What is a Convolutional Neural Network?
In the world of machine learning, the Convolutional Neural Network (CNN) is recognized as a matter of course when it comes to images, and when it comes to udon, it is as common as Kagawa. However, there are surprisingly few explanations about what that CNN is.
Therefore, in this article, I would like to explain the mechanism and merits of CNN.
As described in the references, the content of the explanation is based on Stanford's CNN course. This course will explain from Neural Network to CNN to implementation by Tensorflow, so if you are interested, please refer to that as well.
What is Convolutional Neural Network?
As the name implies, CNN is a normal Neural Network with Convolution added. Here, I will explain what Convolution and convolution are all about, and why they are effective for image recognition.
As a simple task, consider the task of determining whether the written figure is ○ or ×. The following is an example of using a normal Neural Network.

Imagine that one pixel in the image corresponds to one input. For a 10x10 image, the input will be a vector of size 100 (note that in RGB representation it will be x3 here).
In the figure, the black part of the edge of the circle is shown as input, but if you look at this, you can see that if the position is slightly off, the judgment will be greatly affected. This is because if the position or shape changes slightly as shown in the figure below, the input information will also be misaligned and recognized.
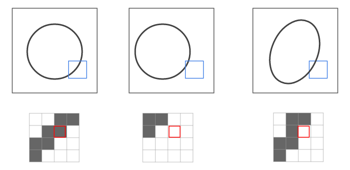
However, the inside of the blue square in the figure tends to be "black from the upper right to the lower left". In other words, it seems that more accurate judgment can be made if the area of a certain size can be input collectively instead of 1 pixel.
CNN is the realization of this idea.
As shown in the figure below, a small area called a filter (4x4 area with a red frame in the figure below) is taken on the image, and this is compressed (= convolved) as one feature.

This process is repeated while sliding the area. The result is a Convolution Layer, a layer created by convolving the information in the filter.

If you change the Neural Network diagram to CNN, you will get the following image.

The process of "convolution" using this filter is specifically the multiplication and inner product between the "vector of the image in the filter" and the "vector used for convolution". In the following, a 5x5x3 filter is applied to a 32x32x3 image (32x32 RGB image).
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p13
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p13
This will eventually create a 28x28x1 layer (if the slide width is 1).
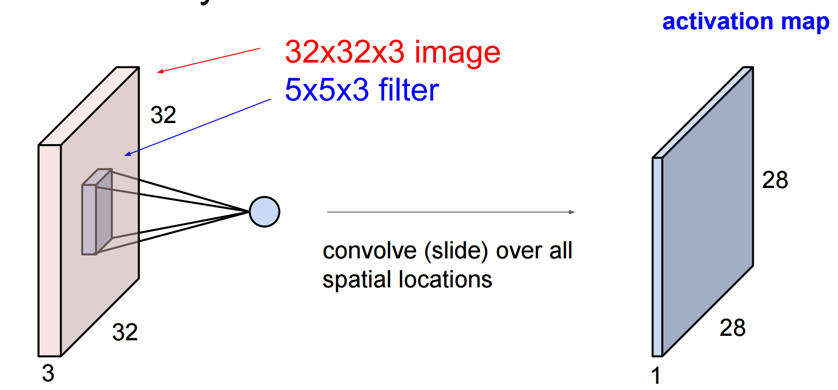 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p14
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p14
And if you increase the types of filters, the Convolution Layer will increase accordingly. Below, 6 layers are created with 6 filters.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p16
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p16
It can be said that this is just creating a "new image" by convolution. Like a normal Neural Network, the convolutional layer created in this way is connected by an activation function to form a Convolutional Neural Network (ReLU is often used as the activation function).
I will summarize the story so far.
- CNN is a Neural Network that introduces a Convolution Layer that is created by convolving information on the area inside the filter.
- Convolution Layer is created by applying while moving the filter, and as many as the number of filters are created. A network is constructed by stacking these and connecting them with an activation function (ReLU, etc.).
- Convolution makes it possible to extract features based on areas rather than points, making it robust to image movement and deformation. In addition, it is possible to extract features such as edges that can only be known on an area basis.
This CNN is characterized by filter settings and layering.
Filter settings
The following four parameters must be set for the filter used for convolution.
- Number of filters (K): The number of filters to use. Approximately a power of 2 is taken (32, 64, 128 ...)
- Filter size (F): The size of the filter used
- Filter movement width (S): Width to move the filter
- Padding (P): How much to fill the edge area of the image
Padding is the process of filling the edge area of the image with 0 as shown below.
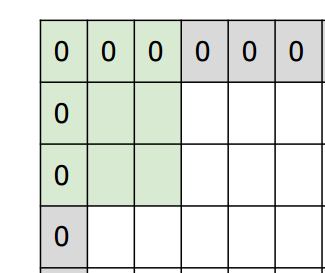 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p35
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p35
The reason for doing this is that normal convolution reduces the number of convolutions in the edge area compared to other areas. By filling the edges of the image with 0s in this way and filtering from there, the edges will be reflected in the same way as other areas.
In addition, it is necessary to adjust the size and movement width of the filter so that it fits the size of the image properly. Please note that you cannot set the size and movement width of the filter that extends beyond the image as shown below.

From the values of these parameters, it is possible to calculate the size of the Convolutional Layer. Suppose you want to apply a 5x5x3 filter to a 32x32x3 image with a movement width of 1 and padding of 2. First, when padding is added, the size of the image is 32 + 2 * 2 = 36. If you take a filter with a width of 5 from here with a movement width of 1, it will be 32 with 36-5 + 1. So you end up with a 32x32x3 layer.
These parameters also need to be set when using a library such as Caffe, so it's a good idea to keep in mind what they mean and how to calculate their size.
Layer structure
There are three types of layers in CNN, including Convolutional Layer.
- Convolutional Layer: A layer that convolves features
- Pooling Layer: A layer to reduce the layer and make it easier to handle
- Fully Connected Layer: The layer that makes the final judgment from the features
The image is as follows.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p22
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p22
I will explain about layers other than Convolutional Layer. The first is the Pooling Layer, which is the layer that compresses the image. It has the advantage of compressing the image size and making it easier to handle in later layers.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p54
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p54
There is Max Pooling as a means to do this pooling. This is a method of compressing by taking the maximum value in each area.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p55
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p55
A Fully Connected Layer is a layer that connects all the elements of the previous layer. It is mainly used in the layer that makes the final judgment. By combining these layers, we will build a CNN.
Evolution of CNN
The accuracy of CNN has improved over the years, but recent configurations have the following characteristics.
- Make the filter smaller and deeper the hierarchy
- Eliminate Pooling and FC layers
In the figure below, you can see that the layer gets deeper as the accuracy increases year by year.
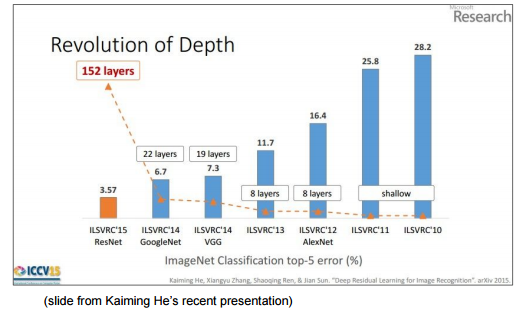 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p78
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p78
Regarding the depth of the layer, the following may be easier to understand. Compared to AlexNet's 8 layers that appeared in 2012, ResNet, which won the crown in 2015, has increased significantly to 152 layers.
 CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p80
CS231n: Convolutional Neural Networks for Visual Recognition, Lecture7, p80
It seems that there are many of the following patterns as the basic configuration of CNN.
(Convolution * N + (Pooling)) * M + Fully Connected * K
** N ** is about ~ 5, and ** M ** layers are layered (M is a fairly large value), and finally FC for judgment is ** K ** layer (0 <= K <=). 2) It's like setting up (I sometimes add a layer using the SoftMax function to handle the classification problem). ReLU is often used as the activation function.
CNN seems to be very complicated, but since the basics of Neural Network that propagates with weight are not removed, it is possible to train by Backpropagation like Neural Network. I think the flexibility around here is also the appeal of Neural Networks.
CNN application example
CNN has been applied to other tasks as well as the original images. This application is very well organized in the slides below, so if you're interested, take a look.
Convolutional Neural Networks Trends
In other words, a CNN that can identify an image can capture the characteristics of the image well. In other words, a CNN that has been stripped of the identification layer can be seen as the process of transforming an input image into a vector that represents its features (distinguishably) well. Some of the application examples utilize this feature, and especially the application example of adding a caption to the image combines the feature amount of the image extracted from CNN and the text information.
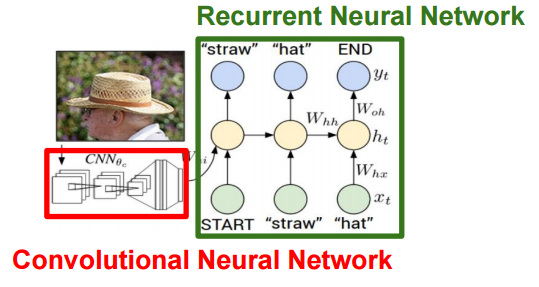
I think that various application examples will come out in the future, and if you use the recent machine learning framework, you can try it yourself. I hope this article will help you.
References
Recommended Posts