A story that makes it easy to estimate the living area using Elasticsearch and Python
Overview
By registering the location information of the action history in Elasticsearch, I will talk about how it can be used in a nice way and also visualized in a nice way.
Prerequisite knowledge

I will use Elasticsearch this time, so I will briefly introduce it. Elasticsearch is one of the full-text search engines often compared to Apache Solr. It is schema-free and all inputs and outputs are REST & JSON. It is also implemented in Java.
--For details, Introduction and features of Elasticsearch
Installation is easy with yum or brew. Please check according to the environment you want to use. By the way, elasticsearch-head, which is a GUI plug-in of Elasticsearch, is convenient, so it is good to put it together.
Elasticsearch settings
After starting Elasticsearch, set the index (like a table in the database) to use. For that purpose, first create the index mapping method with json. This time, it is assumed that there is a log of the following data set.
sample_log
{
"id":1,
"uuid":"7ef82126c32c55f7272d5ca5dd5e40c6",
"time":"2015-12-03T04:21:01.641Z",
"lat":35.658546,
"lng":139.729281,
"accuracy":47.126048
}
Set the type for each field so that such a dataset can be mapped well. This time, I set the following mapping. It is an image that the mapping of the type of dataset called geo is set.
geo_mapping.json
{
"geo" : {
"properties" : {
"id" : {
"type" : "integer"
},
"uuid" : {
"type" : "string",
"index" : "not_analyzed"
},
"time" : {
"type" : "date",
"format" : "date_time"
},
"location" : {
"type" : "geo_point"
},
"accuracy" : {
"type" : "double"
}
}
}
}
To explain a little, the uuid field is set to `` `not_analyzed``` because it is a unique value and you do not want to morphologically analyze it. Also important this time is the type of the location field. geo_point is the type provided by Elasticsearch, and the longitude and latitude are registered as a set. You can use it by doing. By setting the type of this field, you can perform a convenient search. More on that later.
Once you have created the mapping settings, use it to create the index. The index name is test_geo this time. If you throw the following curl while Elasticsearch is running, the creation is completed.
Creating an index
curl -XPOST 'localhost:9200/test_geo' -d @geo_mapping.json
Data registration
Assuming that you have the data as a log file, register the data in the index created from the log file. There is an official python client this time, so let's use it.
--Official: [elasticsearch-py] (https://www.elastic.co/guide/en/elasticsearch/client/python-api/current/index.html)
It's easy to install with pip.
Installation
pip install elasticsearch
The program to be registered using this is as follows.
regist_es.py
import json
import sys
from elasticsearch import Elasticsearch
es = Elasticsearch()
index = "test_geo"
doc_type = "geo"
f = open('var/logs.json', 'r')
_line = f.readline()
while _line:
data = json.loads(_line)
_line = f.readline()
f.close()
for value in data:
lat = value['lat']
lon = value['lng']
del value['lat']
del value['lng']
value.update({
"location" : {
"lat" : lat,
"lon" : lon
}
})
es.index(index=index, doc_type=doc_type, body=value, id=value['id'])
The point to note is that `lat``` and lon``` are combined into ``` location``` in order to make it suitable for `` geo_point```. ..
If you execute this program, the action history information in logs.json will be registered in Elasticsearch. It's very easy.
Visualize with Kibana
Now that the data has been registered, it's time to boil or bake.
Kibana is an official visualization tool that visualizes the data registered in Elasticsearch.
Kibana4 is out now, so I think it's a good idea to get the latest version.
Once you get it, just run ./bin/kibana and the HTTP server will start on port 5601. Detailed setting method, etc..
After actually starting it, you can set the dashboard by accessing it with a suitable browser.
By playing around with it, you can easily create a heat map like the one below.
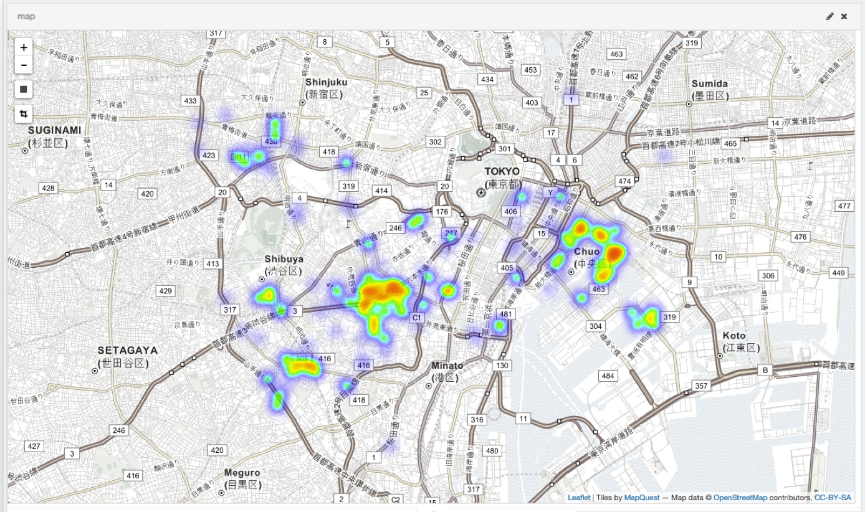

Living area estimation
Since I registered the data with much effort, I will try using it. This time, this paper (Information recommendation system using location information for mobile terminals) I will try to estimate the living area. Since the location information is registered with `` `geo_type```, the following query such as acquiring data within a few kilometers from a specific location can be thrown.
python
query = {
"from":0,
"query": {
"filtered" : {
"query" : {
"simple_query_string" : {
"query" : uuid,
"fields" : ["uuid"],
}
},
"filter" : {
"geo_distance" : {
"distance" : 10 + 'km',
"geo.location" : {
"lat" : lat,
"lon" : lon
}
}
}
}
}
}
The results of living area estimation using this are as follows.
Sample result
Stage1
35.653945 , 139.716692
radius(km): 5.90
Stage2
35.647367 , 139.709346
radius(km): 1.61
When using the center of gravity
35.691165 , 139.709840
radius(km): 8.22
Noon: (104)
35.696822 , 139.708228
radius(km): 9.61
Night: (97)
35.685100 , 139.711568
radius(km): 6.77
Nearest station(Noon):Higashi Shinjuku
Nearest station(Night):Shinjuku Gyoenmae
Impressions
Elasticsearch is very easy to set up and easy to use. Elasticsearch is amazing. Kibana is amazing. Moreover, there seems to be a new product (Beats). It depends on the amount of data, but it is convenient to register with Elasticsearch for the time being. Logs can be automatically registered with fluentd, so it seems that you can do various things by combining them.
_ Difficult to write articles ... _
Recommended Posts