Créez un arbre de décision à partir de 0 avec Python et comprenez-le (5. Entropie des informations)
** Créer et comprendre des arbres de décision à partir de zéro en Python ** 1. Présentation-2. Bases du programme Python-3. Données Analysis Library Pandas-4. Structure de données --5 Information Entropy
Pour l'apprentissage de l'IA (machine learning) et de l'exploration de données, nous comprendrons en créant un arbre de décision à partir de zéro en Python.
5.1 Entropie d'information (quantité moyenne d'informations)
Lors de la création d'un arbre de décision à partir de données, l'algorithme ID3 utilise un index appelé entropie d'information pour déterminer quel attribut doit être utilisé pour le branchement afin de distribuer les données le plus efficacement.
Tout d'abord, nous définissons le concept de quantité d'informations. Intuitivement, la quantité d'informations = la complexité des données. Dans l'arbre de décision, au fur et à mesure que l'arbre se ramifie, les données de la même valeur de classe sont collectées, c'est-à-dire que la complexité de la valeur de classe diminue. Par conséquent, lors de l'examen de l'attribut à utiliser pour le branchement, il suffit de juger par la simplicité des données divisées.
5.1.1 Définition de la quantité d'informations
La quantité d'informations est similaire à la valeur des informations acquises, et on suppose que la quantité d'informations sur un événement avec une faible probabilité d'occurrence, par exemple, qu'il se produise, est plus grande que la quantité d'informations sur un événement avec une forte probabilité d'occurrence.
Par exemple, il est plus informatif lorsque vous connaissez la réponse à une question à cinq choix que lorsque vous connaissez la réponse à une question à deux choix.
Ensuite, pour transmettre l'événement à d'autres, supposons qu'il soit codé en un nombre binaire et envoyé à une ligne de communication. La quantité de communication (longueur en bits) à ce moment est définie comme la quantité d'informations.
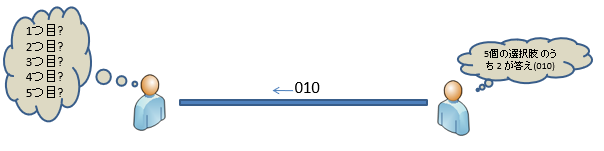
Lorsque la probabilité que l'événement E se produise est P (E), la quantité d'informations I (E) qui sait que l'événement E s'est produit est définie comme suit.
I(E) = log_2(1/P(E)) = -log_2P(E)
5.1.2 Qu'est-ce que l'entropie d'information (quantité moyenne d'informations)?
Un attribut a plusieurs valeurs d'attribut. Par exemple, il existe trois types d'attributs météorologiques: ensoleillé, nuageux et pluvieux. La valeur moyenne dans l'attribut de la quantité d'informations obtenue à partir de chaque probabilité d'occurrence est appelée entropie (quantité moyenne d'informations).
Il est représenté par H dans la formule suivante.
H = -\sum_{E\in\Omega} P(E)\log_2{P(E)}
Par exemple, l'entropie de deux attributs comme indiqué dans la figure suivante est calculée comme suit. Le côté gauche plus mélangé et chaotique a une entropie plus élevée, et le côté droit à dominance noire a une entropie plus faible que le gauche.
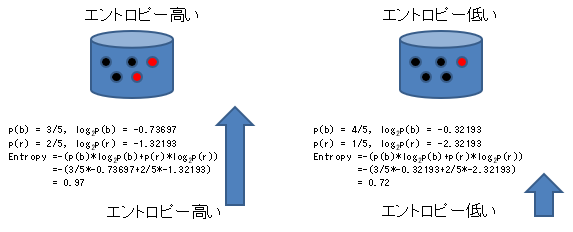
Cependant, même si vous n'utilisez pas de formules compliquées, dans le cas de l'exemple ci-dessus, il semble que la complexité soit requise en regardant le nombre de noirs. Cependant, si l'on considère, par exemple, le cas d'une valeur à trois avec du jaune ajouté, l'entropie de l'information, qui peut être calculée de la même manière pour deux valeurs et trois valeurs, a l'aspect d'être plus unifiée et plus facile à manipuler.
Dans l'exemple ci-dessous, on calcule que le nombre de noirs est le même, mais l'entropie est plus élevée lorsque le reste est divisé en rouge et jaune que lorsque le reste n'est que rouge.
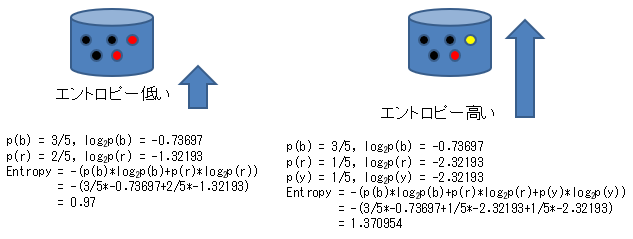
Cet algorithme ID3 est un algorithme qui recherche des valeurs d'attribut qui divisent les données en groupes avec une entropie plus faible.
5.2 Calcul de l'entropie de l'information
L'entropie d'information peut être calculée par l'expression lambda suivante avec DataFrame en entrée et le nombre d'entropie en sortie.
entropy = lambda df:-reduce(lambda x,y:x+y,map(lambda x:(x/len(df))*math.log2(x/len(df)),df.iloc[:,-1].value_counts()))
C'est parce que l'expression lambda est en outre incluse dans l'expression lambda, donc je vais l'organiser un peu et l'afficher comme suit.
entropy = lambda df:-reduce( #4.réduire crée une valeur à partir de tous les éléments du tableau.
lambda x,y:x+y,#5.Valeurs individuelles(9,5)Ajoutez l'entropie obtenue à partir de.
map( #2.Tableau de fréquences(["○":9,"×":5])Nombre de(9,5)Entropier avec la formule lamda suivante
lambda x:(x/len(df))*math.log2(x/len(df)),#3.P(E)log2(P(E))Calculer
df.iloc[:,-1].value_counts() #1.Fréquence de la dernière colonne du DataFrame (par exemple:["○":9,"×":5])
)
)
Cette expression est traitée dans l'ordre suivant:
- df.iloc [:, -1] extrait la dernière colonne du DataFrame, et value_counts donne sa distribution de fréquence (exemple de distribution de fréquence: ["○": 9, "×": 5]).
- map convertit chacun des nombres de distribution de puissance (par exemple 9,5) en valeurs d'entropie.
- (x / len (df)) * math.log2 (x / len (df)) calcule l'expression $ P (E) \ log_2 {P (E)} $ pour une entropie.
- Utilisez réduire pour créer une valeur unique à partir de tous les éléments d'un tableau. Par exemple, il peut être utilisé pour calculer des sommes, des moyennes, etc.
- L'expression lamda x, y: x + y donne la somme des deux arguments (x, y), c'est-à-dire la somme des tableaux. C'est la partie sigma de la formule d'entropie ($ - \ sum_ {E \ in \ Omega} P (E) \ log_2 {P (E)} $). Puisque l'expression a un moins au début, elle a également un moins avant la réduction du programme.
5.2.1 Exemple de calcul
L'entropie d'information pour les données suivantes est 0,9402859586706309.
d = {"le golf":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"]}
#L'entropie est 0.9402859586706309
D'autre part, si les deux premiers x sont modifiés en 0 et que 0 devient la donnée dominante (la complexité est réduite), l'entropie est de 0,74959525725948.
d = {"le golf":["○","○","○","○","○","×","○","×","○","○","○","○","○","×"]}
#L'entropie est 0.74959525725948
Voici une liste de tous les programmes qui calculent l'entropie de l'information.
import pandas as pd
from functools import reduce
import math
d = {"le golf":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"]}
df0 = pd.DataFrame(d)
entropy = lambda df:-reduce(
lambda x,y:x+y,
map(
lambda x:(x/len(df))*math.log2(x/len(df)),
df.iloc[:,-1].value_counts()
)
)
print(entropy(df0)) #Sortie 0.9402859586706309
Recommended Posts