[JAVA] Introduction to Apache Beam (2) ~ ParDo ~
Overall purpose
Create a simple Apache Beam program to understand how it works
Previous content
I wrote the read text as it is to confirm the startup. Introduction to Apache Beam (1) ~ Text reading and writing ~
Purpose of this time
Change the data type by performing ParDo processing for each line of read text Specifically, the process of "reading Bitcoin ticker information from text data and extracting an arbitrary value from it" is performed.
What is ParDo in the first place?
Core Beam Transforms Beam provides the following 6 as basic data variants (like a general outline of processing)
- ParDo (I'll do this time)
- GroupByKey
- CoGroupByKey
- Combine
- Flatten
- Partition
One of these is ParDo
What kind of processing?
- Responsible for the Map part of the MapReduce algorithm
- Process the PCollection received as input
- Output 0 or 1 or more PCollections
In short, the process of processing the input data (1 piece) and outputting it (regardless of the number)
Main story
environment
Same as last time
IntelliJ
IntelliJ IDEA 2017.3.3 (Ultimate Edition)
Build #IU-173.4301.25, built on January 16, 2018
Licensed to kaito iwatsuki
Subscription is active until January 24, 2019
For educational use only.
JRE: 1.8.0_152-release-1024-b11 x86_64
JVM: OpenJDK 64-Bit Server VM by JetBrains s.r.o
Mac OS X 10.12.6
Maven : 3.5.2
procedure
Text data to use
The data used is as follows It is the data for 10 times that the rate information of BTC / JPY in bitflyer is acquired every 10 seconds.
The order is <trade symbol>, <exchange name>, <timestamp>, <ASK>, <BID>.
Sample.txt
BTC/JPY,bitflyer,1519845731987,1127174.0,1126166.0
BTC/JPY,bitflyer,1519845742363,1127470.0,1126176.0
BTC/JPY,bitflyer,1519845752427,1127601.0,1126227.0
BTC/JPY,bitflyer,1519845762038,1127591.0,1126316.0
BTC/JPY,bitflyer,1519845772637,1127801.0,1126368.0
BTC/JPY,bitflyer,1519845782073,1126990.0,1126411.0
BTC/JPY,bitflyer,1519845792827,1127990.0,1126457.0
BTC/JPY,bitflyer,1519845802008,1127980.0,1126500.0
BTC/JPY,bitflyer,1519845812088,1127980.0,1126566.0
BTC/JPY,bitflyer,1519845822743,1127970.0,1126601.0
Read this text and use ParDo to extract arbitrary information (BID this time) from each line.
Code change
The code this time is as follows.
SimpleBeam.java
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.DoFn;
import org.apache.beam.sdk.transforms.ParDo;
import org.apache.beam.sdk.values.PCollection;
public class SimpleBeam {
//add to
public static class ExtractBid extends DoFn<String, String> {
@ProcessElement
public void process(ProcessContext c){
//Get row
String row = c.element();
//Split with commas
String[] cells = row.split(",");
//Returns BID
c.output(cells[4]);
}
}
public static void main(String[] args){
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
//Read text
PCollection<String> textData = p.apply(TextIO.read().from("Sample.txt"));
//Added from here
PCollection<String> BidData = textData.apply(ParDo.of(new ExtractBid()));
//Add up to here
//Text writing
BidData.apply(TextIO.write().to("output/bid"));
//Pipeline run
p.run().waitUntilFinish();
}
}
The output of the previous code was "word count" and I knew that I copied and pasted the sample, so I changed the output destination. .. ..
The execution method is the same as last time, so please refer to here.
Execution result
The execution result is as follows, and you can see that the BID data (the rightmost side of Sample.txt) can be extracted.
This time, for the sake of simplicity, only one String is extracted, but this allows you to change the data type and format the data.
With this kind of processing, you can set an arbitrary Key to the input data and move to the Reduce processing.
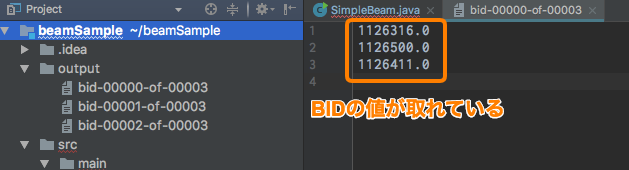
Is the output divided into three files like the image because the Map process is completed and then Reduce is distributed and executed?
About SimpleFunction
A class called SimpleFinction is prepared to realize the same processing, and I was curious about what was different, so I will summarize it as a bonus.
According to the Official Documentation,
If your ParDo performs a one-to-one mapping of input elements to output elements–that is, for each input element, it applies a function that produces exactly one output element, you can use the higher-level MapElements transform. MapElements can accept an anonymous Java 8 lambda function for additional brevity.
It seems like a story that you can describe processing more abstractly and easily than DoFn of ParDo using anonymous functions.
Try rewriting using Simple Function
code
beamSample.java
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.options.PipelineOptions;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.MapElements;
import org.apache.beam.sdk.values.PCollection;
import org.apache.beam.sdk.values.TypeDescriptors;
public class SimpleBeam {
public static void main(String[] args){
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
//Read text
PCollection<String> textData = p.apply(TextIO.read().from("Sample.txt"));
//Implement the same process using anonymous functions
PCollection<String> BidData = textData.apply(
MapElements.into(TypeDescriptors.strings())
.via((String row) -> row.split(",")[4])
);
//Text writing
BidData.apply(TextIO.write().to("output/bid"));
//Pipeline run
p.run().waitUntilFinish();
}
}
It's much simpler!
As for the impression that I touched Beam for a while, it is quite troublesome to create DoFn each time because the process of simply changing the data type matches, so I would like to actively use it.
In other words
Java 8 cannot be enabled
Normal change method File => Project Structure...
ProjectSettings => Project => Set Project language level to 8
** Still does not pass ... In such a case, follow the steps below **
solution
Added the following description to pom.xml
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>beamSample</groupId>
<artifactId>beamSample</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 1.Added to make 8 recognized-->
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<!--Add up to here-->
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-core</artifactId>
<version>2.4.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-runners-direct-java</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
</project>
from next time
This time, I implemented ParDo which is equivalent to Map processing of MapReduce. Next time, I would like to easily implement Reduce processing and find the average of ticker information.
Recommended Posts