"""
## 49.Extraction of dependency paths between nouns[Permalink](https://nlp100.github.io/ja/ch05.html#49-Extractionofdependencypathsbetweennouns)
Extract the shortest dependency path that connects all noun phrase pairs in a sentence. However, the clause numbers of the noun phrase pair are ii and jj (i)<ji<In the case of j), the dependency path shall satisfy the following specifications.
-As in question 48, the path describes the representation (surface morpheme sequence) of each clause from the start clause to the end clause.` -> `Express by connecting with
-Replace noun phrases in clauses ii and jj with X and Y, respectively.
In addition, the shape of the dependency path can be considered in the following two ways.
-When clause jj exists on the path from clause ii to the root of the syntax tree:Display the path of clause jj from clause ii
-Other than the above, when clause ii and clause jj intersect at a common clause kk on the route from the root of the syntax tree:The path immediately before the phrase ii to the phrase kk, the path immediately before the phrase jj to the phrase kk, and the contents of the phrase kk` | `Display by connecting with
Consider the example sentence "John McCarthy coined the term artificial intelligence at the first conference on AI." When CaboCha is used for the dependency analysis, the following output may be obtained.
'''
X is|About Y->the first->At a meeting|Created
X is|Y's->At a meeting|Created
X is|In Y|Created
X is|Called Y->Terminology|Created
X is|Y|Created
About X->Y's
About X->the first->In Y
About X->the first->At a meeting|Called Y->Terminology|Created
About X->the first->At a meeting|Y|Created
Of X->In Y
Of X->At a meeting|Called Y->Terminology|Created
Of X->At a meeting|Y|Created
In X|Called Y->Terminology|Created
In X|Y|Created
Called X->Y
'''
[Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(I), Morph(Is)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(here), Morph(so)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(start), Morph(hand)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Human), Morph(That)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(thing), Morph(To)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(You see), Morph(Ta), Morph(。)] )]
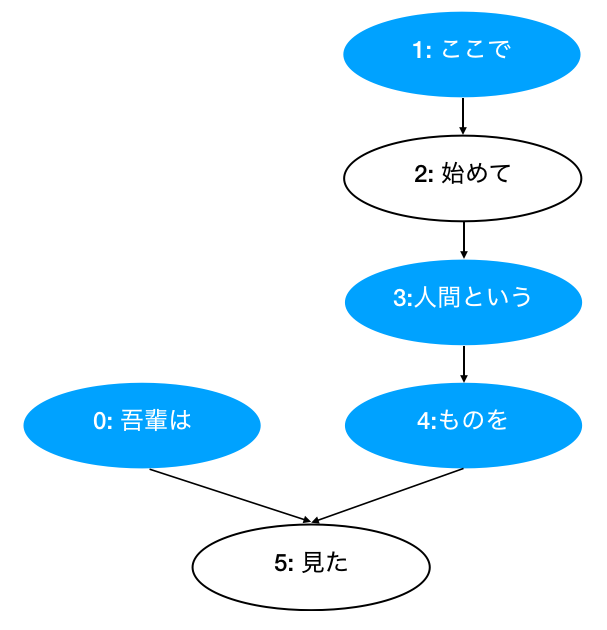
'''
Pattern 1 (Without root)
1 -> 3 -> 4
1 -> 3
1 -> 4
3 -> 4
Pattern 2 (With root):
From 0 to 1:
0 | 1 -> 3 -> 4 | 5
From 0 to 3:
0 | 3 -> 4 | 5
From 0 to 4:
0 | 4 | 5
'''
"""
from collections import defaultdict
from typing import List
def read_file(fpath: str) -> List[List[str]]:
"""Get clear format of parsed sentences.
Args:
fpath (str): File path.
Returns:
List[List[str]]: List of sentences, and each sentence contains a word list.
e.g. result[1]:
['* 0 2D 0/0 -0.764522',
'\u3000\t sign,Blank,*,*,*,*,\u3000,\u3000,\u3000',
'* 1 2D 0/1 -0.764522',
'I\t noun,Pronoun,General,*,*,*,I,Wagamama,Wagamama',
'Is\t particle,Particle,*,*,*,*,Is,C,Wow',
'* 2 -1D 0/2 0.000000',
'Cat\t noun,General,*,*,*,*,Cat,cat,cat',
'so\t auxiliary verb,*,*,*,Special,Continuous form,Is,De,De',
'is there\t auxiliary verb,*,*,*,Five steps, La line Al,Uninflected word,is there,Al,Al',
'。\t sign,Kuten,*,*,*,*,。,。,。']
"""
with open(fpath, mode="rt", encoding="utf-8") as f:
sentences = f.read().split("EOS\n")
return [sent.strip().split("\n") for sent in sentences if sent.strip() != ""]
class Morph:
"""Morph information for each token.
Args:
data (dict): A dictionary contains necessary information.
Attributes:
surface (str):Surface
base (str):Uninflected word (base)
pos (str):Part of speech (base)
pos1 (str):Part of speech subclassification 1 (pos1)
"""
def __init__(self, data):
self.surface = data["surface"]
self.base = data["base"]
self.pos = data["pos"]
self.pos1 = data["pos1"]
def __repr__(self):
return f"Morph({self.surface})"
def __str__(self):
return "surface[{}]\tbase[{}]\tpos[{}]\tpos1[{}]".format(
self.surface, self.base, self.pos, self.pos1
)
class Chunk:
"""Containing information for Clause/phrase.
Args:
data (dict): A dictionary contains necessary information.
Attributes:
chunk_id (int): The number of clause chunk (Phrase number).
morphs List[Morph]: Morph (morpheme) list.
dst (int): The index of dependency target (Contact clause index number).
srcs (List[str]): The index list of dependency source. (Original clause index number).
"""
def __init__(self, chunk_id, dst):
self.id = int(chunk_id)
self.morphs = []
self.dst = int(dst)
self.srcs = []
def __repr__(self):
return "Chunk( id: {}, dst: {}, srcs: {}, morphs: {} )".format(
self.id, self.dst, self.srcs, self.morphs
)
def get_surface(self) -> str:
"""Concatenate morph surfaces in a chink.
Args:
chunk (Chunk): e.g. Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(I), Morph(Is)]
Return:
e.g. 'I am'
"""
morphs = self.morphs
res = ""
for morph in morphs:
if morph.pos != "symbol":
res += morph.surface
return res
def validate_pos(self, pos: str) -> bool:
"""Return Ture if 'noun' or 'verb' in chunk's morphs. Otherwise, return False."""
morphs = self.morphs
return any([morph.pos == pos for morph in morphs])
def get_noun_masked_surface(self, mask: str) -> str:
"""Get masked surface.
Args:
mask (str): e.g. X or Y.
Returns:
str: 'I am' -> 'X is'
'Human' -> 'Called Y'
"""
morphs = self.morphs
res = ""
for morph in morphs:
if morph.pos == "noun":
res += mask
elif morph.pos != "symbol":
res += morph.surface
return res
def convert_sent_to_chunks(sent: List[str]) -> List[Morph]:
"""Extract word and convert to morph.
Args:
sent (List[str]): A sentence contains a word list.
e.g. sent:
['* 0 1D 0/1 0.000000',
'I\t noun,Pronoun,General,*,*,*,I,Wagamama,Wagamama',
'Is\t particle,Particle,*,*,*,*,Is,C,Wow',
'* 1 -1D 0/2 0.000000',
'Cat\t noun,General,*,*,*,*,Cat,cat,cat',
'so\t auxiliary verb,*,*,*,Special,Continuous form,Is,De,De',
'is there\t auxiliary verb,*,*,*,Five steps, La line Al,Uninflected word,is there,Al,Al',
'。\t sign,Kuten,*,*,*,*,。,。,。']
Parsing format:
e.g. "* 0 1D 0/1 0.000000"
|column|meaning|
| :----: | :----------------------------------------------------------- |
| 1 |The first column is`*`.. Indicates that this is a dependency analysis result.|
| 2 |Phrase number (integer starting from 0)|
| 3 |Contact number +`D` |
| 4 |Head/Function word positions and any number of feature sequences|
| 5 |Engagement score. In general, the larger the value, the easier it is to engage.|
Returns:
List[Chunk]: List of chunks.
"""
chunks = []
chunk = None
srcs = defaultdict(list)
for i, word in enumerate(sent):
if word[0] == "*":
# Add chunk to chunks
if chunk is not None:
chunks.append(chunk)
# eNw Chunk beggin
chunk_id = word.split(" ")[1]
dst = word.split(" ")[2].rstrip("D")
chunk = Chunk(chunk_id, dst)
srcs[dst].append(chunk_id) # Add target->source to mapping list
else: # Add Morch to chunk.morphs
features = word.split(",")
dic = {
"surface": features[0].split("\t")[0],
"base": features[6],
"pos": features[0].split("\t")[1],
"pos1": features[1],
}
chunk.morphs.append(Morph(dic))
if i == len(sent) - 1: # Add the last chunk
chunks.append(chunk)
# Add srcs to each chunk
for chunk in chunks:
chunk.srcs = list(srcs[chunk.id])
return chunks
class Sentence:
"""A sentence contains a list of chunks.
e.g. [Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(I), Morph(Is)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(here), Morph(so)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(start), Morph(hand)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Human), Morph(That)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(thing), Morph(To)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(You see), Morph(Ta), Morph(。)] )]
"""
def __init__(self, chunks):
self.chunks = chunks
self.root = None
def __repr__(self):
message = f"""Sentence:
{self.chunks}"""
return message
def get_root_chunk(self):
chunks = self.chunks
for chunk in chunks:
if chunk.dst == -1:
return chunk
def get_noun_path_to_root(self, src_chunk: Chunk) -> List[Chunk]:
"""Get path from noun Chunk to root Chunk.
e.g. [Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(I), Morph(Is)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(here), Morph(so)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(start), Morph(hand)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Human), Morph(That)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(thing), Morph(To)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(You see), Morph(Ta), Morph(。)] )]
Args:
src_chunk (Chunk): A Chunk. e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(here), Morph(so)] ),
Returns:
List[Chunk]: The path from a chunk to root.
The path from 'here' to 'saw': here ->Human->Things-> saw
So we should get: ['here', 'Human', 'Things', 'saw']
"""
chunks = self.chunks
path = [src_chunk]
dst = src_chunk.dst
while dst != -1:
dst_chunk = chunks[dst]
if dst_chunk.validate_pos("noun") and dst_chunk.dst != -1:
path.append(dst_chunk)
dst = chunks[dst].dst
return path
def get_path_between_nouns(self, src_chunk: Chunk, dst_chunk: Chunk) -> List[Chunk]:
"""[summary]

Example:
[Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(I), Morph(Is)] ),
Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(here), Morph(so)] ),
Chunk( id: 2, dst: 3, srcs: ['1'], morphs: [Morph(start), Morph(hand)] ),
Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Human), Morph(That)] ),
Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(thing), Morph(To)] ),
Chunk( id: 5, dst: -1, srcs: ['0', '4'], morphs: [Morph(You see), Morph(Ta), Morph(。)] )]
Two patterns:
Pattern 1 (Without root): save as a list.
1 -> 3 -> 4
1 -> 3
1 -> 4
3 -> 4
Pattern 2 (With root): save as a dict.
From 0 to 1:
0 | 1 -> 3 -> 4 | 5
From 0 to 3:
0 | 3 -> 4 | 5
From 0 to 4:
0 | 4 | 5
Pattern 1:
src_chunk (Chunk): e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(here), Morph(so)] ),
dst_chunk (Chunk): e.g. Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(thing), Morph(To)] )
Path:
From 'here' to 'Things': here ->Human-> Things
Returns:
List[Chunk]: [Chunk(Human)]
Pattern 2:
src_chunk (Chunk): e.g. Chunk( id: 0, dst: 5, srcs: [], morphs: [Morph(I), Morph(Is)] ),
dst_chunk (Chunk): e.g. Chunk( id: 3, dst: 4, srcs: ['2'], morphs: [Morph(Human), Morph(That)] )
Path:
From Chunk(I am) to Chunk(Human):
0 | 3 -> 4 | 5
- Chunk(I am) -> Chunk(saw)
- Chunk(Human) -> Chunk(Things) -> Chunk(saw)
Returns:
Dict: {'src_to_root': [Chunk(I am)],
'dst_to_root': [Chunk(Human), Chunk(Things)]}
"""
chunks = self.chunks
pattern1 = []
pattern2 = {"src_to_root": [], "dst_to_root": []}
if src_chunk.dst == dst_chunk.id:
return pattern1
current_src_chunk = chunks[src_chunk.dst]
while current_src_chunk.dst != dst_chunk.id:
# Pattern 1
if current_src_chunk.validate_pos("noun"):
pattern1.append(src_chunk)
# Pattern 2
if current_src_chunk.dst == -1:
pattern2["src_to_root"] = self.get_noun_path_to_root(src_chunk)
pattern2["dst_to_root"] = self.get_noun_path_to_root(dst_chunk)
return pattern2
current_src_chunk = chunks[current_src_chunk.dst]
return pattern1
def write_to_file(sents: List[dict], path: str) -> None:
"""Write to file.
Args:
sents ([type]):
e.g. [[['I am', 'Be a cat']],
[['Name is', 'No']],
[['where', 'Was born', 'Do not use'], ['I have a clue', 'Do not use']]]
"""
# convert_frame_to_text
lines = []
for sent in sents:
for chunk in sent:
lines.append(" -> ".join(chunk))
# write_to_file
with open(path, "w") as f:
for line in lines:
f.write(f"{line}\n")
def get_pattern1_text(src_chunk, path_chunks, dst_chunk):
"""
Pattern 1:
src_chunk (Chunk): e.g. Chunk( id: 1, dst: 2, srcs: [], morphs: [Morph(here), Morph(so)] ),
dst_chunk (Chunk): e.g. Chunk( id: 4, dst: 5, srcs: ['3'], morphs: [Morph(thing), Morph(To)] )
Path:
From 'here' to 'Things': here ->Human-> Things
path_chunks:
List[Chunk]: [Chunk(Human)]
"""
path = []
path.append(src_chunk.get_noun_masked_surface("X"))
for path_chunk in path_chunks:
path.append(path_chunk.get_surface())
path.append(dst_chunk.get_noun_masked_surface("Y"))
return " -> ".join(path)
def get_pattern2_text(path_chunks, sent):
"""
Path:
From Chunk(I am) to Chunk(Human):
0 | 3 -> 4 | 5
- Chunk(I am) -> Chunk(saw)
- Chunk(Human) -> Chunk(Things) -> Chunk(saw)
path_chunks:
Dict: {'src_to_root': [Chunk(I am)],
'dst_to_root': [Chunk(Human), Chunk(Things)]}
"""
path_text = "{} | {} | {}"
src_path = []
for i, chunk in enumerate(path_chunks["src_to_root"]):
if i == 0:
src_path.append(chunk.get_noun_masked_surface("X"))
else:
src_path.append(chunk.get_surface())
src_text = " -> ".join(src_path)
dst_path = []
for i, chunk in enumerate(path_chunks["dst_to_root"]):
if i == 0:
dst_path.append(chunk.get_noun_masked_surface("Y"))
else:
dst_path.append(chunk.get_surface())
dst_text = " -> ".join(dst_path)
root_chunk = sent.get_root_chunk()
root_text = root_chunk.get_surface()
return path_text.format(src_text, dst_text, root_text)
def get_paths(sent_chunks: List[Sentence]):
paths = []
for sent_chunk in sent_chunks:
sent = Sentence(sent_chunk)
chunks = sent.chunks
for i, src_chunk in enumerate(chunks):
if src_chunk.validate_pos("noun") and i + 1 < len(chunks):
for j, dst_chunk in enumerate(chunks[i + 1 :]):
if dst_chunk.validate_pos("noun"):
path_chunks = sent.get_path_between_nouns(src_chunk, dst_chunk)
if isinstance(path_chunks, list): # Pattern 1
paths.append(
get_pattern1_text(src_chunk, path_chunks, dst_chunk)
)
if isinstance(path_chunks, dict): # Pattern 2
paths.append(get_pattern2_text(path_chunks, sent))
return paths
fpath = "neko.txt.cabocha"
sentences = read_file(fpath)
sent_chunks = [convert_sent_to_chunks(sent) for sent in sentences] # ans41
# ans49
paths = get_paths(sent_chunks)
for p in paths[:20]:
print(p)
#X is|In Y->Human->Things|saw
#X is|Called Y->Things|saw
#X is|Y|saw
#In X->Called Y
#In X->Y
#Called X->Y
Recommended Posts