Regardez de plus près le tutoriel Kaggle / Titanic
introduction
J'ai essayé Tutorial de Kaggle's Titanic. Aléatoire par copier-coller J'ai pu faire des prédictions en utilisant la forêt, mais avant de passer à l'étape suivante, j'ai vérifié ce que je faisais dans le tutoriel. Vous pouvez trouver beaucoup de commentaires Titanic de Kaggle sur le net, mais voici un résumé de ce que j'ai pensé avec le tutoriel.
Vérifiez les données
head()
Dans Tutoriel, après avoir lu les données, nous utilisons head () pour vérifier les données.
train_data.head()

test_data.head()

Bien sûr, test_data n'a pas de terme Survived.
describe()
Vous pouvez voir les statistiques des données avec describe (). Vous pouvez afficher les données de l'objet avec describe (include = 'O').
train_data.describe()
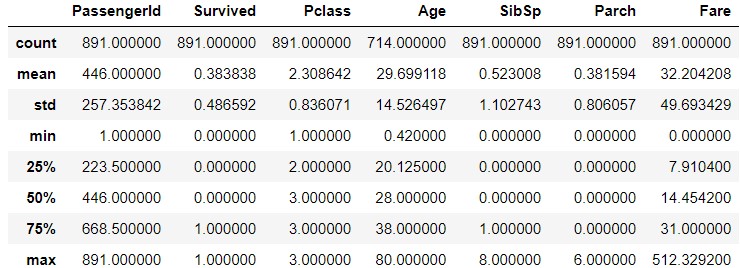
train_data.describe(inlude='O')
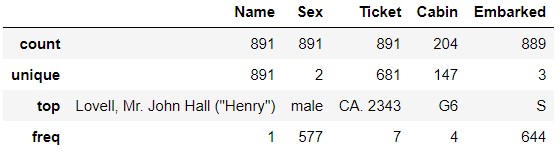
Si vous regardez le "Ticket", vous verrez que "CA.2343" apparaît sept fois. Cela signifie-t-il que vous êtes un membre de la famille ou quelque chose et que vous avez un ticket avec le même numéro? De même, dans "Cabine", " G6 »est apparu quatre fois. Cela signifie-t-il qu'il y a quatre personnes dans la même pièce? Je suis curieux de savoir si la même famille et les mêmes personnes dans la même pièce ont partagé leur sort.
test_data.describe()
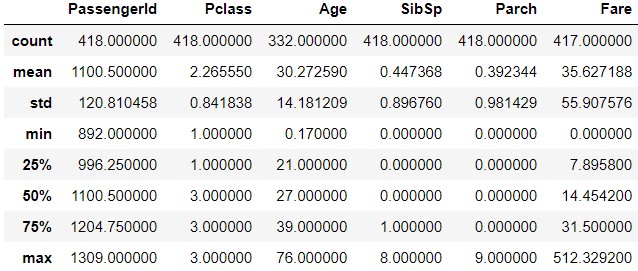
test_data.describe(include='O')
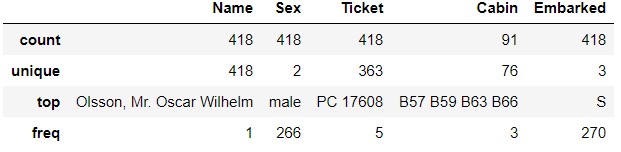 Du côté
Du côté test_data, PC 17608 apparaît 5 fois dans Ticket . B57 B59 B63 B66 apparaît 3 fois dans Cabin.
info()
Vous pouvez également obtenir des informations sur les données avec info ().
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
Vous pouvez voir que le nombre de lignes de données est de 891, mais seulement 714 pour «Âge», 204 pour «Cabine» et 889 pour «Embarqué» (désolé!).
test_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 418 non-null int64
1 Pclass 418 non-null int64
2 Name 418 non-null object
3 Sex 418 non-null object
4 Age 332 non-null float64
5 SibSp 418 non-null int64
6 Parch 418 non-null int64
7 Ticket 418 non-null object
8 Fare 417 non-null float64
9 Cabin 91 non-null object
10 Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
Dans test_data, les données manquantes sont Age, Fare, Cabin. Dans train_data, il y avait des données manquantes dans Embarked, mais dans test_data, elles sont complètes. , Fare était aligné dans train_data, mais il en manque un dans test_data.
corr (); Voir corrélation de données
Vous pouvez vérifier la corrélation de chaque donnée avec `corr ().
train_corr = train_data.corr()
train_corr
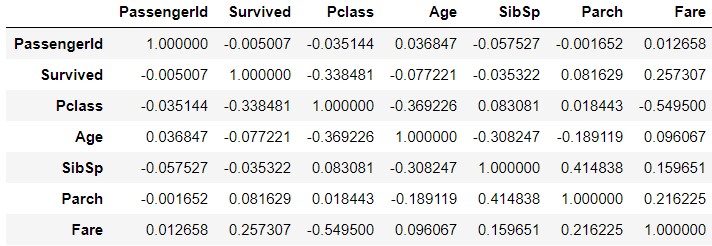
Visualisez en utilisant «seaborn».
import seaborn
import matplotlib.pyplot as plt
seaborn.heatmap(train_data_map_corr, annot=True, vmax=1, vmin=-1, center=0)
plt.show()
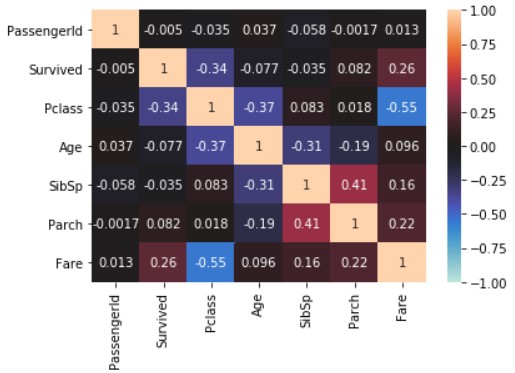
Ce qui précède ne reflète pas les données du type d'objet. Remplacez donc les symboles «Sexe» et «Embarqué» par des nombres et faites de même. Lors de la copie des données, explicitement «copy () Créez une autre donnée en utilisant `.
train_data_map = train_data.copy()
train_data_map['Sex'] = train_data_map['Sex'].map({'male' : 0, 'female' : 1})
train_data_map['Embarked'] = train_data_map['Embarked'].map({'S' : 0, 'C' : 1, 'Q' : 2})
train_data_map_corr = train_data_map.corr()
train_data_map_corr
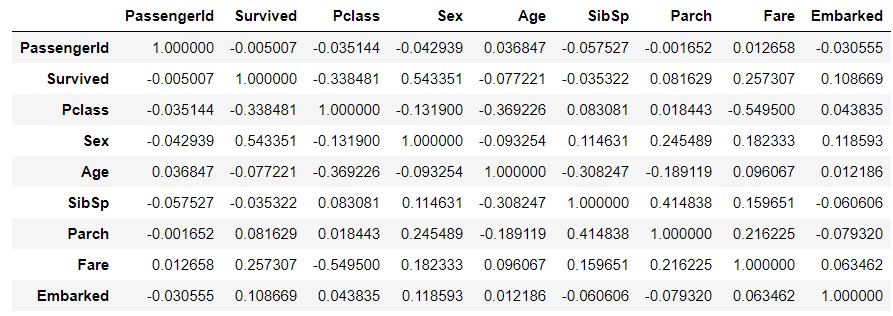
seaborn.heatmap(train_data_map_corr, annot=True, vmax=1, vmin=-1, center=0)
plt.show()
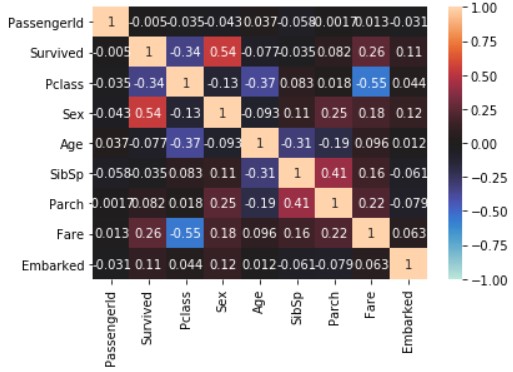
Concentrez-vous sur la ligne «Survived». Dans le didacticiel, nous avons appris avec «Pclass», «Sex», «SibSp», «Parch», mais «Age», «Fare» et «Embarked» sont également avec «Survived». Corrélation élevée.
Apprentissage
get_dummies()
from sklearn.ensemble import RandomForestClassifier
y = train_data["Survived"]
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])
Apprenez à utiliser scikit-learn. Il y a quatre quantités de fonctionnalités à utiliser, telles que définies dans features: Pclass, Sex, SibSp et Parch (fonctions sans défauts). ..
Les données utilisées pour l'entraînement sont traitées par pd.get_dummies . Pd.get_dummies convertit ici la variable de type d'objet en une variable factice.
train_data[features].head()
X.head()
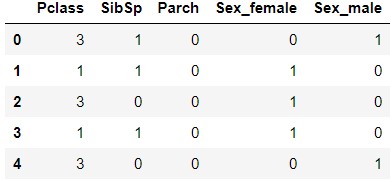
Vous pouvez voir que la quantité de fonctionnalités «Sex» a changé en «Sex_female» et «Sex_male».
RandomForestClassfier()
Apprenez à utiliser l'algorithme de forêt aléatoire RandomForestClassifier ().
model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)
Vérifiez les paramètres de RandomForestClassifier (la description concerne environ)
| Paramètres | Explication |
|---|---|
| n_estimators | Nombre d'arbres déterminés.La valeur par défaut est 10 |
| max_depth | Valeur maximale de la profondeur de l'arbre déterminé.La valeur par défaut est Aucun(Approfondir jusqu'à ce qu'il soit complètement séparé) |
| max_features | Pour une division optimale,Combien de fonctionnalités à considérer.La valeur par défaut estautodonc, n_featuresDevenir la racine carrée de |
Même s'il n'y a que 4 fonctionnalités (5 variables fictives), la création de 100 arbres de décision semble être un dépassement, ce qui sera vérifié ultérieurement.
Vérifiez le modèle obtenu
score
print('Train score: {}'.format(model.score(X, y)))
Train score: 0.8159371492704826
Le modèle lui-même convient à 0.8159 (pas si cher).
feature_importances_ Vérifiez l'importance de la quantité de caractéristiques (notez l'endroit où le pluriel s est attaché)
x_importance = pd.Series(data=model.feature_importances_, index=X.columns)
x_importance.sort_values(ascending=False).plot.bar()
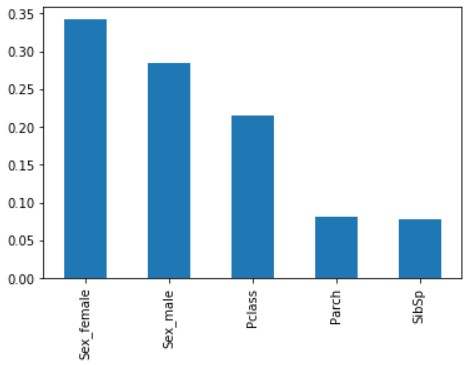
«Sex» («Sex_female» et «Sex_male») sont d'une grande importance, suivis de «Pclass». «Parch» et «SibSp» sont tout aussi bas.
Affichage de l'arbre de décision (dtreeviz)
Visualisez le type d'arbre de décision qui a été fait.
Installation
(Référence; Procédure d'installation de dtreeviz et grahviz pour visualiser le résultat de la forêt aléatoire Python)
Supposons que Windows10 / Anaconda3. D'abord, utilisez pip et conda pour installer le logiciel nécessaire.
> pip install dtreeviz
> conda install graphviz
Dans mon cas, j'ai eu l'erreur "Impossible d'écrire" avec conda. Redémarrez Anaconda en mode administrateur (faites un clic droit sur Anaconda et sélectionnez" *** Démarrer en mode administrateur *** " Sélectionnez et démarrez), exécutez conda.
Après cela, ajoutez le dossier contenant «dot.exe» à «PATH» dans l'environnement système.
> dot -V
dot - graphviz version 2.38.0 (20140413.2041)
Si vous pouvez exécuter dot.exe comme ci-dessus, c'est OK.
Affichage de l'arbre de décision
from dtreeviz.trees import dtreeviz
viz = dtreeviz(model.estimators_[0], X, y, target_name='Survived', feature_names=X.columns, class_names=['Not survived', 'Survived'])
viz

Je suis accro à *** dans l'argument de dtreeviz, les éléments suivants.
--model.estimators_ [0] ; Si vous ne spécifiez pas[0], une erreur se produira. Etant donné qu'un seul des multiples arbres de décision sera affiché, spécifiez-le avec[0]etc.
--feature_names; Initialement, features a été spécifié, mais une erreur. En fait, comme il a été transformé en variable factice avecpd.dummies ()pendant l'apprentissage, X.columns après l'avoir transformé en variable factice Spécifier
J'ai été un peu impressionné lorsque j'ai pu afficher correctement l'arbre de décision.
finalement
En regardant attentivement le contenu des données et les paramètres de la fonction, j'ai en quelque sorte compris ce que je faisais. Ensuite, je voudrais augmenter le score autant que possible en modifiant les paramètres et en augmentant les fonctionnalités.
référence
--Vérifiez les données
- Présentation des données avec Pandas
- [Python] [Apprentissage automatique] Les débutants sans aucune connaissance essaient l'apprentissage automatique pour le moment
- Fonctionnalités Pandas utiles pour l'analyse des données Titanic --Apprentissage
- Convertir les variables catégorielles en variables factices avec pandas (get_dummies)
- Forêt aléatoire par Scikit-learn
- Créer un graphique avec la méthode plot des pandas et visualiser les données
- Prédire le no-show pour les rendez-vous de consultation dans la forêt aléatoire de Python scikit-learn
- Procédure d'installation de dtreeviz et grahviz pour visualiser le résultat de la forêt aléatoire Python
Recommended Posts