[JAVA] Créez facilement un S3 virtuel et testez l'intégration entre les services AWS Lambda et S3 dans un environnement local
Préparation préalable
Veuillez installer le kit d'outils AWS pour Eclise avant de l'exécuter. Veuillez consulter le lien ci-dessous pour la procédure d'installation.
-> Procédure d'installation d'AWS Toolkit
Une fois l'installation terminée, le projet AWS doit apparaître sur le nouvel écran de projet.
maven est une prémisse qui a été installée.
Ecrire une fonction Lambda
- Commencez par créer un projet pour les fonctions AWS Lambda Java.
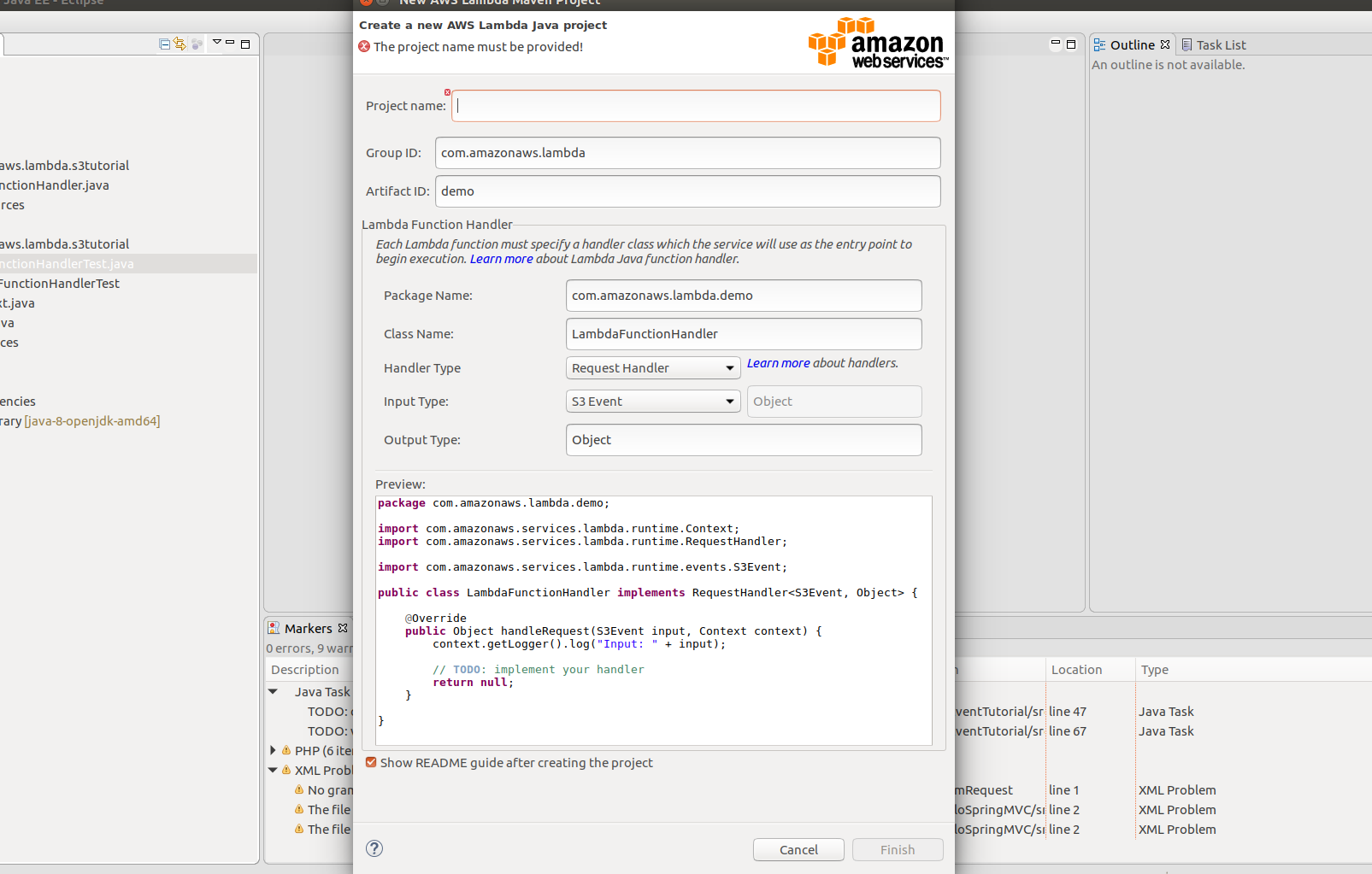 -Nom du projet: S3EventTutorial
-Nom du package: com.amazonaws.lambda.s3tutorial
Gardons les informations essentielles comme ci-dessus. Si vous appuyez sur "Terminer", le projet sera créé et le dossier général du projet ressemblera à ce qui suit.
-Nom du projet: S3EventTutorial
-Nom du package: com.amazonaws.lambda.s3tutorial
Gardons les informations essentielles comme ci-dessus. Si vous appuyez sur "Terminer", le projet sera créé et le dossier général du projet ressemblera à ce qui suit.

- Installez une bibliothèque appelée "s3mock_2.11" dans Maven pour simuler S3. Tout ce que vous avez à faire est de définir les bibliothèques dépendantes dans le fichier pom, veuillez donc vous référer au fichier pom ci-dessous et créer un pom pour votre propre projet.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.amazonaws.lambda</groupId>
<artifactId>s3tutorial</artifactId>
<version>4.0.0</version>
<dependencies>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-core</artifactId>
<version>1.1.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-lambda-java-events</artifactId>
<version>1.3.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.amazonaws</groupId>
<artifactId>aws-java-sdk</artifactId>
<version>1.11.119</version>
<scope>compile</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.typesafe.akka/akka-http-experimental_2.11 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-http-experimental_2.11</artifactId>
<version>2.4.11.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.typesafe.scala-logging/scala-logging_2.11 -->
<dependency>
<groupId>com.typesafe.scala-logging</groupId>
<artifactId>scala-logging_2.11</artifactId>
<version>3.5.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.findify/s3mock_2.11 -->
<dependency>
<groupId>io.findify</groupId>
<artifactId>s3mock_2.11</artifactId>
<version>0.1.10</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.mockito/mockito-core -->
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-core</artifactId>
<version>2.7.22</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.tomakehurst/wiremock -->
<dependency>
<groupId>com.github.tomakehurst</groupId>
<artifactId>wiremock</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
</project>
Il peut y avoir des bibliothèques dépendantes qui ne sont pas dans le référentiel maven dans le local, alors exécutons "mvn package" en tant que ligne de commande dans le dossier racine du projet. Et maven téléchargera la dépendance définie dans pom.
- Logique de la fonction Lambda Ouvrons le LambdaFunctionHandler.java créé et écrivons la logique. L'idée est très simple.
Lorsque vous recevez un événement indiquant qu'un fichier a été téléchargé depuis S3, vous pouvez voir le contenu de l'événement, obtenir le fichier téléchargé et l'écrire sur la console. Si vous regardez le code, vous le comprendrez tout de suite, vous n'aurez donc pas à l'expliquer.
public class LambdaFunctionHandler implements RequestHandler<S3Event, Object> {
private AmazonS3 s3Client;
public LambdaFunctionHandler(AmazonS3 s3Client){
this.s3Client = s3Client;
}
public LambdaFunctionHandler(){
this.s3Client = new AmazonS3Client(new ProfileCredentialsProvider());
}
private static void storeObject(InputStream input) throws IOException {
// Read one text line at a time and display.
BufferedReader reader = new BufferedReader(new InputStreamReader(input));
while (true) {
String line = reader.readLine();
if (line == null)
break;
System.out.println(" " + line);
}
System.out.println();
}
@Override
public Object handleRequest(S3Event input, Context context) {
context.getLogger().log("Input: " + input);
// Simply return the name of the bucket in request
LambdaLogger lambdaLogger = context.getLogger();
S3EventNotificationRecord record = input.getRecords().get(0);
lambdaLogger.log(record.getEventName()); //Nom de l'événement
String bucketName = record.getS3().getBucket().getName();
String key = record.getS3().getObject().getKey();
/*
* Get file to do further operation
*/
try {
lambdaLogger.log("Downloading an object");
S3Object s3object = s3Client.getObject(new GetObjectRequest(bucketName, key));
lambdaLogger.log("Content-Type: " + s3object.getObjectMetadata().getContentType());
storeObject(s3object.getObjectContent());
// Get a range of bytes from an object.
GetObjectRequest rangeObjectRequest = new GetObjectRequest(bucketName, key);
rangeObjectRequest.setRange(0, 10);
S3Object objectPortion = s3Client.getObject(rangeObjectRequest);
System.out.println("Printing bytes retrieved.");
storeObject(objectPortion.getObjectContent());
} catch (AmazonServiceException ase) {
System.out.println("Caught an AmazonServiceException, which" + " means your request made it "
+ "to Amazon S3, but was rejected with an error response" + " for some reason.");
System.out.println("Error Message: " + ase.getMessage());
System.out.println("HTTP Status Code: " + ase.getStatusCode());
System.out.println("AWS Error Code: " + ase.getErrorCode());
System.out.println("Error Type: " + ase.getErrorType());
System.out.println("Request ID: " + ase.getRequestId());
} catch (AmazonClientException ace) {
System.out.println("Caught an AmazonClientException, which means" + " the client encountered "
+ "an internal error while trying to " + "communicate with S3, "
+ "such as not being able to access the network.");
System.out.println("Error Message: " + ace.getMessage());
}catch (IOException ioe){
System.out.println("Caught an IOException, which means" + " the client encountered "
+ "an internal error while trying to " + "save S3 object, "
+ "such as not being able to access the network.");
System.out.println("Error Message: " + ioe.getMessage());
}
return record.getS3().getObject().getKey();
}
}
Créons un cas de test pour le code que nous avons écrit
Cette fois, nous nous concentrerons sur le code Lambda implémenté, alors ouvrez LambdaFunctionHandlerTest et créez un cas de test. Tout d'abord, lisons le code du cas de test.
private static S3Event input;
private static AmazonS3Client client;
@BeforeClass
public static void createInput() throws IOException {
input = TestUtils.parse("s3-event.put.json", S3Event.class);
S3Mock api = S3Mock.create(8999, "/tmp/s3");
api.start();
client = new AmazonS3Client(new AnonymousAWSCredentials());
client.setRegion(Region.getRegion(Regions.AP_NORTHEAST_1));
// use IP endpoint to override DNS-based bucket addressing
client.setEndpoint("http://127.0.0.1:8999");
}
private Context createContext() {
TestContext ctx = new TestContext();
// TODO: customize your context here if needed.
ctx.setFunctionName("Your Function Name");
return ctx;
}
@Test
public void testLambdaFunctionHandlerShouldReturnObjectKey() {
client.createBucket(new CreateBucketRequest("newbucket", "ap-northeast-1"));
ClassLoader classLoader = this.getClass().getClassLoader();
File file = new File(classLoader.getResource("file/test.xml").getFile());
client.putObject(new PutObjectRequest(
"newbucket", "file/name", file));
LambdaFunctionHandler handler = new LambdaFunctionHandler(client);
Context ctx = createContext();
Object output = handler.handleRequest(input, ctx);
if (output != null) {
assertEquals("file/name", output.toString());
System.out.println(output.toString());
}
}
À des fins de test, créez et lancez une instance de S3Mock avec la fonction createInput. Cette instance achètera sur le port 8999 dans votre environnement local et attendra votre demande. Créez un dossier appelé "/ temp / s3" et imitez le stockage du service S3.
Le plus important est le contenu de la fonction testLambdaFunctionHandlerShouldReturnObjectKey. Comme vous pouvez le voir, il implémente les tâches suivantes: --Créez un "seau de test". Remarque: il est obligatoire de spécifier la région (s'il n'y a rien d'autre dans la région, java.lang.NoSuchMethodError: com.amazonaws.regions.RegionUtils.getRegionByEndpoint (Ljava / lang / String;) Lcom / amazonaws / J'obtiens une erreur appelée régions / région;, qui est un bogue AWS) --Téléchargez le fichier / test.xml créé dans le dossier de ressources sous le projet vers le stockage temporaire --Téléchargez le fichier téléchargé à partir du S3 temporaire et vérifiez le contenu.
Puisque le déclencheur est le contenu de l'événement défini dans "s3-event.put.json", les informations du fichier téléchargé doivent être reflétées dans le contenu de "s3-event.put.json".
{
"Records": [
{
"eventVersion": "2.0",
"eventSource": "aws:s3",
"awsRegion": "us-east-1",
"eventTime": "1970-01-01T00:00:00.000Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "EXAMPLE"
},
"requestParameters": {
"sourceIPAddress": "127.0.0.1"
},
"responseElements": {
"x-amz-request-id": "",
"x-amz-id-2": "FMyUVURIY8//JRWeUWerMUE5JgHvANOjpD"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "testConfigRule",
"bucket": {
"name": "testbucket",
"ownerIdentity": {
"principalId": "EXAMPLE"
},
"arn": "arn:aws:s3:::mybucket"
},
"object": {
"key": "file/name",
"size": 1024,
"eTag": "d41d8cd98f00b204e9800998ecf8427e"
}
}
}
]
}
Remarque: le nom du compartiment et la clé d'objet sont les plus importants. Comme vous pouvez le voir, le fichier a été téléchargé sur testbuck avec le fichier / nom clé, le contenu de json est donc exprimé en conséquence.
#la fin
Je l'ai expliqué dans le projet, mais si vous avez des questions, veuillez nous contacter.
Recommended Posts