Big data analysis using the data flow control framework Luigi
What is Luigi
Luigi is a data flow control framework written in Python. Developed by Spotify, a major streaming music distribution company. The partnership with Sony also became a hot topic.
- Luigi Official Repository
- Presentation material of the head family is easy to understand.
Generally, in big data analysis, it is necessary to perform a number of cleansing and filtering processes before performing statistical and machine learning. The dependencies are complicated, and when you start replacing data or redoing when a failure or interruption occurs, it is nothing more than a penance. Luigi can be used in such a case.
The origin of the name Luigi is that the data flow is likened to a water pipe, "a plumber wearing the second most famous green clothes in the world". Maybe it's green instead of red because it's the same as Spotify's corporate color (laughs).
Although it is Python, it is easy to combine it with Hadoop and Treasure Data as well as processing with Python. It is a super powerful tool that has all the functions you want for data analysis. However, it seems that the recognition in Japan is not so high yet. Therefore, I would like to introduce it for missionary purposes.
Major features
- Can write data processing tasks in an object-oriented manner
- Resolve the dependency between tasks from downstream to upstream
- If an error occurs, it will stop there
- Easy to resume from where it failed
- Ensuring idempotency by determining the end of a task based on the presence or absence of an output object
- It works like a cache when a task that refers to the same data is executed.
- Easy to externalize parameters in data processing
- Perfect cooperation with database engine and Hadoop (HDFS, MapReduce Streaming, Hive, Spark!)
- Data flow dependencies and progress can be visualized with a web browser
- Has a command line interface (quite rich)
- If you throw it in git as it is, you can manage the version well
- Easy to write tests because it is a Python class itself
Anyway, it's all good. The only regrettable thing is that you can't activate the process from the browser. Also, the manual around Hadoop is undeveloped, and I have to read the source to understand the specifications.
Introduction method
sudo pip install luigi
This is all you need to enter.
How to write
The minimum unit of processing is Task
The smallest unit of Luigi processing is called Task and is managed. 1 Write a class that inherits the luigi.Task () class for Task.
How to describe the dependency between Tasks
Luigi describes a chain of data flows by linking it from downstream to upstream.
The luigi.Task () class has the following methods as a method.
requires (): Dependent upstream Task- ʻOutput ()
: Output object (file name wrapped inluigi.Target ()` family class) run (): Processing in Task

This way, you don't have to mess around with dependencies. Also, you don't have to write the file twice, on the dependent side and on the dependent side.
When executing, call the most downstream Task. By doing this, Luigi will automatically resolve the dependency upstream and execute it in order. At this time, if you set multiple --workers options, the parts that can be parallelized will be automatically executed in parallel.
Illustration
From here, Luigi's official sample, top_artists.py Let's see how to write using) as an example.
This is a script that mimics the daily aggregation of artist views. The playback logs of songs are aggregated daily, and the top 10 artists are extracted.
In top_artists.py, Top10Artists () [Sort and output the first 10 items]-> ʻAggrigateArtists ()[Aggregate the number of views by artist] -> The data flow is described asStreams ()` [daily log].
top_artists.py
class Top10Artists(luigi.Task):
"""
This task runs over the target data returned by :py:meth:`~/.AggregateArtists.output` or
:py:meth:`~/.AggregateArtistsHadoop.output` in case :py:attr:`~/.Top10Artists.use_hadoop` is set and
writes the result into its :py:meth:`~.Top10Artists.output` target (a file in local filesystem).
"""
date_interval = luigi.DateIntervalParameter()
use_hadoop = luigi.BoolParameter()
def requires(self):
"""
This task's dependencies:
* :py:class:`~.AggregateArtists` or
* :py:class:`~.AggregateArtistsHadoop` if :py:attr:`~/.Top10Artists.use_hadoop` is set.
:return: object (:py:class:`luigi.task.Task`)
"""
if self.use_hadoop:
return AggregateArtistsHadoop(self.date_interval)
else:
return AggregateArtists(self.date_interval)
def output(self):
"""
Returns the target output for this task.
In this case, a successful execution of this task will create a file on the local filesystem.
:return: the target output for this task.
:rtype: object (:py:class:`luigi.target.Target`)
"""
return luigi.LocalTarget("data/top_artists_%s.tsv" % self.date_interval)
def run(self):
top_10 = nlargest(10, self._input_iterator())
with self.output().open('w') as out_file:
for streams, artist in top_10:
out_line = '\t'.join([
str(self.date_interval.date_a),
str(self.date_interval.date_b),
artist,
str(streams)
])
out_file.write((out_line + '\n'))
def _input_iterator(self):
with self.input().open('r') as in_file:
for line in in_file:
artist, streams = line.strip().split()
yield int(streams), artist
The inside of each method can be written in ordinary Python. Therefore, it is possible to switch the dependency according to the parameter given from the outside, and to describe the dependency to multiple Tasks by using a list or dictionary.
In the example of top_artitsts.py, the task of ʻAggrigateArtists ()returns the daily log. By referring to multiple Tasks ofStreams ()` in the list, the daily data is aggregated for one month.
To execute it, enter the command as shown below.
python top_artists.py Top10Artists --date-interval 2015-03 --local-scheduler
Luigi Scheduler
The luigid command launches the scheduler. Even if a large number of tasks are received from multiple clients, they will be executed in order.
Also, if you access localhost: 8082 from your browser, you can visualize the progress of processing and dependencies.
To throw a Task to the scheduler, run it without the --local-scheduler option.
python top_artists.py Top10Artists --date-interval 2015-03
An example of visualizing the dependencies is shown below.
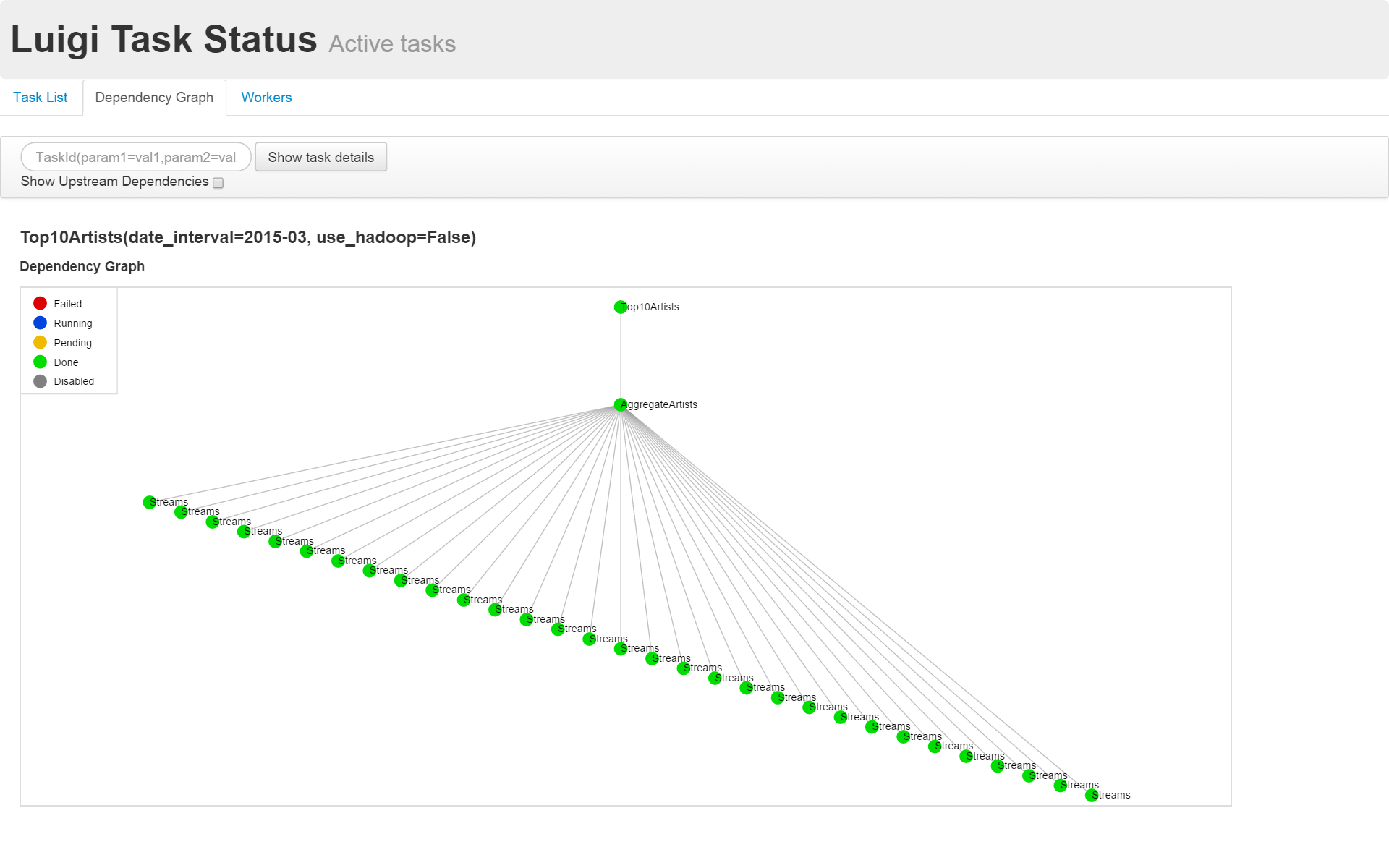
Usage example
I tried using Luigi for my Common Kanji Analysis Script. The place where the filter command written in Ruby is connected by the UNIX pipeline is intentionally connected by Luigi. It's a little over-implemented, but it's easier to check the operation because the intermediate file is surely left. Also, it's neat because you don't have to write it twice on the side that depends on the file name.
... I'm sorry, none of the above was big data.
Recommended Posts