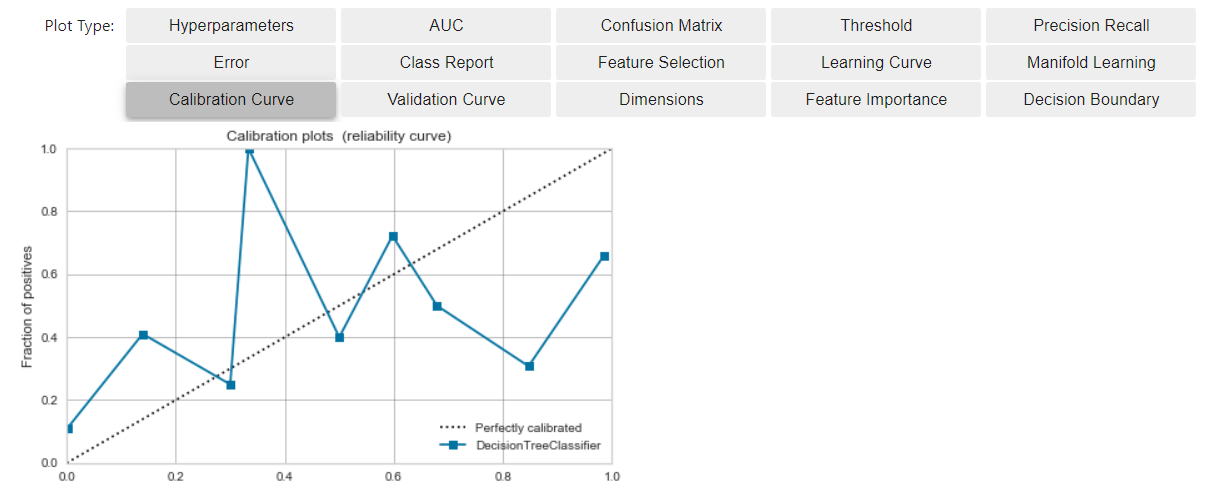
Calibrer le modèle
- Le calibrage est le travail pour rapprocher le modèle actuel de la situation décrite ci-dessus (*). En abordant la situation de * *, il devient plus facile de considérer la valeur de sortie du modèle comme la probabilité que le résultat de la prédiction soit positif.
- Facile à mettre en œuvre, utilisez calibrate_model.
#étalonner
calibrated_dt = calibrate_model(dt)
#Visualiser
evaluate_model(calibrated_dt)
- Par rapport à la fois précédente, le modèle (ligne bleue) est plus proche de la ligne idéale (ligne brisée).
- Pour le résultat de la notation du modèle
- Nous avons pu créer une augmentation linéaire du taux d'apparition cumulé de Positive à ce moment-là (situation proche de *).
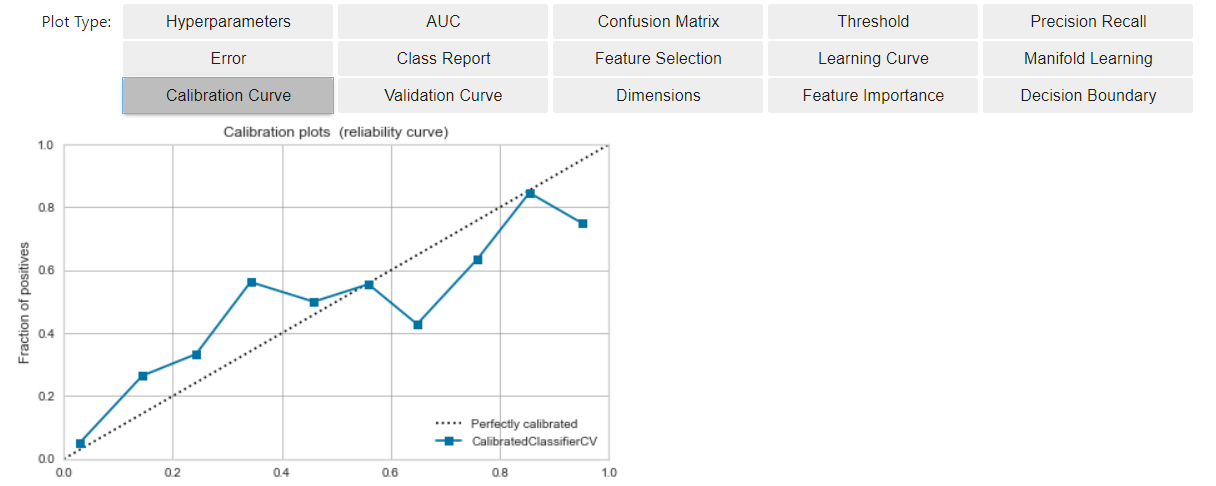
Qu'est-ce que l'étalonnage est effectué?

- Il semble que vous utilisez sklearn.calibration.CalibratedClassifierCV.
- sklearn prend en charge les méthodes de calibrage «sigmoïde» et «isotonique», mais pycaret a un document similaire.
Quel modèle nécessite un étalonnage "Oui?"
-
Puisque SVM maximise la marge, la valeur de sortie du modèle est concentrée à 0,5 et un étalonnage est nécessaire car la zone autour de la limite de décision est strictement vérifiée. Le point est [cet article](https://yukoishizaki.hatenablog.com/entry/2020/05/24/145155#:~:text=SVM%E3%81%AF%E3%83%9E%E3% Il est discuté dans 83% BC% E3% 82% B8% E3% 83% B3% E3% 82% 92% E6% 9C% 80% E5% A4% A7% E5% 8C% 96), mais qu'en est-il des autres? C'est ça?
-
Laissez la discussion rigoureuse sur le modèle à étalonner aux experts, et dans cet article, j'aimerais écrire une courbe d'étalonnage avant et après l'étalonnage et observer quelles sont les tendances.
-
Régression logistique
-
À l'origine, elle peut être interprétée comme une probabilité positive, elle est donc bien équilibrée même avant l'étalonnage.
-
Cela ne change pas beaucoup après l'étalonnage.
-
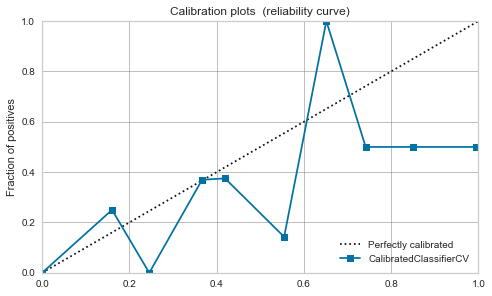
SVM du noyau RBF
-
C'est féroce. Comme mentionné dans l'article ci-dessus, il semble que les données soient proches de 0,5 en maximisant la marge.
-
L'étalonnage ne s'améliore pas beaucoup et il semble dangereux de traiter la valeur de sortie du modèle comme une probabilité.
-
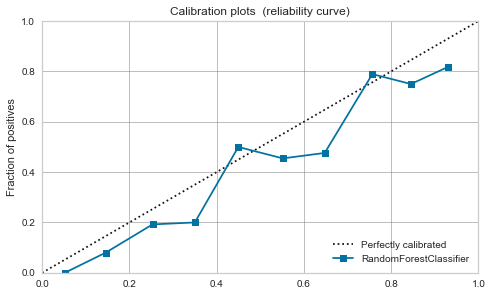
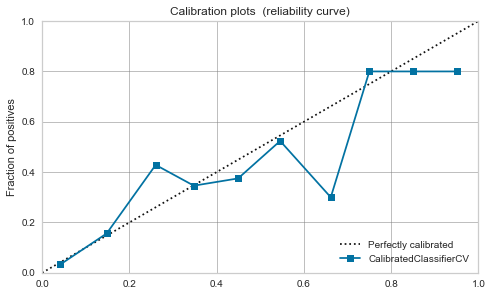
Forêt aléatoire
-
La balance semble être bonne dans une certaine mesure avant même l'étalonnage.
-
Cette fois, en raison de l'étalonnage, un pic est apparu autour de 0,7.
-
XGBoost,LightGBM
-
Modéré même avant l'étalonnage. Si vous le calibrez, il se calmera un peu.
| algorithme | Avant l'étalonnage | Après l'étalonnage |
|---|---|---|
| Logistic Regression |
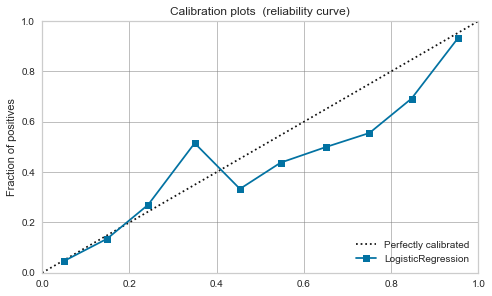 |
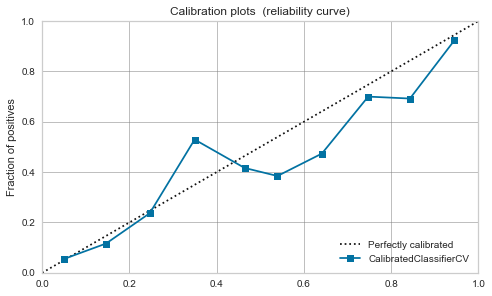 |
| RBF SVM | 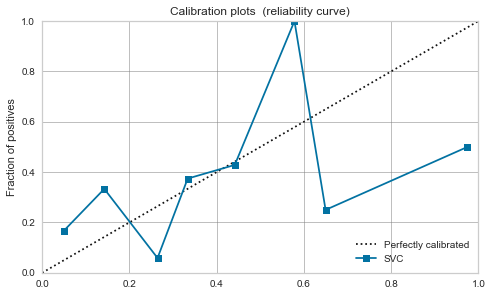 |
 |
| Random Forest |
 |
 |
| XGBoost | 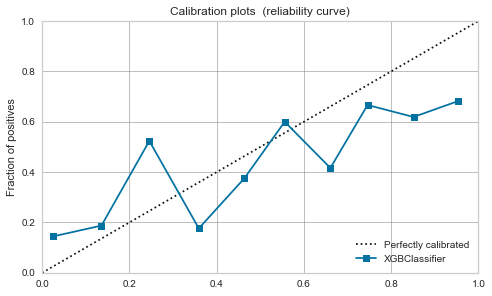 |
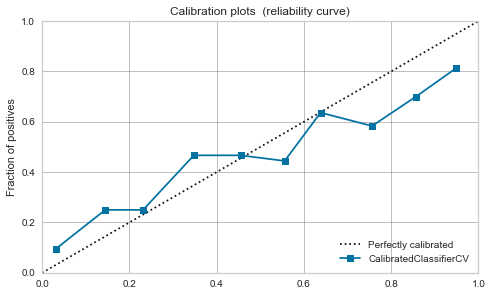 |
| LightGBM | 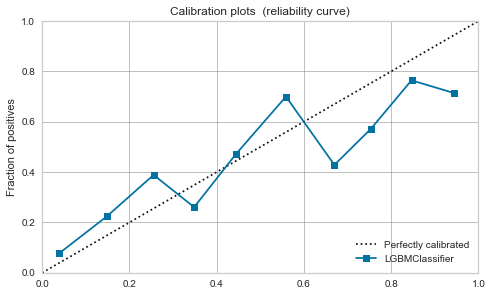 |
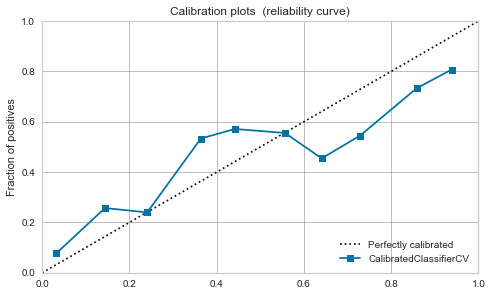 |
finalement
- J'ai essayé de calibrer le modèle avec PyCaret.
- Si vous souhaitez considérer la valeur de sortie du modèle comme une probabilité positive, vous devez vérifier la courbe d'étalonnage.
- Même s'ils sont calibrés, les caractéristiques originales de l'algorithme, telles que la maximisation de la marge de SVM, peuvent être sévères.
- Certains modèles, comme la régression logistique, peuvent être facilement considérés comme des probabilités sans calibration, donc je pense qu'il existe une approche pour les utiliser correctement en fonction de l'application.
Recommended Posts