100 Language Processing Knock 2020 Chapter 4: Morphological Analysis
The other day, 100 Language Processing Knock 2020 was released. I myself have only been in natural language processing for a year, and I don't know the details, but I will solve all the problems and publish them in order to improve my technical skills.
All shall be executed on jupyter notebook, and the restrictions of the problem statement may be broken conveniently. The source code is also on github. Yes.
Chapter 3 is here.
The environment is Python 3.8.2 and Ubuntu 18.04.
Chapter 4: Morphological analysis
Use MeCab to morphologically analyze the text (neko.txt) of Natsume Soseki's novel "I am a cat" and save the result in a file called neko.txt.mecab. Use this file to implement a program that addresses the following questions.
Please download the required dataset from here.
The downloaded file shall be placed under data.
Morphological analysis using MeCab
code
mecab < data/neko.txt > data/neko.txt.mecab
You can get a file with contents like this
One noun,number,*,*,*,*,one,Ichi,Ichi
EOS
EOS
symbol,Blank,*,*,*,*, , ,
I noun,Pronoun,General,*,*,*,I,Wagamama,Wagamama
Is a particle,Particle,*,*,*,*,Is,C,Wow
Cat noun,General,*,*,*,*,Cat,cat,cat
Auxiliary verb,*,*,*,Special,Continuous form,Is,De,De
Auxiliary verb,*,*,*,Five steps, La line Al,Uninflected word,is there,Al,Al
.. symbol,Kuten,*,*,*,*,。,。,。
30. Reading morphological analysis results
Implement a program that reads the morphological analysis result (neko.txt.mecab). However, each morpheme is stored in a mapping type with the surface, uninflected word, part of speech (pos), and part of speech subclassification 1 (pos1) as keys, and one sentence is expressed as a list of morphemes (mapping type). Let's do it. For the rest of the problems in Chapter 4, use the program created here.
Prepare a function to extract surface form, uninflected word, part of speech, and part of speech subclassification 1 from each line of MeCab output. Returns None when it hits the end of the sentence.
code
def line_to_dict(line):
line = line.rstrip()
if line == 'EOS':
return None
lst = line.split('\t')
pos = lst[1].split(',')
dct = {
'surface' : lst[0],
'pos' : pos[0],
'pos1' : pos[1],
'base' : pos[6],
}
return dct
We will convert the output of MeCab to the list of outputs of the above function.
code
def mecab_to_list(text):
lst = []
tmp = []
for line in text.splitlines():
dct = line_to_dict(line)
if dct is not None:
tmp.append(dct)
elif tmp:
lst.append(tmp)
tmp = []
return lst
code
with open('data/neko.txt.mecab') as f:
neko = mecab_to_list(f.read())
output(First 3 elements)
[[{'surface': 'one', 'pos': 'noun', 'pos1': 'number', 'base': 'one'}],
[{'surface': '\u3000', 'pos': 'symbol', 'pos1': 'Blank', 'base': '\u3000'},
{'surface': 'I', 'pos': 'noun', 'pos1': '代noun', 'base': 'I'},
{'surface': 'Is', 'pos': 'Particle', 'pos1': '係Particle', 'base': 'Is'},
{'surface': 'Cat', 'pos': 'noun', 'pos1': 'General', 'base': 'Cat'},
{'surface': 'so', 'pos': 'Auxiliary verb', 'pos1': '*', 'base': 'Is'},
{'surface': 'is there', 'pos': 'Auxiliary verb', 'pos1': '*', 'base': 'is there'},
{'surface': '。', 'pos': 'symbol', 'pos1': 'Kuten', 'base': '。'}],
[{'surface': 'name', 'pos': 'noun', 'pos1': 'General', 'base': 'name'},
{'surface': 'Is', 'pos': 'Particle', 'pos1': '係Particle', 'base': 'Is'},
{'surface': 'yet', 'pos': 'adverb', 'pos1': 'Particle connection', 'base': 'yet'},
{'surface': 'No', 'pos': 'adjective', 'pos1': 'Independence', 'base': 'No'},
{'surface': '。', 'pos': 'symbol', 'pos1': 'Kuten', 'base': '。'}]]
31. Verb
Extract all the surface forms of the verb.
code
surfaces_of_verb = {
dct['surface']
for sent in neko
for dct in sent
if dct['pos'] == 'verb'
}
for _, verb in zip(range(10), surfaces_of_verb):
print(verb)
print('total:', len(surfaces_of_verb))
output
Self-esteem
Welling up
Bulge
Let go
play
To
Hold out
Dirt
Hit
Working
total: 3893
32. The original form of the verb
Extract all the original forms of the verb.
code
bases_of_verb = {
dct['base']
for sent in neko
for dct in sent
if dct['pos'] == 'verb'
}
for _, verb in zip(range(10), bases_of_verb):
print(verb)
print('total:', len(bases_of_verb))
output
Suku
fade away
play
Dawn
Stand out
Hit
Appear
Tomorrow
Fill
Swing
total: 2300
33. "B of A"
Extract a noun phrase in which two nouns are connected by "no".
code
def tri_grams(sent):
return zip(sent, sent[1:], sent[2:])
def is_A_no_B(x, y, z):
return x['pos'] == z['pos'] == 'noun' and y['base'] == 'of'
A_no_Bs = {
''.join([x['surface'] for x in tri_gram])
for sent in neko
for tri_gram in tri_grams(sent)
if is_A_no_B(*tri_gram)
}
for _, phrase in zip(range(10), A_no_Bs):
print(phrase)
print('total:', len(A_no_Bs))
Take a tri-gram and extract only those that are "noun + + noun". The double loop is rotated by the list comprehension method.
result
My place
Tuna fillet
House sprout
The second king
Ushigome Yamabushi
Questions and answers on the left
Cat paw
Visitors
Old man
Other than
total: 4924
34. Noun articulation
Extract the concatenation of nouns (nouns that appear consecutively) with the longest match.
code
def longest_nouns(sent):
lst = []
tmp = []
for dct in sent:
if dct['pos'] == 'noun':
tmp.append(dct['surface'])
else:
if len(tmp) > 1:
lst.append(tmp)
tmp = []
return lst
noun_chunks = [
''.join(nouns)
for sent in neko
for nouns in longest_nouns(sent)
]
for _, chunk in zip(range(10), noun_chunks):
print(chunk)
print('total:', len(noun_chunks))
A loop is turned for each sentence to extract the part where the nouns are continuous. The appearance of only one noun was not considered concatenation.
output
In humans
The worst
Timely
One hair
Then the cat
one time
Puupuu and smoke
Inside the mansion
Calico
Other than student
total: 7335
35. Frequency of word occurrence
Find the words that appear in the sentence and their frequency of appearance, and arrange them in descending order of frequency of appearance.
code
from collections import Counter
code
surfaces = [
dct['surface']
for sent in neko
for dct in sent
]
cnt = Counter(surfaces).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
You just counted the number with Counter.
output
9194
。 7486
6868
、 6772
Is 6420
To 6243
6071
And 5508
Is 5337
3988
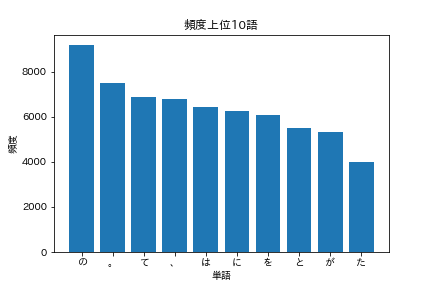
36. Top 10 most frequent words
Display the 10 words that appear frequently and their frequency of appearance in a graph (for example, a bar graph).
code
import matplotlib.pyplot as plt
import japanize_matplotlib
I want to use matplotlib, but Japanese is not displayed well with this alone. Importing japanize_matplotlib works fine.
code
words = [word for word, _ in cnt[:10]]
freqs = [freq for _, freq in cnt[:10]]
plt.bar(words, freqs)
plt.title('Top 10 most frequent words')
plt.xlabel('word')
plt.ylabel('frequency')
plt.show()
You should see a graph like the one below.
37. Top 10 words that frequently co-occur with "cat"
Display 10 words that often co-occur with "cat" (high frequency of co-occurrence) and their frequency of appearance in a graph (for example, a bar graph).
Words that "co-occur" are considered to appear in the same sentence.
code
co_occured = []
for sent in neko:
if any(dct['base'] == 'Cat' for dct in sent):
words = [dct['base'] for dct in sent if dct['base'] != 'Cat']
co_occured.extend(words)
cnt = Counter(co_occured).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
output
391
Is 272
、 252
To 250
232
231
229
。 209
And 202
Is 180
To be honest, it's boring with only particles, so I'll limit the part of speech.
code
co_occured = []
for sent in neko:
if any(dct['base'] == 'Cat' for dct in sent):
words = [
dct['base']
for dct in sent
if dct['base'] != 'Cat'
and dct['pos'] in {'noun', 'verb', 'adjective', 'adverb'}
]
co_occured.extend(words)
cnt = Counter(co_occured).most_common()
for _, (word, freq) in zip(range(10), cnt):
print(word, freq)
output
144
* 63
Thing 59
I 58
58
There 55
55
Human 40
Not 39
Say 38
Let's take a look at some sentences in which cats and humans co-occur.
code
for sent in neko[:1000]:
if any(dct['base'] == 'Cat' for dct in sent) and any(dct['base'] == 'Human' for dct in sent):
lst = [dct['surface'] for dct in sent]
print(''.join(lst))
code
Mr. Shiro shed tears and told the whole story, and it is said that in order for our cats to complete the love of parents and children and lead a beautiful family life, we must fight humans and destroy them. It was.
However, unfortunately, humans are left as they are because they are animals that have not been bathed in the blessings of heaven to the extent that they can understand the language of the genus Felis.
I'd like to say a little to the reader, but it's not good that human beings have a habit of evaluating me with a disdainful tone, like cats.
It may be common for teachers who are aware of their ignorance and have a proud face to think that cows and horses are made from human dregs and cats are made from cow and horse droppings. However, it's not a very nice person to look at.
In the other side, there is no single line, equality and indiscrimination, and it seems that none of the cats have their own unique characteristics, but when you crawl into the cat society, it is quite complicated and the word of the human world of ten people and ten colors remains as it is. It can also be applied here.
Looking at this, humans may be superior to cats in the sense of fairness determined from selfishness, but wisdom seems to be inferior to cats.
It may be necessary for a person like the master who has both sides to write in a diary and show his own face that is not shown to the world in the dark room, but when it comes to our felis genus, it is genuine It's a diary, so I don't think it's enough to take such troublesome steps and save my seriousness.
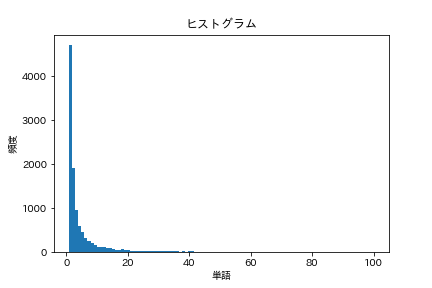
38. Histogram
Draw a histogram of the frequency of occurrence of words (the horizontal axis represents the frequency of occurrence and the vertical axis represents the number of types of words that take the frequency of occurrence as a bar graph).
code
words = [
dct['base']
for sent in neko
for dct in sent
]
cnt = Counter(words).most_common()
freqs = [freq for _, freq in cnt]
plt.title('histogram')
plt.xlabel('word')
plt.ylabel('frequency')
plt.hist(freqs, bins=100, range=(1,100))
plt.show()
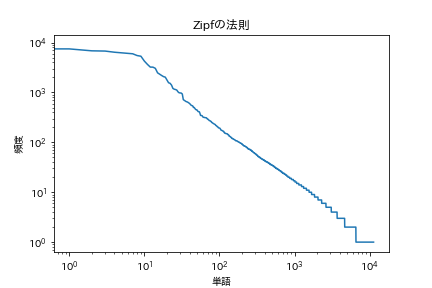
39. Zipf's Law
Plot a log-log graph with the frequency of occurrence of words on the horizontal axis and the frequency of occurrence on the vertical axis.
[Zip's Law](https://en.wikipedia.org/wiki/%E3%82%B8%E3%83%83%E3%83%97%E3%81%AE%E6%B3%95%E5 % 89% 87)
code
plt.title('Zipf's law')
plt.xlabel('word')
plt.ylabel('frequency')
plt.xscale('log')
plt.yscale('log')
plt.plot(range(len(freqs)), freqs)
plt.show()
It looks like that.
Next is Chapter 5
Language processing 100 knocks 2020 Chapter 5: Dependency analysis
Recommended Posts